一、简介
这不是一个微服务项目哦!不知道如何起名,只好滥用它了。
“微服务架构有一条重要规则:每个微服务必须拥有领域逻辑和数据。与完整的应用有逻辑和数据类似,在自治的生命周期内,微服务也有自己的逻辑和数据,并可针对每个微服务独立部署。”
本项目中所有的服务共用一个关系型数据库,也没有领域驱动设计,所以它不能算是一个微服务项目,但作为一个开发人员遇到的绝大部分的项目都是重复造轮子,能遇到一个项目,它包含多个服务且已正式上线,这也勉强算是一次不错的经历吧。
本文将一个传统的单体应用重构成一个现代化的多服务的云端应用,以及使用微服务化的思想来解决问题。将一个已有的大单体应用,经过少量的重构后拆分成多个服务,每个服务都能独立地开发、部署和扩展,它们将部署到谷歌的GCP云上,最终作为了一个整体为应用程序提供服务。有以下几点好处:
(1) 可维护性: 此种架构提供了长期敏捷性,这些服务通常拥有细粒度和独立生命周期等特征,这使得复杂的、大型的以及高度扩展的系统,拥有更好的可维护性;
(2)节约成本:每个服务都能独立进行横向扩展,这样就能只扩展真正需要更多处理资源或网络带宽的功能,而不是一起将本不需要扩展的 其他功能区域也进行扩展。因为使用的硬件更少,这也意味着可以节约成本。
二、单体应用
本是一个单体应用, 采用前后端分离的方式,前端使用angular框架,后端采用Nodejs+Mysql,这部分相对简单,不是本文的重点。具体的架构图如下:
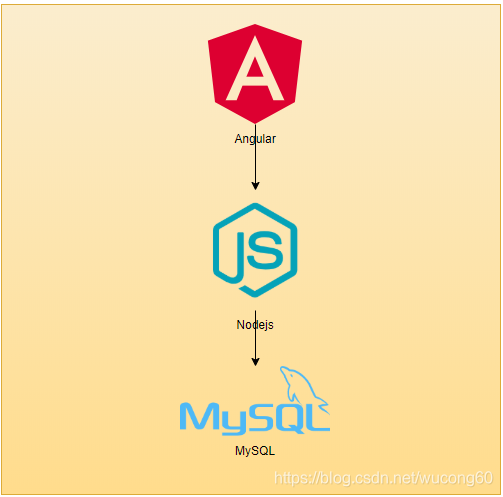
具体的网页如下图所示
可以看出是一个非常普通的网站,在这里我们试想一下,我们如何对一个大单体进行拆分,是否需要全面迁移和重构?
三、应用设计
微服务提供了强大优势的同时也带来了巨大的新挑战,我们打算采用微服务的思想对它进行分析。
(一)、如何设计?
