写在前面:
服务器上的配置与虚拟机有所不同,由于服务器有外网和内网的区别,故/etc/hosts需要作改动,改动如下:
ifconfig命令查看ip,发现与外网的ip(106.15.224.113)不同
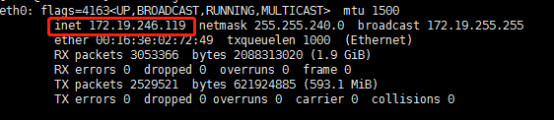
用命令vim /etc/hosts进行以下修改:
106.15.224.113 localhost
172.19.246.119 Centos6

前面这些基本的弄好之后,我们就可以正式开始了
一.用pycharm编辑python代码
hdfs_map.py
import sys
# 将文件内容分隔
def read_input(file):
for line in file:
yield line.split()
def main():
data=read_input(sys.stdin)
for words in data:
for word in words:
print("%s%s%d"%(word,'\t',1))
if __name__=='__main__':
main()
hdfs_reduce.py
import sys
from operator import itemgetter
from itertools import groupby
def read_mapper_output(file,separator='\t'):
for line in file:
yield line.rstrip().split(separator,1)
def main():
data=read_mapper_output(sys.stdin)
for current_word,group in groupby(data,itemgetter(0)):
total_count=sum(int(count) for current_word,count in group)
print('%s%s%d'%(current_word,'\t',total_count))
if __name__=='__main__':
main()
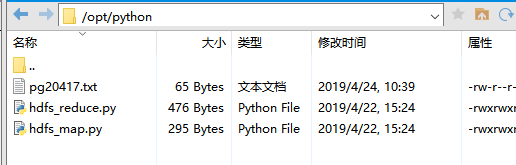
二.将代码上传至服务器上,创建目录/opt/python并放置在该目录下
在该目录下下载一本书
wget http://www.gutenberg.org/ebooks/20417.txt.utf-8
权限修改
chmod 777 /opt/python/hdfs_map.py
chmod 777 /opt/python/hdfs_reduce.py
centos上的文件目录
三.运行hadoop
在你安装的hadoop的sbin目录下运行如下命令:
./start-all.sh
查看启动情况
jps
验证程序能否跑
echo "a b c"|python3 /opt/python/hdfs_map.py

echo “a a b d c b c c c”|python3 /opt/python/hdfs_map.py |sort -k1,1|python3 /opt/python/hdfs_reduce.py

四.在真正的hadoop上运行Python程序
创建需要的目录
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/input
上传本地文件至hadoop目录中
hdfs dfs -put /opt/python/pg20417.txt /user/input
在hadoop上运行python程序
/home/hadoop/hadoop3.2/bin/hadoop jar /home/hadoop/hadoop3.2/share/hadoop/tools/lib/hadoop-streaming-3.2.0.jar -files “/opt/python/hdfs_map.py,/opt/python/hdfs_reduce.py” -input /user/input/*.txt -output /user/output -mapper “/root/Py37/bin/python3 /opt/python/hdfs_map.py” -reducer “/root/Py37/bin/python3 /opt/python/hdfs_reduce.py”
运行成功的效果图

查看output里面文件的情况
hdfs dfs -ls /user/output

后面那个文件是我们需要的文件,我们查看一下里面的内容
hdfs dfs -cat /user/output/part-00000

关注公众号,获取更多资源

每天进步一点点,开心也多一点点
