作者:chen_h
微信号 & QQ:862251340
微信公众号:coderpai
Flink学习(一):流处理介绍
使用 Apache Flink 进行流处理
在这个系列学习中,我们将重点关注四个关键概念:流数据的连续处理,事件时间,有状态流处理和状态快照。 在本节中,我们介绍这些概念。
流处理
流是数据的自然表达形式。 无论是来自 Web 服务器的事件,来自证券交易所的交易还是来自工厂车间机器上的传感器读数,数据都是作为流的一部分创建的。 但是,当我们分析数据时,我们可以围绕有界流或无界流来组织处理,而我们选择这些范式中的哪一个,是由它们产生的深远影响所决定的。

当我们处理有限的数据流时,批处理是工作的范例。 在这种操作模式下,我们可以选择在产生任何结果之前先提取整个数据集,这意味着可以对数据进行排序,计算全局统计数据或生成总结所有输入的最终报告。
另一方面,流处理涉及无限的数据流。 至少从概念上讲,输入可能永远不会结束,因此我们被迫在数据到达时对其进行连续处理。
在Flink中,应用程序由可以由用户定义的运算符转换的数据流组成。 这些数据流形成有向图,以一个或多个源开始,以一个或多个接收器结束。
当我们处理有限的数据流时,批处理是工作的范例。 在这种操作模式下,我们可以选择在产生任何结果之前先提取整个数据集,这意味着可以对数据进行排序,计算全局统计数据或生成总结所有输入的最终报告。
另一方面,流处理涉及无限的数据流。 至少从概念上讲,输入可能永远不会结束,因此我们被迫在数据到达时对其进行连续处理。
在Flink中,应用程序由可以由用户定义的运算符转换的数据流组成。 这些数据流形成有向图,以一个或多个源开始,以一个或多个接收器结束。

应用程序可能会消耗来自流数据(例如消息队列)或分布式日志(例如Apache Kafka或Kinesis)的实时数据。 但是flink也可以使用来自各种数据源的有限的历史数据。 类似地,由Flink应用程序产生的结果流可以发送到各种各样的系统,并且可以通过REST API访问Flink内保存的状态。
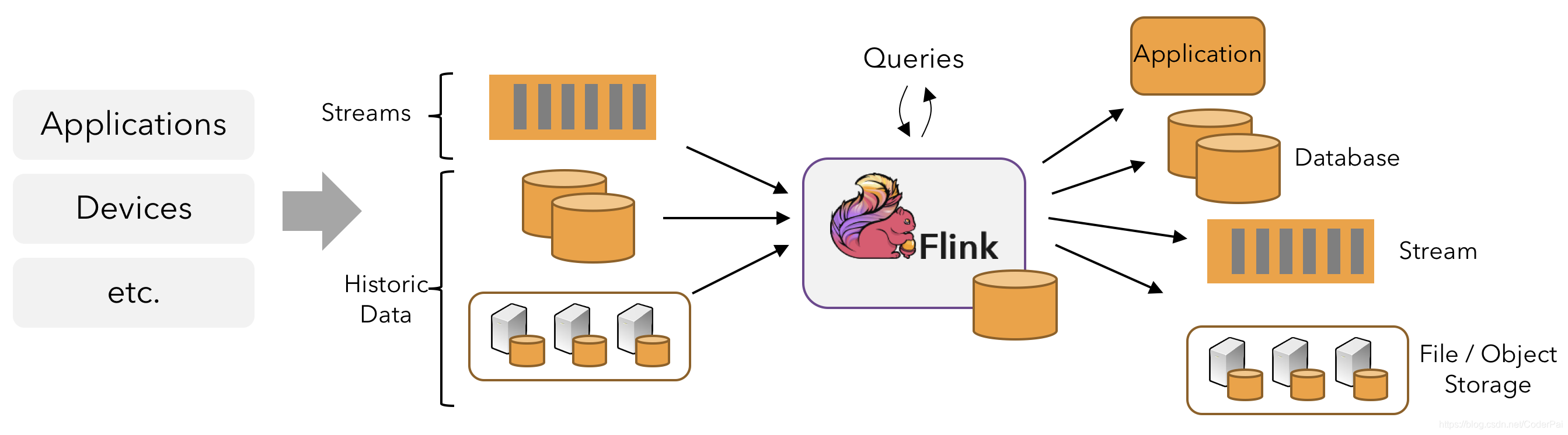
及时的流处理
对于大多数流媒体应用程序而言,能够使用用于处理实时数据的相同代码重新处理历史数据,并产生确定性的,一致的结果非常有价值。
注意事件发生的顺序,而不是交付事件进行处理的顺序,并能够推理出一组事件何时(或应该)完成,也至关重要。 例如,考虑电子商务交易或金融交易中涉及的事件集。