微服务架构模式为创建微服务应用提供了基础支持,它其实是某种领域驱动设计(DDD)模式外加容器编排理论。在实际项目中,前端已经被分离出去了,我们只需要对后端API按某种规则拆成一个个小的微服务,目前有大概20多个微服务,每个微服务都是一个单独的Nodejs WebAPI应用,他们互不依赖,可以进行独立的开发和部署,最后将这些微服务部署到GCP云上的AppEngine里,AppEngine本身包含对容器编排、服务自动横向扩缩的能力。
- 领域驱动设计:我们没有使用领域驱动设计(如果说有的话,那就是所有服务共用一套通用领域模型,感觉怪怪的)
- 容器编排:目前主流使用K8s,但我们不必要自己在本地搭建它,各类云厂商已提供了很好的此类服务,比如Azure的AKS,GCP的GKE等,他们提供了强大的容器编排服务能力,但也提高了学习和使用成本,这里我们使用更加集成化的PAAS服务AppEngine,它已经包含了容器编排的能力,我们只需要负责上传代码就可以了,其他的事全部交给云服务去处理。
- 服务间的通信(同步/异步):目前本项目中也没有,下图像少了个尾巴,但使用了其他的替代方案,后面将会完善。
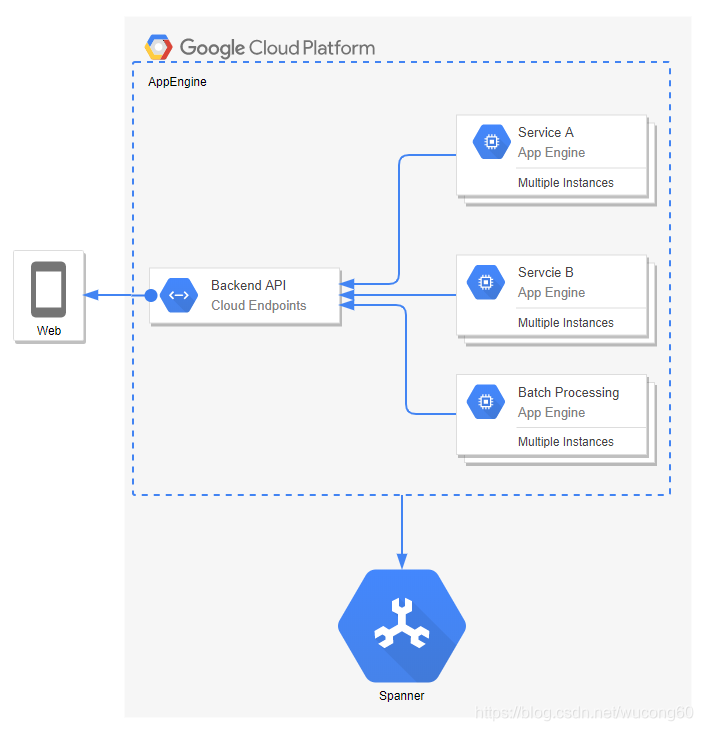
部署在AppEngine中的服务大致如下图所示, 在AppEngine的最佳实践中可以看出,它天然支持多服务。红色部分就是部署在AppEngine中的服务,如果想了解AppEngine的更多内容,猛戳这里

(二)、如何拆分服务?
比较有技术学问的应该属于这一块了,服务拆分讲究一个“度”,学过马哲的小伙伴应该知道“度”是属于哲学的一个范畴,哈哈,但有一些准则是可以测量它的。
微服务的大小不是重点,服务拆分粒度应该保证微服务具有业务的独立性与完整性,尽可能少的存在服务依赖,链式调用,以便能独立地开发、部署和扩展每个服务。从程序设计的简单角度来说就是解耦,比如说你的团队提交的代码和其他团队提交的代码频繁出现大量冲突或需要频繁沟通的时候,你是否需要考虑把服务拆分一下呢?
拆分服务的核心是如何识别微服务的领域模型边界,而微服务的理论本身就源自于领域驱动设计(DDD)的限界上下文(BC)模式,所在拆分服务的时候使用DDD 模式是一种好的选择,它可以用来识别限界上下文。本质上,当我们对相关领域的了解越深入,就应该越能够适配微服务的大小,找到正确的大小。
拆分服务出合适的微服务的大小,通常这个目标是无法一蹴而就的。在实际的开发过程,我们在设计之初可以将服务的粒度设计的大一些,并考虑其可扩展性,随着业务的发展,再慢慢根据需要进一步地拆分。
服务拆分既可以通过业务能力拆分,也可以通过领域驱动设计(DDD)进行拆分。
服务拆分的内容很多,需要更多的文章才能讲得明白,我这里准备的一些链接,他们都讲得太好了。
- 微服务拆分的前提、时机、方法、规范、选型, 这篇讲得真不错
- 微服务架构设计6种模式
- 康威定律 该定律认为,应用程序本身体现了创造这个应用的企业本身 的组织架构。
- 阿里云容器服务学习路径
本项目中,到目前为止拆分出了20多个微服务了,也是采用渐进的或者逐渐改进的方式来拆出这么多的。一开始是简单粗暴按菜单进行拆分,也可以理解为业务逻辑拆分,后来又单独拆出的部分服务如下:
- 网站的访问权限,拆分作为一个服务
- 网站的一个框架,即一个壳子(shell) 及基础数据,拆分作为了一个服务
- 某一个查询页面,它包括不同维度的查询,几乎不涉及写操作,拆分作为了一个服务
- 网站的提醒功能,拆分作为了一个服务
- CRON JOB用于定时跑任务的,拆分作为了一个服务
可以看到,只要一个服务具有业务的独立性与完整性,与其他服务不存在依赖,那它就可以被拆出来,拆服务之前你的DevOps一定要先弄好,这是微服务化的前提。
(三)、单个服务的架构
微服务是一种思想,或者说是一种逻辑架构,创建微服务并不要求必须使用某种技术,例如 Docker 容器就不是必需的。在本项目中就没有使用Docker,类似于下图所示,只需要有app.yaml这个配置文件, 就可以使用GCP SDK 将单个服务部署上去的,并没有将其打包为了一个Docker镜像。
(四)、为什么不使用多数据库?
