- E步骤:根据观测值计算隐含变量的分布情况
- M步骤:根据隐含变量的分布来估计新的模型参数
相关链接:
EM算法详解-知乎(包含投硬币例子)
EM算法(含C++代码)
学习笔记:
先附上第二个链接中的代码:
// EM_learning.cpp: 定义控制台应用程序的入口点。
//试图用EM算法来根据输入的身高来区分性别
#include "stdafx.h"
#include<iostream>
#include<fstream>
#include<algorithm>
#include<vector>
using namespace std;
#define PI 3.14159
#define max(x,y) (x > y ? x : y)
typedef struct FLOAT2
{
float f1;
float f2;
}FLOAT2;
typedef struct Gaussian
{
float mean;
float var;
}Gaussian;
typedef struct EMData
{
char sex;
float fHeight;
}EMData;
//获取身高性别数据
int getdata(vector<EMData> &Data)
{
ifstream fin;
fin.open("data.txt");
if (!fin)
{
cout << "error: can't open the file." << endl;
return -1;
}
while (!fin.eof())
{
char c[10];
float height;
fin >> c >> height;
EMData data;
data.sex = c[0];
data.fHeight = height;
Data.push_back(data);
}
return 0;
}
//根据身高数据区分性别, 返回正确率
float predict(vector<EMData> Data)
{
//设符合正态分布
Gaussian sex[2];
float a[2]; //男女生所占百分比
float t = 1;
float tlimit = 0.000001; //收敛条件
//赋初值 下标0表示男生 1表示女生
sex[0].mean = 180.0;
sex[0].var = 10.0;
sex[1].mean = 150.0;
sex[1].var = 10.0;
a[0] = 0.5;
a[1] = 0.5;
while (t > tlimit)
{
Gaussian sex_old[2];
float a_old[2];
sex_old[0] = sex[0];
sex_old[1] = sex[1];
a_old[0] = a[0];
a_old[1] = a[1];
//计算每个样本分别被两个模型抽中的概率
vector<FLOAT2> px;
vector<EMData>::iterator it;
for (it = Data.begin(); it < Data.end(); it++)
{
FLOAT2 p;
p.f1 = 1 / (sqrt(2 * PI * sex[0].var)) * exp(-(it->fHeight - sex[0].mean) * (it->fHeight - sex[0].mean) / (2 * sex[0].var));
p.f2 = 1 / (sqrt(2 * PI * sex[1].var)) * exp(-(it->fHeight - sex[1].mean) * (it->fHeight - sex[1].mean) / (2 * sex[1].var));
px.push_back(p);
}
//E步
//计算每个样本属于男生或女生的概率
vector<FLOAT2>::iterator it2;
for (it2 = px.begin(); it2 < px.end(); it2++)
{
float sum1 = 0.0;
//float sum2 = 0.0;
(*it2).f1 *= a[0];
sum1 += (*it2).f1;
(*it2).f2 *= a[1];
sum1 += (*it2).f2;
(*it2).f1 = (*it2).f1 / sum1;
(*it2).f2 = (*it2).f2 / sum1;
}
//M步
float sum_male = 0, sum_female = 0;
float sum_mean_male = 0, sum_mean_female = 0;
for (it2 = px.begin(), it = Data.begin(); it2 < px.end(); it2++, it++)
{
sum_male += (*it2).f1;
sum_female += (*it2).f2;
sum_mean_male += (*it2).f1 * (it->fHeight);
sum_mean_female += (*it2).f2 * (it->fHeight);
}
//更新a
a[0] = sum_male / (sum_male + sum_female);
a[1] = sum_female / (sum_male + sum_female);
//更新均值
sex[0].mean = sum_mean_male / sum_male;
sex[1].mean = sum_mean_female / sum_female;
//更新方差
float sum_var_male = 0, sum_var_female = 0;
for (it2 = px.begin(), it = Data.begin(); it2 < px.end(); it2++, it++)
{
sum_var_male += (*it2).f1 * ((it->fHeight) - sex[0].mean) * ((it->fHeight) - sex[0].mean);
sum_var_female += (*it2).f2 * ((it->fHeight) - sex[1].mean) * ((it->fHeight) - sex[1].mean);
}
sex[0].var = sum_var_male / sum_male;
sex[1].var = sum_var_female / sum_female;
//计算变化率
t = max((a[0] - a_old[0]) / a_old[0], (a[1] - a_old[1]) / a_old[1]);
