Paper reading: GhostNet:More Features from Cheap Operations
1. 关于GhostNet的motivation
这篇文章其实是一篇对于工业应用很实际的一篇文章,我们就不是单纯的从翻译文章来讨论这个问题,而是从实际应用加上理论这样可能更加直观一些。
可以看到这篇文章是华为实验室完成的,华为的海思芯片如3559a等,是可以直接应用caffe模型进行部署的,虽然现在只支持caffe 1.0,但是在前端AI中也算是有着举足轻重的地位。但是这么小的芯片,必然是不能够和后端什么2080Ti这种洪水猛兽所抗衡的,inference的时间自然会有所增加,据前端的同事说,NNIE(Neural Network Inference Engine)还无法像GPU一样支持并行操作,所以很多模型只能串行做inference,这对于时效性要求很高的情况下是很难解决的。那么对于一个实际的产品,想要优化其性能,不就是通过两个方面嘛,一个是硬件层面,一块卡不行来两块,实在不行弄个集群,总能跑的快,第二个方面就是软件方面,之前写过一点点cuda代码,同样一个算法,你优化之前和优化之后性能可能相差上千倍,这个是很有可能的。这篇文章也是从软件的层面来进行优化的,据产线同事说在inference的时候,最后只能使用单batchsize,理想很丰满,现实很残酷,工业上的实际落地确实要比学术界要考虑更多的实际问题,成本、时效、内存等等一系列。
言归正传,这篇文章是主要是考虑减少内存和计算量这个方面来进行模型优化的,那么为什么可以进行模型优化呢?那必然是feature map的信息冗余了,你才可以说我可以扔掉一部分的重复的信息,并且也不至于会影响最终的效果。于是作者拿出了ResNet-50中的一层feature map,可以看到共有30个feature map,中间有三对feature map是肉眼可以观察到的包含的信息是比较类似的,这又是什么意思呢?也就是说对应的卷积核学到的信息是类似的,换言之,有些卷积核我们就可以不用了,而是用简单的线性变换,通过一个feature map来生成另一个相似的feature map,省去了使用大量卷积的运算,也减少了大量卷积的参数,这个也就达到了这篇文章的两个目的,减少了卷积核的数量,可以减少参数量,也就减少了内存损耗,而减少了卷积运算,也就减少了计算量,从理论上是完成可行的。

2.总得会计算参数量和计算量,才会看懂这篇文章吧!
上面一些见解就算是introduction的部分吧,related work LZ就不说了,写上的话感觉也就是单纯的翻译文章,那不如直接看原文算啦。好了,重头戏来了,那么华为到底是怎么样来减少内存和计算量的呢?
要减少内存和计算量,第一步是不是得会算这两个数。
计算量的计算方式:

乍一看,肯定会有点蒙,LZ解释一下就好啦,其中c是输入feature map的通道数,k是指kernel size,h‘是输出feature map的高度,w’是输出feature map的宽度,n是输出feature map的通道数,可以这样想,输出的feature map的每个像素是通过c·k·k卷积得到的,所以输出的feature map上每个像素对应的计算量就是c·k·k,共有h’·w’·n个像素,就可以得到上述的计算公式了。
参数量的计算,可以看到,卷积神经网络主要的参数,全连接的参数是巨大的,其次就是卷积核的参数,本文主要就是针对卷积核来进行压缩的,我们就简单计算一下卷积核的参数:
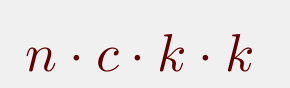
这个就相当直观了,就是卷积核的参数量,当然还有bias,但是简单起见,bias就忽略不计了,毕竟数量和卷积核参数比起来,数量基本可忽略不计了。
3. Ghost Module Part,对LZ来说最重要的部分
这也是本文的精髓所在,参数怎么减少,计算量怎么减少,就是依赖这张图。下图(a)就是我们常见的卷积神经网络,而图(b)就是本文的核心点。其实主要的工作看上去就很简单了,举个例子,假设我们原来想要产生64个通道的feature map,现在我们就先产生个16个通道的,也就是图(b)的左边conv操作,那么剩下的(64-16)=48个通道的feature map我们怎么生成呢?通过 ,来进行生成就可以了,通过3x3或者5x5的depthwise的卷积,就可以进行对应的操作,并且使用padding为same,stride=1的条件下,feature map的大小并不会产生变化,那我们需要多少个 呢,当然是48个啦,我们可以简单计算下,我们需要的参数是16个卷积核的参数加上,或者5x5x48,这个参数量减少了近3/4,那么内存也就相应减少了3/4,计算量也是近3/4,那么确实这样的操作是能够减少内存占用率和计算量的。
最后将生成的48个单层feature map和原来卷积生成的feature map 进行concat,得到最终64个通道的feature map。
那么效果呢?

原始计算量和和改进后计算量的比例计算为:
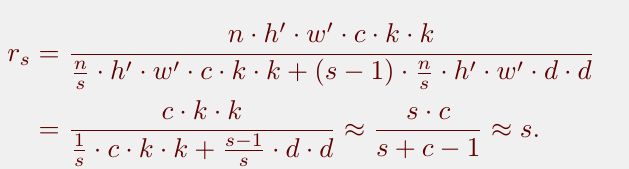
其中s是指原来定义的通道数和后来想要生成通道数的比例。因为s<<c,所以做了个近似。
原始卷积参数量和改进后的参数量的比例计算为:
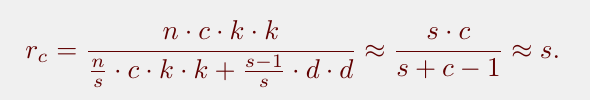
4. GhostNet
GhostNet也采用和ResNet的机制,使用shortcut操作,并且一个bootleneck包含两个ghostmodule,第一个用来增加channel数,第二个用来恢复原始 channel数。

可以看下GhostNet的具体结构:

其中SE module其实是增加了一个channel attention的机制,具体到底哪一层用,哪一层不用估计也得试出来。。。
5.结论
文章既然能发出来,自然结果还是不错的,但在具体的任务上,效果如何,还有待测试!LZ要去亲测了。。。