单个服务必须拥有自己的领域模型(数据 + 逻辑 + 行为),这样才算一个完整的微服务,也就是说每个服务都独立拥有自己的数据库,这样会带来不小的挑战:
- 如何拆分服务。数据库如何设计几乎与你的领域驱动模型相匹配,所以要先拆分服务。
- 如何创建从多个微服务获取数据的查询。通常一个服务是不能直接访问另一个服务的数据库的,比如:你需要生成一个Report,它需要从不同的数据库的表中聚合数据。有两种办法:(1)调用它们的API将数据聚合起来。(2)使用 CQRS 来处理多数据库,提前生成好Report的数据,即提前生成只读表或视图。 如果这种聚合的操作发生的很频繁,那么要考虑之前拆分服务是否拆错了,是否需要合并服务。
- 多数据库之间如何实现一致性。通常我们不使用强一致性,强一致性很难做到高可用和高可扩展。 更多的是使用最终一致性。办法是:事件驱动、异步通信,常用的云服务有Azure的Service Bus, GCP的Pub/Sub。
从上可以看出,我们需要花额外的努力去解决这些的问题,而且不太容易解决。在本项目中并没有使用多数据库的方式,因为项目不算大,没有领域模型,项目中只使用了个中心化的数据库,是使用GCP的Spanner数据库,它是一个分布式的关系型数据库,我们项目所有的服务共用这一个数据库。
微服务是把双刃剑!
如果你的项目比较复杂,一张表可能数十列,甚至上百列,而某些相对独立的业务并不会用到所有的列,即不同的领域模型用得到字段是不一样的,那么就可以考虑是否改用多数据库的方式。
如果你的项目不算复杂或者项目成员还没有足够的能力去使用微服务架构,往往单体应用或像本项目这样的伪微服务的变体应用更加适合。
(五)、应用数据如何存储?
可使用云服务,各类云厂商都提供了相应的对象存储服务。
- AWS: 可以使用S3存储
- Azure: 可以使用Service Account存储
- GCP: 可以使用Storage存储
- Ali: 可以使用OSS存储
(六)、如何实现使用 API 网关的?