t = max(t, (sex[0].mean - sex_old[0].mean) / sex_old[0].mean);
t = max(t, (sex[1].mean - sex_old[1].mean) / sex_old[1].mean);
t = max(t, (sex[0].var - sex_old[0].var) / sex_old[0].var);
t = max(t, (sex[1].var - sex_old[1].var) / sex_old[1].var);
}
//计算正确率
int correct_num = 0;
float correct_rate = 0;
vector<EMData>::iterator it;
for (it = Data.begin(); it < Data.end(); it++)
{
float p[2];
char csex;
for (int i = 0; i < 2; i++)
{
p[i] = 1 / (sqrt(2 * PI * sex[i].var)) * exp(-(it->fHeight - sex[i].mean) * (it->fHeight - sex[i].mean) / (2 * sex[i].var));
}
csex = (p[0] > p[1]) ? 'm' : 'f';
if (csex == it->sex)
correct_num++;
}
correct_rate = (float)correct_num / Data.size();
return correct_rate;
}
int main()
{
vector<EMData> Data;
getdata(Data);
float correct_rate = predict(Data);
cout << "correct rate = " << correct_rate << endl;
system("pause");
return 0;
}
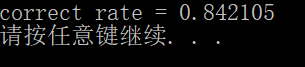
运行结果:
代码理解:
结构体FLOAT2:两个float类型变量,存放每个样本分别被两种模型抽中的概率
结构体Gaussian:存放高斯模型均值和方差
结构体EMData:存放每个样本的内容(性别(性别仅做准确率计算用)和身高)
首先,获取身高数据存入向量Data
调用predict函数进行EM算法,计算准确率
详细理解函数predict:
定义两个Gaussian结构体分别存放男女模型参数并赋初值(有时用K-means赋初值)
设男女所占百分比分别为50%;
当未满足收敛条件时
{
存放前一次循环的参数(以便最后计算收敛条件);
//E步
利用概率模型(当前的预估参数)计算 每个 模型得到 每种 样本的概率;
( (*it2).f1 *= a[0]; *a[0]表示得到模型 *f1表示得到样本)
(记得概率归一化 即相同样本被所有模型抽到的概率和为1)
//M步
对之前的概率做统计,更新预估参数(百分比、均值及方差)
计算变化率(收敛条件)
}
自己尝试用MATLAB 实现关于硬币分类的例子:(例子详见第一个链接)
%% EM算法学习 2019.12.7 Chen
%% 输入数据
n=5;
testdata=[3 2 1 3 2]; %存入投掷出正面的次数
testdata_=[2 3 4 2 3]; %存入投掷出反面的次数
p_a=0; %为a类硬币的概率
p_b=0; %为b类硬币的概率
pa=[1 1 1 1 1];
pb=[1 1 1 1 1];
sum_pa=0;
sum_pb=0;
vpa=[0 0 0 0 0]; %对a类模型生成每个样本的概率
vpb=[0 0 0 0 0]; %对b类模型生成每个样本的概率
%% 初始化模型
theta_a=0.2; %a类硬币投掷出正面的概率
theta_b=0.7; %b类硬币投掷出正面的概率
%% 迭代
ta=10;
tb=10;
while(ta>0.00001||tb>0.00001) %设置收敛阈值
%% 保存上一次迭代数据
theta_a_last=theta_a;
theta_b_last=theta_b;
%% E步
%计算每种模型生成每个样本的概率
for i=1:n
%模型a
for ii=1:testdata(i)
pa(i)=pa(i)*theta_a;
end
for ii=1:testdata_(i)
pa(i)=pa(i)*(1-theta_a);
end
%模型b
for ii=1:testdata(i)
pb(i)=pb(i)*theta_b;
end
for ii=1:testdata_(i)
pb(i)=pb(i)*(1-theta_b);
end
end
for i=1:n
vpa(i)=pa(i)/(pa(i)+pb(i));
vpb(i)=pb(i)/(pa(i)+pb(i));
% sum_pa=sum_pa+vpa(i);
% sum_pb=sum_pb+vpb(i);
end
% p_a=sum_pa/(sum_pa+sum_pb);
% p_b=sum_pb/(sum_pa+sum_pb);
%% M步
%根据隐含变量的概率,计算两组训练值的期望
%假设 得到模型,再得到样本
%模型a
sum_pa1=0;
sum_pa2=0;
sum_pb1=0;
sum_pb2=0;
for i=1:n
sum_pa1=sum_pa1+vpa(i)*testdata(i); %a类硬币且投出正面的期望
sum_pa2=sum_pa2+vpa(i)*testdata_(i); %a类硬币且投出反面的期望
sum_pb1=sum_pb1+vpb(i)*testdata(i); %b类硬币且投出正面的期望
sum_pb2=sum_pb2+vpb(i)*testdata_(i); %a类硬币且投出反面的期望
end
%根据期望,更新theta值 theta:在为某种类别时掷出正面的可能性
theta_a=sum_pa1/(sum_pa1+sum_pa2);
theta_b=sum_pb1/(sum_pb1+sum_pb2);
%% 判断迭代阈值
ta=abs(theta_a-theta_a_last)/theta_a_last;
tb=abs(theta_b-theta_b_last)/theta_b_last;
end
%% 输出概率模型
fprintf('$a类硬币投出正面概率\n');
theta_a
fprintf('$b类硬币投出正面概率\n');
theta_b
%% 计算准确率
% 此例无。
fprintf('$End\n');