通过使用记录在数据流中的事件时间时间戳,而不是使用处理数据的机器的时钟,可以满足及时流处理的这些要求。
有状态流处理
Flink的操作可能是有状态的。这意味着如何处理一个事件可能取决于该事件之前所有事件的累积效果。状态可以用于简单的事情(例如,每分钟统计要显示在仪表板上的事件),也可以用于更复杂的事情(例如,用于欺诈检测模型的计算功能)。
Flink应用程序在分布式群集上并行运行。给定运算符的各种并行实例将在单独的线程中独立执行,并且通常将在不同的机器上运行。
有状态运算符的并行实例集实际上是分片键值存储。每个并行实例负责处理特定键组的事件,并且这些键的状态保存在本地。
下图显示了作业图中前三个运算符的并行度为2的作业运行,终止于并行度为1的接收器。第三运营商是有状态的,我们看到第二运营商和第三运营商之间正在发生完全连接的网络混洗。这样做是为了通过某些键对流进行分区,以便所有需要一起处理的事件都将被处理。

始终在本地访问状态,这有助于Flink应用程序实现高吞吐量和低延迟。 您可以选择将状态保留在JVM堆上,或者如果状态太大,则保留在有效组织的磁盘数据结构中。
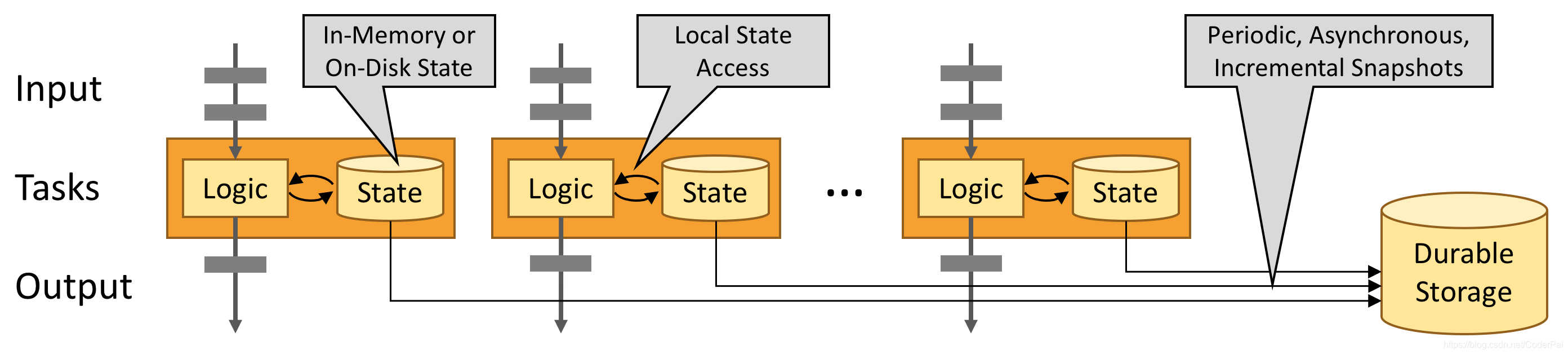
强大的流处理
通过状态快照和流重放的组合,Flink能够提供容错的,一次精确的语义。 这些快照捕获了分布式管道的整个状态,将偏移记录到输入队列中,并将整个作业图中的状态记录到了摄取数据的那一刻为止。 发生故障时,将重新倒转源,恢复状态,并恢复处理。 如上所述,这些状态快照是异步捕获的,而不会妨碍正在进行的处理。
什么是可以被流式传输的?
Flink 的 Java 和 Scala 的 DataStream API可让您流式传输可序列化的所有内容。 Flink自己的序列化器用于:
- 基本类型,即String,Long,Integer,Boolean,Array
- 复合类型:元组,POJO和Scala case class。
而Flink则退回给Kryo使用其他类型。
Java Tuples
对于 Java ,Flink 通过自己定义了 Tuple1 到 Tuple25。
Tuple2<String, Integer> person = new Tuple2<>("Fred", 35);
// zero based index!