它主要是为多个微服务提供单个入口的服务,可使用云服务,各类云厂商都提供了相应的API 网关服务。
- AWS: 可以使用API Gateway
- Azure: 可以使用Api Management
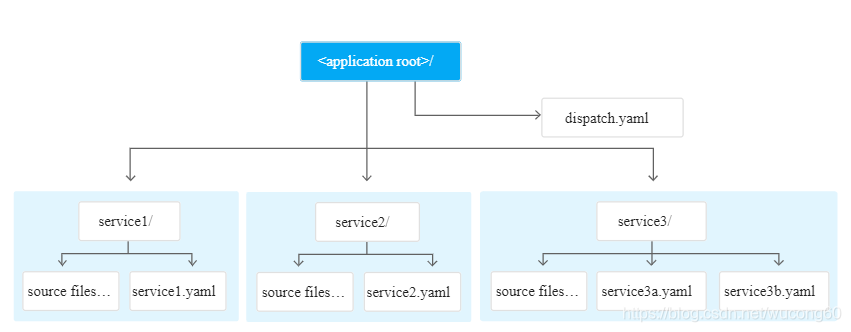
在本项目中,由于使用得是AppEngine服务,它本身内置了这种路由分发和负载均衡的功能,dispatch.yaml文件就定义了这种路由规则,想了解AppEngine的更多内容,猛戳这里
(七)、服务通信与服务治理?
这些如果你想使用的话,其实也需要花不少的努力去处理这类问题的。如果你希望了解服务通信原理的话可以参考如下链接。
如果你希望了解服务治理方面的内容的话,建议你去看一下istio
但本项目使用AppEngine,它也内置了这些功能,想了解AppEngine的更多内容,猛戳这里
(八)、关于部署,使用DevOps
本项目是使用Azure DevOps工具来实现CI/CD。
(1)Pipelines->Library主要是用于存放应用程序所需要的环境变量、参数、及文件等敏感信息,比如:密码、数据库连接字符串、密钥文件等,通常来说源代码里不应该包含这些敏感数据,而是放在这里。我们首先需要在Library里给每个环境分别定义一个Variable group,它里面定义应用程序运行所需要的环境变量。接着在Secure files存放GCP service account的json文件,它包含私钥信息,有了它我们就可以通过GCP SDK将应用程序部署到GCP云上。
(2)Pipelines->Pipelines 是用于持续集成(CI),我们可以使用它将程序打包、运行UT及测试覆盖率等,最终构建出我们需要的Artifact。本项目中是使用yaml文件来创建此pipeline的,它定义在源代码中,点击azure-pipelines.yml
(3)Pipelines->Releases是用于部署的(CD),将CI中生成好的Aritifact部署到相应的环境中去,比如:部署到虚拟机或某些PAAS服务里,以便用可以通过IP或域名访问到我们的应用程序。本项目中是将Artifact部署到GCP的AppEngine里,下面主要列出bash脚本。
# 第一步:在release definition中选择agent时你选择要下载的artifact zip包
# 第二步:在release definition中创建一个task用于下载service account文件
# 第三步:解压Artifact, 如果你不知道像这样的参数$AGENT_RELEASEDIRECTORY的实际路径是什么,不妨先运行一个Release试试,在Initialize job阶段它会列出所有参数及相应的值,或者参考官网,里面有预先定义的参数。
if [ -f $AGENT_RELEASEDIRECTORY/Artifacts/release/api-gateway-$(ApiGateway_Srv_Name)-$(Release.Artifacts.Artifacts.BuildNumber).zip ]; then
cd $AGENT_RELEASEDIRECTORY/Artifacts/release && unzip api-gateway-$(ApiGateway_Srv_Name)-$(Release.Artifacts.Artifacts.BuildNumber).zip
else
echo "File not found to extract : $AGENT_RELEASEDIRECTORY/Artifacts/release/api-gateway-$(ApiGateway_Srv_Name)-$(Release.Artifacts.Artifacts.BuildNumber).zip"
exit 1
fi
# 第四步:在release definition中创建一个task用于安装GCP SDK
# 第五步:部署到AppEngine的时候是需要用app.yaml文件的,它里定义了运行时和所需要的环境变量,所以我们需要将Library里定义的环境变量写入到app.yaml文件中,事先我们在app.yaml中给每个环境变量设置了placeholder,在这一步,我们需要将这些placeholder替换成真正的环境变量。比如:PROJECT_URL是library中定义的变量,$(PROJECT_URL)是它的值,[PROJECT_URL]是在app.yaml中设置的placeholder。
cd $AGENT_RELEASEDIRECTORY/Artifacts/release/dist_archive
ls -ail && pwd
