一.下载jdk并配置
地址:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
版本:jdk1.8.0_191
上传至目录:
/usr/local
然后 cd 进入上述目录
解压上传的压缩包:
tar -zxvf jdk-8u191-linux-x64.tar.gz
使用"vim /etc/profile"进入profile文件按“i”进入插入模式,在文件的最后添加如下信息:
export JAVA_HOME=/usr/local/jdk1.8.0_191
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
配置立即生效:
. /etc/profile
验证配置是否生效:
java -version

二.Hadoop下载与配置
1.将下载的 hadoop-2.7.0.tar.gz 上传到/home/hadoop 目录下
2.解压上述文件
tar -zxvf hadoop-2.7..0.tar.gz
3.重命名mv hadoop-2.7.0 hadoop2.7
4.vim /etc/profile(配置hadoop的环境变量)
输入如下信息:
export HADOOP_HOME=/home/hadoop/hadoop2.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后输入如下命令保存生效:
source /etc/profile
5.验证
输入hadoop,出现以下配置则成功
6.修改/home/hadoop/hadoop2.7/etc/hadoop目录下hadoop-env.sh
输入命令(在修改之前要先知道本机ip,可以使用ifconfig进行查看)
vim hadoop-env.sh
修改 hadoop-env.sh 的 JAVA_HOME 值
export JAVA_HOME=/usr/local/jdk1.8.0_191
7.修改/home/hadoop/hadoop2.7/etc/hadoop目录下的core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.5.100:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
8.修改/home/hadoop/hadoop2.7/etc/hadoop目录下的hdfs-site.xml
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>192.168.5.100:50070</value>
</property>
</configuration>
9.到此我们便配置完成一个 hdfs 伪分布式环境
启动 hdfs Single Node
①、初始化 hdfs 文件系统
bin/hdfs namenode -format
②、启动 hdfs
sbin/start-dfs.sh
如果启动过程出现以下错误:
Starting namenodes on [192.168.5.100]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [localhost.localdomain]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
解决方案:
1.在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2.还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
3.修改后重启 ./start-dfs.sh,成功!
③、输入 jps 应该会有如下信息显示,则启动成功
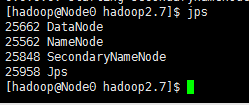
访问以下http://192.168.5.100:50070,出现以下界面:
关注公众号,获取更多资源

每天进步一点点,开心也多一点点
