先上图:
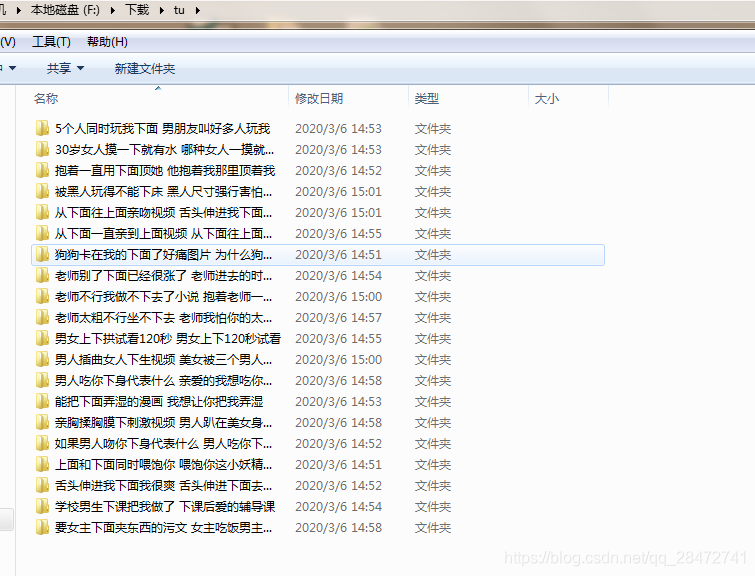
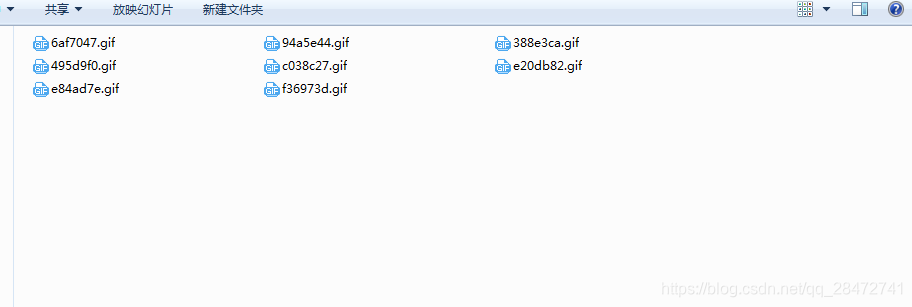
代码如下:
import requests
from pyquery import PyQuery as pq
import os, time
from urllib.request import urlretrieve
def mkdir(path):
path = path.strip()
path = path.rstrip("\\")
isExists = os.path.exists(path)
if not isExists:
os.makedirs(path)
def getImgUrl():
headers = {
'Host': 'www.27bao.com',
'User - Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/75.0.3770.142 Safari/537.36'
}
host = 'www.27bao.com'
url = 'https://www.27bao.com/quanwenyuedu/'
urls = []
for i in range(1,7):
urls.append(url+'list_{}.html'.format(i))
for i in urls:
res = requests.get(i, headers=headers)
res.encoding = 'uft-8'
# print(res.text)
content = pq(res.text)('.boxs .img li')
# print(content)
imgUrls = []
names = []
for i in content.items():
url = host + i('a').attr('href')
name = i('a').text().strip()
imgUrls.append('https://' + url)
names.append(name)
# print(imgUrls)
# print(names)
return imgUrls, names
getImgUrl('https://www.27bao.com/quanwenyuedu/')
def nextPage(url):
headers = {
'Host': 'www.27bao.com',
'Referer': 'https://www.27bao.com/',
'User - Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/75.0.3770.142 Safari/537.36'
}
host = 'https://www.27bao.com/'
res = requests.get(url, headers=headers)
# print(url)
category = url.split('/')[3]
res.encoding = 'uft-8'
# print(res.text)
# print(pq(res.text)('#pages'))
nextPageHerf = url.split('/')[-1].split('.')[0]
# print(nextPageHerf)
pages = pq(res.text)('#pages :first-child').text()
# print(len(pages))
# print(pages)
if len(pages) == 5:
totalPage = pq(res.text)('#pages :first-child').text()[1:3]
print(totalPage)
else:
totalPage = pq(res.text)('#pages :first-child').text()[1]
print(totalPage)
nextPages = []
for i in range(2, int(totalPage)):
nextPages.append(host + category + '/' + nextPageHerf + '_' + str(i) + '.html')
# print(nextPages)
return nextPages
def getImg(url, path):
headers = {
'Host': 'www.27bao.com',
'Referer': 'https://www.27bao.com/',
'User - Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/75.0.3770.142 Safari/537.36'
}
res = requests.get(url, headers=headers)
res.encoding = 'uft-8'
content = pq(res.text)('.content center img').attr('src')
try:
if content:
# urlretrieve(content, 'C:\\Users\\Administrator\\Desktop\\tupian\\11\\{}'.format(content[-12:]))
urlretrieve(content, path + '\\{}'.format(content[-12:]))
print('{}下载完成'.format(content))
except:
pass
def main():
urls, category = getImgUrl()
for i, m in zip(urls, category):
# print(i, m)
path = 'F:\\下载\\tu\\{}'.format(m)
mkdir(path)
getImg(i, path)
nextPages = nextPage(i)
for j in nextPages:
getImg(j, path)
time.sleep(1)
time.sleep(1)
if __name__ == '__main__':
main()