String name = person.f0;
Integer age = person.f1;
POJOs
A POJO (plain old Java object) is any Java class that
- has an empty default constructor
- all fields are either
- public, or
- have a default getter and setter
Example:
public class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
…
};
}
Person person = new Person("Fred Flintstone", 35);
一个完整的例子
本示例将有关人的记录流作为输入,并对其进行过滤以仅包括成年人。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.api.common.functions.FilterFunction;
public class Example {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Person> flintstones = env.fromElements(
new Person("Fred", 35),
new Person("Wilma", 35),
new Person("Pebbles", 2));
DataStream<Person> adults = flintstones.filter(new FilterFunction<Person>() {
@Override
public boolean filter(Person person) throws Exception {
return person.age >= 18;
}
});
adults.print();
env.execute();
}
public static class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
this.name = name;
this.age = age;
};
public String toString() {
return this.name.toString() + ": age " + this.age.toString();
};
}
}
流执行环境
每个Flink应用程序都需要一个执行环境,在此示例中为env。 流应用程序应使用StreamExecutionEnvironment。
在应用程序中进行的DataStream API调用将构建一个作业图,该作业图将附加到StreamExecutionEnvironment。 调用env.execute()时,此图将打包并发送到作业管理器,作业管理器将作业并行化并将其片段分发给任务管理器以执行。 作业的每个并行切片都将在任务槽中执行。
请注意,如果您不调用execute(),则您的应用程序将不会运行。
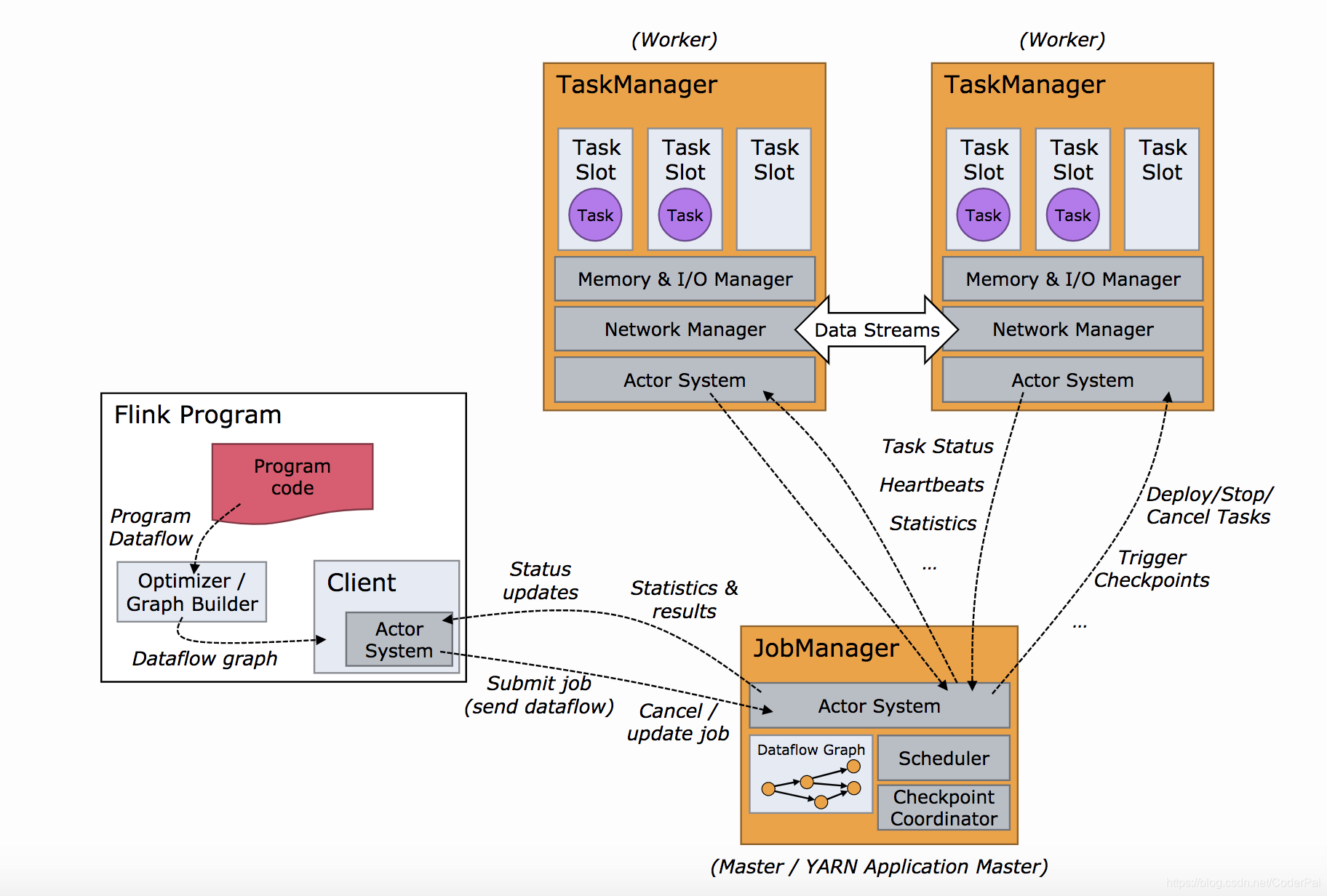
此分布式运行时取决于您的应用程序是否可序列化。 它还要求所有依赖性对于群集中的每个节点均可用。
基本流源
在上面的示例中,我们使用env.fromElements(…)构造了一个DataStream 。 这是将简单的流放在一起以用于原型或测试的便捷方法。 StreamExecutionEnvironment 上还有一个 fromCollection(Collection)方法。 我们可以这样做:
List<Person> people = new ArrayList<Person>();
people.add(new Person("Fred", 35));
people.add(new Person("Wilma", 35));
people.add(new Person("Pebbles", 2));
DataStream<Person> flintstones = env.fromCollection(people);
完整程序如下:
package myflink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.api.common.functions.FilterFunction;
import java.util.*;
public class test {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
List<Person> people = new ArrayList<Person>();
people.add(new Person("Fred", 35));
people.add(new Person("Wilma", 35));
people.add(new Person("Pebbles", 2));
DataStream<Person> flintstones = env.fromCollection(people);
DataStream<Person> adults = flintstones.filter(new FilterFunction<Person>() {
@Override
public boolean filter(Person person) throws Exception {
return person.age >= 18;
}
});
adults.print();
env.execute();
}
public static class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
this.name = name;
this.age = age;
};
public String toString() {
return this.name.toString() + ": age " + this.age.toString();
};
}
}
在原型制作时将一些数据放入流中的另一种便捷方法是使用套接字,如下所示:
