iris数据集:
iris数据集从sklearn中获取,其csv文件地址...\Lib\site-packages\sklearn\datasets\data\iris.csv
最初接触主成分分析是在数学建模中,旨在以较少的新指标来替换原来较多的旧指标,换句话说就是对高维空间进行降维处理。
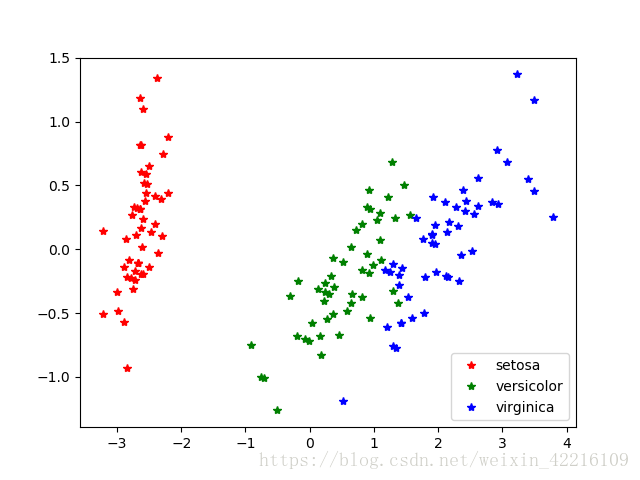
Iris数据集是常用的分类实验数据集,包括150个样本,分为3类(Setosa,Versicolour,Virginica)。每个样本包括花萼长度,花萼宽度,花瓣长度,花瓣宽度4个特征。由于样本特征已经属于高维数据,不便以图解形式分类。为了直观上对3种鸢尾花的分类有一个感性的认识,我们可以通过PCA降维处理,使其样本只包含两个新特征。
函数原型及主要参数说明
class sklearn.decomposition.PCA(n_components=None)参数说明:
n_components : 类型:int, float, None or string
含义:所要保留的主成分个数(Number of components to keep)。
函数方法
fit_transform(self, X, y=None)参数说明:
X:训练数据X_train,并且X_train.shape(n_samples, n_features)(注:n_features为原样本的特征个数)
y : Ignored.
返回:
X_new : X_new.shape (n_samples, n_components )(注:n_components为设置保留的主成分个数)
应用
直接附上基于python的代码。
from sklearn.datasets import load_iris #导入数据集
from sklearn.decomposition import PCA #导入函数库
import matplotlib.pyplot as plt
import numpy as np
iris=load_iris()
pca=PCA(n_components=2) #设置保留的主成分个数为2
trans_data=pca.fit_transform(iris.data) #调用fit_transform方法,返回新的数据集
index1=np.where(iris.target==0)
index2=np.where(iris.target==1)
index3=np.where(iris.target==2)
labels=['setosa', 'versicolor', 'virginica']
plt.plot(trans_data[index1][:,0],trans_data[index1][:,1],'r*')
plt.plot(trans_data[index2][:,0],trans_data[index2][:,1],'g*')
plt.plot(trans_data[index3][:,0],trans_data[index3][:,1],'b*')
plt.legend(labels)
plt.show()最后附上效果图,可以发现通过PCA降维处理能直观上对数据进行分类,并且在Iris数据集上有较好的体现。