echo "************ Replace PROJECT_URL ************"
sed -i -e "s/\[PROJECT_URL\]/$(PROJECT_URL)/g" "./app.yaml"
echo "************ Replace CLIENT_ID************"
sed -i -e "s/\[CLIENT_ID\]/$(CLIENT_ID)/g" "./app.yaml"
# 第六步:激活serviceAccount,然后部署artifact到appengine中。
cd $AGENT_RELEASEDIRECTORY/Artifacts/release/dist_archive
ls -ail && pwd
gcloud config set verbosity debug
cp $(Agent.TempDirectory)/$(GCP_CREDENTIAL_FILE) ./keyfile.json
# 激活serviceAccount
gcloud auth activate-service-account $(SR_ACCT_CLIENT_EMAIL) --key-file=./keyfile.json --project $(GCP_PROJECT_ID)
# 设置此serviceAccount为当前的account
gcloud config set core/account $(SR_ACCT_CLIENT_EMAIL)
# $(SERVICE_FILE_PATH) 实际就是app.yaml文件, 你可以将它hard code在这。
SERVICE_FILE_PATH="$(SERVICE_FILE_PATH)"
if [ -z "$(CRON_SERVICE_FILE_PATH)" ]
then
echo "SERVICE_FILE_PATH is: $SERVICE_FILE_PATH"
# 部署artifact到appengine中,就这么一行,前面所有的操作都为它而准备
gcloud app deploy $SERVICE_FILE_PATH --quiet
else
SERVICE_FILE_PATH="$SERVICE_FILE_PATH $(CRON_SERVICE_FILE_PATH)"
echo "SERVICE_FILE_PATH is: $SERVICE_FILE_PATH"
gcloud app deploy $SERVICE_FILE_PATH --quiet
fi如上三步操作定义了如何使用CI/CD一键部署我们的服务到AppEngine中,一个服务需要定义如上三步,如果你有20个服务,就需要定义20个这样的三步操作。 对于第三步,里面包含6个Task,你可以抽象出来把这6个Task放到一个Task group里。
如上CD是使用GCP SDK来部署的,其实还可以使用Terraform,它是一个 IT 基础架构自动化编排工具,将会在不久的将来介绍它。
(九)、如何处理认证和授权
本项目这里使用的是Azure的Azure AD认证服务,戳这里了解
四、代码
本代码是从实际项目中提炼出来,去掉了敏感信息,以及部分的改造让它变得更通用, 以便下次可以重用。代码的具体说明见代码中的readme,包含的内容有:
- DevOps中的CI部分
- 如何在本地运行单个服务
- 如何在本地运行所有服务
- 如何对Azure AD的token进行验证
- 设置cors
五、讨论与总结
1. 问题:假如后端的API被拆分成了20多个服务,前端网站必须依赖后端所有的API才能正常运行。那开发人员在本地开发的时候,岂不是要将这20多个服务全部运行起来?如果你是做.net程序开发的,每个服务对应一个WebApi Project,那这20多个WebApi Project如何同时运行?
答:对于本项目是使用Nodejs,单个项目既可以独立运行又可以作为子项目运行,所以很好地解决了这个问题,具体参考代码里的readme。那如果是其他非nodejs应用程序该如何解决呢?如果你有更好的解决办法,欢迎评论
2.问题:我们一共使用了哪些云服务?
答:(1)使用了AWS的S3来Host前端网站,包含S3+Lambda+CloudFront . (2) 使用了GCP里的AppEngine来Host后端的所有服务,包含AppEngine+Google Storage+IAM+Log Viewer。 (3) 使用了Azure的Azure AD作了认证服务,以及Azure DevOps来托管代码和持续集成。 可以看到,不知不觉我们已经使用了云的许多服务,要想构建一个现代化的应用已离不开云,它已经像水电煤一样慢慢渗透在我们的工作和生活之中。
参考链接
基于微服务的容器化应用程序: eShopOnContainers
