在实际应用中,有时候数据不是很多,可以用数据增强方式
扩展数据,在小的数据集上效果比较明显。
语音数据增强主要有以下几种方式:
音速扰动sp
utils/data/perturb_data_dir_speed_3way.sh
音量扰动vp
utils/data/perturb_data_dir_volume.sh
kaldi里面数据增强脚本是存放在utils/data 目录下。
加上去年谷歌提出新型自动语音识别SpecAugment数据增强方式
SpenAugment参考了图像的做法,SpenAugment方法直接增强了频谱图,而不再是音波数据上。这种方法的数据增强是直接使用在输入特征上的,可以实时动态添加,而不需要像对音波进行数据增强一样有很多计算代价而影响到训练速度。
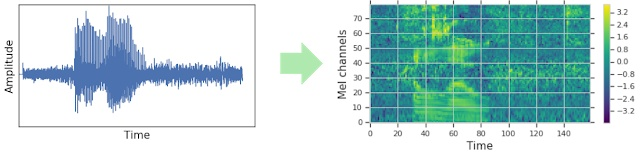
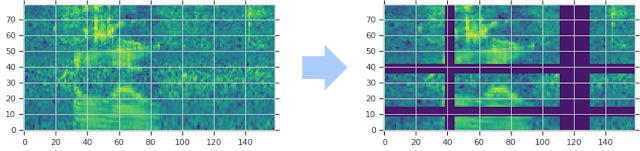
采用扭曲时域信号,掩盖频域通道,和掩盖时域通道,修改了频谱图。
在kaldi里面已经有将SpenAugment集成进去,在network.xconfig中增加
spec-augment-layer name=spec-augment freq-max-proportion=0.5 time-zeroed-proportion=0.2 time-mask-max-frames=20
delta-layer name=delta input=spec-augment即可。
我尝试用SpecAugment数据增强方式训练模型,在minilibirispeech上训练,WER降低了两个点左右,还是有提升。我在300多个小时的英语数据集合上用了6个epochs并没有发现有提升,可能还要加大epochs,由于增加epochs会增加训练时间,我并没有继续实验下去。看到danpovey在论坛中讨论说libirispeech上并没有复现出来,
谷歌可能是在TPU上训练几百个epochs实验出来的。
