WikiExtractor的链接:https://github.com/attardi/wikiextractor
需要的环境官网有写明:The tool is written in Python and requires Python 2.7 or Python 3.3+ but no additional library.
意思是:基于python2.7或python3.3, 且不需要依赖于第三方模块。
如果没有安装GitHub的,可以直接在这里下载。
有安装的:
git clone https://github.com/attardi/wikiextractor wikiextractor
cd wikiextractor
python setup.py install
至此,环境已配置好。接下来是下载Wikipedia的语料。
下载地址:https://dumps.wikimedia.org/zhwiki/,这里是下载中文语料库的地址,标志是zh
可通过查询自己需要的语种的639-1码,更改zh即可。比方说英语的,就是https://dumps.wikimedia.org/enwiki/
一般下载latest,根据需要选择日期。
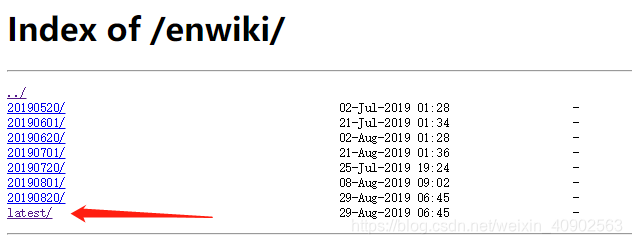
进去后根据需要下载文件。我需要的是文章的,所以我下载的是:
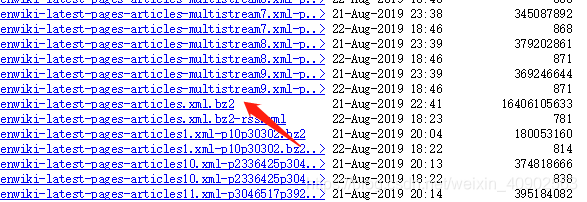
这里提倡挂VPN下载,否则会很忙,还会出现下载中断情况,不过中断了重新开始即可。
下载完后,将该压缩文件拷贝进wikiextractor文件夹里面,接下来就是核心命令:
打开命令行:
cd wikiextractor
python WikiExtractor.py -b 1024M -o extracted enwiki-latest-pages-articles.xml.bz2
其中1024M是指单个文件允许的最大的占用硬盘的大小, 接着就会出现:

我这里是已经跑了一段时间了,然后会在这个文件夹下出现一个文件夹extracted,里面就是提取出来的语料。
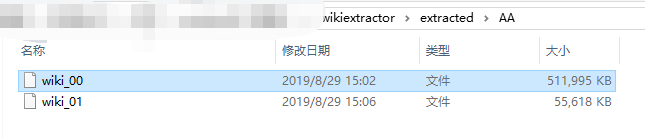
这是最终结束的时候:

使用WikiExtractor提取维基百科语料

猜你喜欢
转载自blog.csdn.net/weixin_40902563/article/details/100137620
今日推荐
周排行