Linux下采用C语言实现文本单词计数(word count)并统计运行时间
由于WHUT的云计算课程实验要求,采用C lang实现word count功能。不得不说,用C语言处理字符串,真有一种想砸了电脑的冲动。。。
下面是源码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#include <time.h>
int* findn(int A[], int N);
int main() {
FILE* fp;
char fileName[256] = "/usr/local/data.dat";
// scanf("%s", &fileName);
fp = fopen(fileName, "r"); /* 以只读方式读取文件 */
clock_t start, stop;
start = clock();
int word_count = 0; // 记录单词总数
char store[60][15] = { '\0' };
char key[15] = { '\0' };
char temp[15] = { '\0' };
int weight[60] = {0};
int value = 0;
int key_length = 0;
while ((value = fgetc(fp)) != EOF) { /* 当文件未到末尾时,统计各对应字符的权值 (即频数) */
if (value != ' ') {
if (value != '.' && value != ',' && value != '!' && value != '?' && value != ':' && value != '#') {
key[key_length++] = value; // 获得单词key
}
}
if (value == ' ' || value == '#' || value == '\n') {
key[key_length] = '\0';
if (word_count == 0) { // 第一次
for (int m = 0; m <= key_length; m++) { // 将每个单词以行的形式存储在二维数组store中
store[0][m] = key[m];
}
weight[word_count]++;
word_count++;
} else {
int flag = 0;
for (int i = 0; i < word_count; i++) {
int k;
for (k = 0; store[i][k] != '\0'; k++) { // 将每个单词以行的形式存储在二维数组store中
temp[k] = store[i][k];
}
temp[k] = '\0';
int isOkay = -1;
if (abs(temp[0] - key[0]) == 32 && strlen(temp) == strlen(key)) { // 相差32 & 长度相同
char dest1[15] = { '\0' };
char dest2[15] = { '\0' };
int sub_length = strlen(temp) - 1;
strncpy(dest1, temp + 1, sub_length);
strncpy(dest2, key + 1, sub_length);
isOkay = strcmp(dest1, dest2);
if (isOkay == 0) { // 相同单词, 首字母大小写不同
weight[i]++;
flag = 1;
break;
}
}
else {
isOkay = strcmp(key, temp); // 0相同, 1不同
if (isOkay == 0) { // 相同单词
weight[i]++;
flag = 1;
break;
}
}
}
if (flag == 0) { // 全新单词
for (int j = 0; j < key_length; j++) {
store[word_count][j] = key[j];
}
weight[word_count]++;
word_count++;
}
}
key_length = 0;
}
}
//for (int i = 0; i < word_count; i++) { // 调试用
// for (int j = 0; store[i][j] != '\0'; j++) {
// printf("%c", store[i][j]);
// }
// printf("%4d\n", weight[i]);
//}
int* index = findn(weight, word_count);
for (int i = 0; i < 3; i++) {
int order = *(index + i);
for (int j = 0; store[order][j] != '\0'; j++) {
printf("%c", store[order][j]);
}
printf("%4d\n", weight[order]);
}
stop = clock();
double duration = (double)(stop - start) / CLOCKS_PER_SEC;
printf("word_count time: %fs\n", duration);
return 0;
}
int* findn(int A[], int N) { // 冒泡排序
int value[3] = { 0 };
int max = 0;
static int index[3] = { 0 }; // 此处必须加static,否则报错!
for (int j = 0; j < 3; j++) {
for (int i = 0; i < N; i++) {
if (A[i] > max) {
max = i;
value[j] = A[i];
}
}
index[j] = max;
A[max] = 0;
max = 0;
}
for (int j = 0; j < 3; j++) {
A[index[j]] = value[j];
}
return index;
}
几点说明:
-
没有完全考虑到英文中的所有标点符号,不过可以自己在程序中 获得单词key 的位置修改!
-
该程序以 # 作为结尾标识。
-
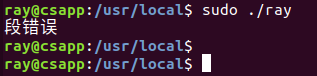
该程序在Linux下的GCC编译器运行通过。(注意输入的文件路径中不能包含 中文 (血的教训!!),否则会出现
段错误(核心转储))
如下图所示:
-
findn函数只实现了找到单词数量 前3 的单词,没有实现返回前n个单词的下标序列。而且需要注意的是findn函数中返回的数组在声明时,必须加 static 。
-
在linux下GNU的GCC编译器中,对头文件 <string.h> 和 <time.h> 的实现与windows下的Visual Studio的C lang编译器实现有差异。
此处不一 一列举,只说明在本程序中的差异:- 在Visual Studio的C lang编译器中,strcpy() 为可用于截取字符串,而在linux下,这一功能改用strncpy() 实现。
- 在Visual Studio的C lang编译器中,CLK_TCK 为一个时钟周期,而在linux下,这一功能改用CLOCKS_PER_SEC 实现。
