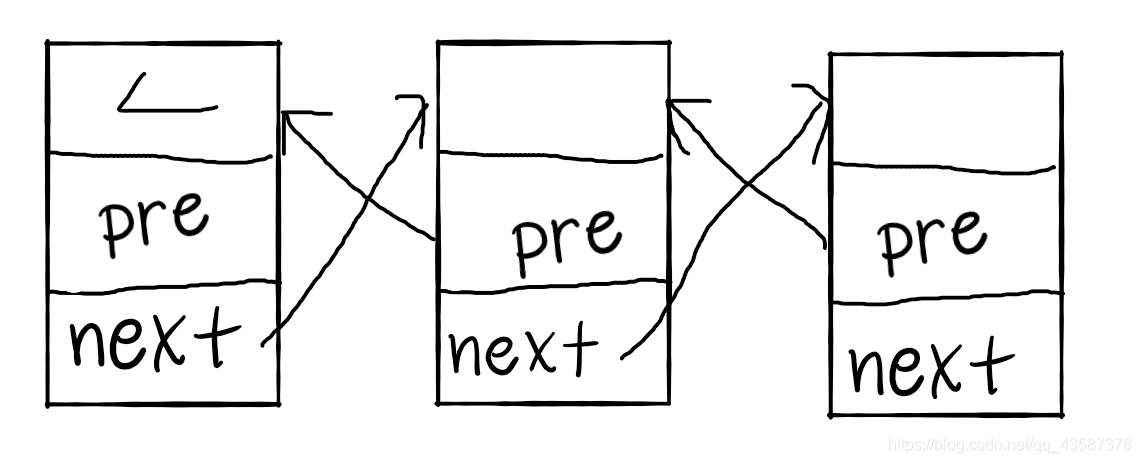
先给一个节点类,属性有:节点值(我用的int类型数值为例),前节点,后节点。前节点主要功能是便于不用遍历的方式寻找前节点,以免多次遍历造成时间复杂度的增长。
public class Node {
int value;
Node next;
Node pre;
}
提供一个构造方法,去建立链表头
public Node(int value) {
this.value = value;
}
提供两种add方式,方便不同的情况插入
public Node add(int value) {
Node node = new Node(value);
return add(node);
}
//对于直接插入节点,要注意前后节点的更改
public Node add(Node node) {
next = node;
node.pre = this;
return next;
}
重写toString方法,方便查看节点值
@Override
public String toString() {
if (this.next == null) {
return ""+value;
}
return value+"-->"+this.next.toString();
}
开始写LRU(最大缓存区为100)
class LRU {
//头节点
Node node;
int sizeMax = 100;
int size = 0;
//尾节点指针(不是实时的,有时需要方法调用来寻找最新的尾节点)
Node lastNode;
//构造方法,建立链表头
public LRU(int value) {
node = new Node(value);
lastNode = node;
this.size++;
}
//寻找尾节点的方法,从已有尾节点开始往后寻找
void lastNode() {
Node node = this.lastNode;
while (node.next != null) {
node = node.next;
}
lastNode= node;
}
//检查值为value的节点值是否存在
Node valueCheck(int value) {
Node x = this.node;
do {
if (x.value == value) {
return x;
}
x = x.next;
} while (x != null);
return null;
}
//添加操作,
//遍历链表,判断待添加的数据时候已经存在
//存在: 删除该节点,然后在头节点添加。
//不存在:
// 1. 缓存没满:在头节点添加
// 2. 缓存满了,删除最后一个节点,然后在头节点添加
void add(int value) {
Node valueCheck = valueCheck(value);
//如果valueCheck不是空的话,说明value存在,删除该节点,
if (valueCheck != null) {
delete(valueCheck);
} else {
//否则的话,就建立值为value的Node
valueCheck = new Node(value);
}
//判断是否超出缓存大小
if (size >= sizeMax) {
lastNode();
delete(lastNode);
}
//因为是头节点添加所以是valueCheck添加node,再将valueCheck赋值给node,
//并将头节点的前节点置为null
valueCheck.add(this.node);
this.node = valueCheck;
this.node.pre = null;
//最后将size+1
this.size++;
}
//删除节点,因为该方法是类体自己调用的,所以不需要判断是否存在(因为只有存在才调用)
private void delete(Node node) {
//先将缓存数减一
this.size--;
//将尾节点指针放到尾节点上
lastNode();
if (node == lastNode) {
//如果是尾节点,那么只需要将尾节点指针前移
//这一步只是为了移动尾节点指针
lastNode = lastNode.pre;
}
if (node.pre == null) {
//如果是头节点,那么只需要将头节点指针后移,并将前节点置为null
node.next.pre = null;
this.node = node.next;
return;
} else if (node.next == null) {
////如果是尾节点,那么只需要将尾节点前指针的后节点置为null
node.pre.next = null;
return;
}
//如果是中间节点的话,就正常断前后链
node.pre.next = node.next;
node.next.pre = node.pre;
}
//删除某个节点值为value的节点
void delete(int value) {
//先检查是否存在
Node valueCheck = valueCheck(value);
if (valueCheck == null) {
//如果不存在就退出
return;
}
//存在的的话就删除
delete(valueCheck);
}
//寻找某个节点值为value的节点
void find(int value) {
Node valueCheck = valueCheck(value);
if (valueCheck != null) {
delete(valueCheck);
valueCheck.add(node);
node = valueCheck;
node.pre = null;
}
}
//重写toString方法,直接用Node写好的toString就可以
@Override
public String toString() {
return "node=" + node;
}
}
基本基于双链表的LRU就是实现了,主要就是对LRU的认识,LRU就是把最近用的放到最前面,最不常用的放在最后,等到因为缓存慢需要删除的时候,优先删除最后一个节点。
