参考网址:
ActiveMQ官网:http://activemq.apache.org/
https://blog.csdn.net/yinwenjie/article/details/51205822(大神,绝对大神)
摘要:
本章写了将CMS(ActiveMQ的C++客户端)及ActiveMQ应用于生产环境的踩坑记,一把辛酸泪啊
一、ActiveMQ集群部署
这里我采用的是参考网址的那位大神搭建的方式:静态桥接的方式,版本为:5.9.0,集群运行环境为CentOS release 6.8
下面是集群的大概示意图

二、CMS的客户端再次封装作为静态库用于生产环境
这里用的版本为cpp-3.9.3,官网给的demo作为生产环境还是不够的,需要再次封装下,因为公司原因,无法提供详细的源码,这里给出一段非常非常重要的代码,后面将说明为什么:

三、使用CMS静态库踩坑
将这个库给后端的大佬使用,一开始使用还很正常,然后用着发现不对劲了,为什么有时候连接建立不成功?找我来了。这也是苦逼的开始。然后我去他的测试环境和集群的测试环境查看。通过重启了很多很多次大佬的服务,我看到了一个有意思的现象,下面上图。
大佬程序的环境图:

ActiveMQ集群环境:

看到了吧,出现了2个tcp断开流程的中间状态,我就纳闷了,这个是随机出现的,而且概率还不小.最烦这种随机的了。。。
四、排坑
到这里,没办法只能硬着头皮上了。这个库在交付大佬之前,我自己是初步测试过的,没发现什么问题。鉴于上面的问题,然后我在问清楚大佬程序架构的基础上做了深入测试。
这里还做了并发测试,多线程、多进程连接测试。好吧,上面问题出现了。这里采用多进程并发测试连接时,发现了上面的问题。上测试的图:

下面这张是demo程序抛的java异常::DataInputStream::readLong - Reached EOF
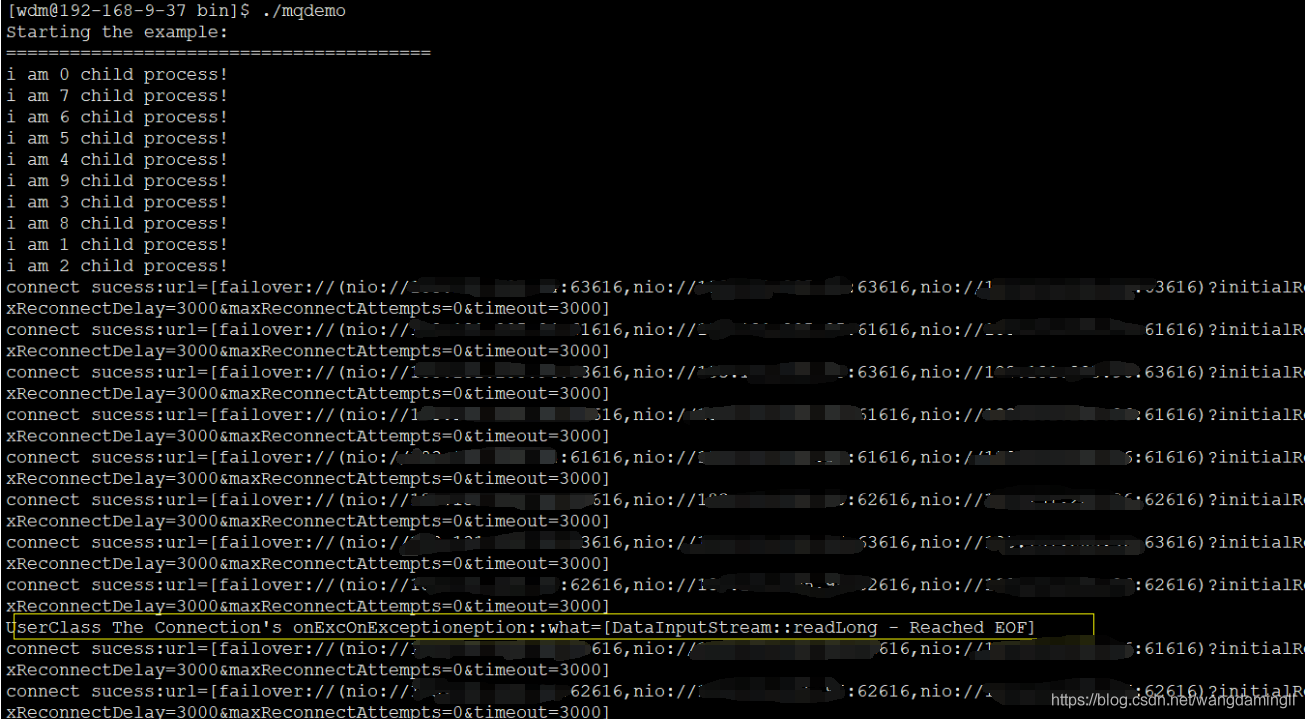
哈哈,废了老半天力气,定位到出问题的地方了。
回头仔细想一想,这有点不寻常啊,程序重启,进程初始化开始连接MQ,MQ集群那边主动断开连接,这个按道理来说是不应该的,CMS这端应该在MQ集群那边主动断开后,接着发送FIN,来完成整个tcp断开流程,而不是始终处于CLOSE_WAIT状态。
既然多进程并发出现这问题(多线程并发连接没有),然后我在fork子进程间sleep 1秒,后来完全正常。奇葩。
接着我查了MQ开发的bug网站看到了一些信息:

貌似这个版本有些问题啊。。。。。。。。
五、优化
到这里,我意识到,这个问题我是解决不了了,除非换新版本验证。但是能否回避这个问题呢?
从demo截图可以看到,当多进程并发出现问题的时候会回调一个异常函数,但是这个异常回调一定要有我在二中圈出来的那段代码才能产生,回调函数原型是:virtual void onException(const CMSException& ex);
既然知道有异常了,接着就可以在异常函数中设置状态需要重连,经测试,重连是可以成功的。这样就可以避免这个问题了。如果有大佬能够解决上面的问题,请一定要在下面评论告诉我,十分感谢。