DataStream<String> lines = env.socketTextStream("localhost", 9999)
完整程序如下所示:
package myflink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
public class Example {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> lines = env.socketTextStream("localhost", 9000, "\n");
DataStream<Person> adults = lines.flatMap(new FlatMapFunction<String, Person>() {
@Override
public void flatMap(String lines, Collector<Person> collector) throws Exception {
String[] data = lines.split("\\s");
Person p = new Person(data[0], Integer.parseInt( data[1] ) );
collector.collect(p);
}
}).filter(new FilterFunction<Person>() {
@Override
public boolean filter(Person person) throws Exception {
return person.age >= 18;
}
});
adults.print().setParallelism(1);
env.execute();
}
public static class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
this.name = name;
this.age = age;
};
public String toString() {
return this.name.toString() + ": age " + this.age.toString();
};
}
}
或者通过一个文件进行读取数据,如下所示:
DataStream<String> lines = env.readTextFile("file:///path");
我们先来构建一个数据文本 test.txt,里面的内容如下:
Tom 78
Fred 35
Wilma 35
Pebbles 2
注意,文件路径需要是绝对路径,相对路径我这边报错了。
完整程序如下所示:
package myflink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
public class test {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> lines = env.readTextFile("绝对路径");
DataStream<Person> adults = lines.flatMap(new FlatMapFunction<String, Person>() {
@Override
public void flatMap(String lines, Collector<Person> collector) throws Exception {
String[] data = lines.split("\\s");
Person p = new Person(data[0], Integer.parseInt( data[1] ) );
collector.collect(p);
}
}).filter(new FilterFunction<Person>() {
@Override
public boolean filter(Person person) throws Exception {
return person.age >= 18;
}
});
adults.print().setParallelism(1);
env.execute();
}
public static class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
this.name = name;
this.age = age;
};
public String toString() {
return this.name.toString() + ": age " + this.age.toString();
};
}
}
在实际应用程序中,最常用的数据源是那些支持低延迟,高吞吐量并行读取以及倒带和重放(高性能和容错能力的先决条件)的数据源,例如Apache Kafka,Kinesis和各种文件系统。 REST API和数据库也经常用于流富集。
基本流汇总
上面的示例使用 Adults.print()将结果打印到任务管理器日志中(当在IDE中运行时,它将显示在IDE的控制台中)。 这将在流的每个元素上调用toString()。
控制台打印的数据如下:
1> Fred: age 35
2> Wilma: age 35
其中1>和2>指示哪个子任务(即线程)产生了输出。
您也可以写入文本文件。
stream.writeAsText("/path/to/file")
将代码中的 adults.print().setParallelism(1); 这一行,修改为 adults.writeAsText("绝对路径/result"); 。
在生产中,常用的接收器包括Kafka以及各种数据库和文件系统。
调试
在生产环境中,您将向运行应用程序的远程集群提交应用程序 JAR 文件。 如果失败,它也将远程失败。 作业管理器和任务管理器日志对于调试此类故障非常有帮助,但是Flink支持在IDE内进行本地调试要容易得多。 您可以设置断点,检查局部变量,并逐步执行代码。 您也可以进入Flink的代码,如果您想了解Flink的工作原理,这可能是一种了解其内部细节的好方法。
