文章目录
索引简介
是什么:
帮助MySQL高效获取数据的数据结构(B树结构)
目的:
1、提高查询效率
2、为字段排序
缺点:
降低了insert、update、delete的速度。因为不仅仅要保存数据,还要更新索引。
索引分类
单值索引:
一个索引是一个单列(数据库表中的一列),一个表中可以有多个单列索引。
唯一索引:
索引列的值必须唯一,但可以为null。
复合索引:
一个索引包含了多个列。
索引性能分析(explain)
索引性能分析离不开explain语句,具体语法如下:
Explain select * from table where columns= xxxx;
返回结果是一张列表:
| id | select_type | table | type | possible_keys | key | keylen | ref | rows | extra |
|---|
id
代表表的读取顺序,一个查询语句可能会联合多张表进行查询,此时id代表MySQL加载表的先后顺序。id为为数值类型,数值越大代表优先级越高,则越先加载。当数值相同时,代表优先级相同,加载顺序为列表的显示顺序。
select_type
表示查询类型。具体有如下类型:
SIMPLE:普通查询即简单的select查询,查询中不包含子查询或者UNION查询。
PRIMARY:在嵌套查询中,最外层的查询会被标记为PRIMARY。
SUBQUERY:与PRIMARY相对的,在嵌套查询的内层会被标记为SUBQUERY。注意,这里的SUBQUERY的子查询是不能在from语句后面的查询。
SELECT *
FROM `student`
WHERE id = (SELECT id
FROM class
WHERE name = '二班');
在上面查询中,where后面的的查询语句就会被标记成SUBQUERY。
DERIVED:同样也是标记子查询的符号,但与SUBQUERY不同的是,DERIVED标记的查询是在from语句后面的。from语句后面的表会有笛卡尔积的操作,因此,MySQL要递归的执行这些子查询,把结果放在临时表里。
SELECT t2.*
FROM (
SELECT t3.id
FROM t3
WHERE t3.other_column = '123'
)s1, t2
WHERE s1.id = t2.id;
table
这一行是显示关于哪一张表的。
type
type表示查询使用了何种类型。有以下类型(从左至右越来越差):
| System | const | eq_ref | ref | range | index | All |
|---|
System:表示表只有一行
const:常量连接,表最多只有一行匹配,通用用于主键或者唯一索引比较时。即将一个主键放置到where后面作为条件查询,mysql优化器就能把这次查询优化转化为一个常量。
eq_ref:唯一性索引扫描。对于每隔索引建,表中只有一条记录与之匹配。
ref:非唯一性索引扫描,表中可能有多个几路与之匹配。
range:给定范围检索,就是检索中where语句中的 between,in ,<,>等
index:遍历整个索引数扫描
All:全表遍历。
注意: 虽然index和All都是全表遍历,但是index是在索引中读取,All是在硬盘中读取。
possible keys
显示在这次查询过程中可能用到的索引
key
实际用到的索引。
keylen
索引使用的字节数。
ref
显示索引的哪一列被使用了,可能是一个常数。你写列或者常量被用于查找索引上的值。
rows
MySQL 查询优化器根据统计信息,估算 SQL 要查找到结果集需要扫描读取的数据行数。这个值非常直观显示 SQL 的效率好坏, 原则上 rows 越少越好。
extra
using filesort:说明MySQL会使用一个外部索引排序。而不是按照表内的索引进行读取。这种操作性能差,实际应该尽量避免。
using temporary:表示MySQL需要使用临时表来存储结果集,出现此情况性能也会打折扣。
using index:表示使用到了覆盖索引,覆盖索引指的是在一次查询中仅仅查询索引就能得到待查询的字段,而不需要访问表。即索引列包含了待查询列。
using where:表示使用到了where条件。
索引优化
单表情况
建表如下(图为article表):

现要查询category_id为1,且comments大于1的情况下,views最多的article。查询语句如下:
SELECT id,author_id
FROM `article`
WHERE category_id = 1 AND comments > 1
ORDER BY views DESC
LIMIT 1;
使用explain来检测上面的查询语句得:

该语句出现了全表扫描All,和文件外部排序using filesort。这样的语句对数据库查询性能是大打折扣的,因此要将该语句优化。具体怎么优化呢?这里就是要建立索引了。
可以看到,这里的帅选条件是category_id,comments和views。那么常理来说应该将这三个按照语句中的出现顺序建立复合索引。但是,由于comments的帅选条件是大于,是一个范围。如果将它建立索引的话,它后面的索引将会失效, 也就是说建立了category_id,comments和views的复合索引,但实际只会用到category_id和comments,views会失效。因此在此仅仅建立category_id和views的复合索引。建立索引后再用explain分析上述查询语句。结果如下:

双表情况
有如下两个表(student表和class表):
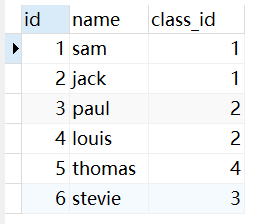
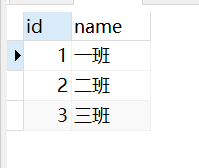
内连接
若使用内连接,则SQL语句如下:
SELECT * FROM student INNER JOIN class
ON student.class_id = class.id
对此语句的分析结果如下:

在此处对student的class_id 添加索引即可。
左外连接
SQL语句如下:
SELECT * FROM student LEFT JOIN class
ON student.class_id = class.id
此时没有任何索引,性能肯定不佳。左外连接的索引要建立在left join后的表上的相关列。在这个查询语句中,索引就应该就立在class表的id列。建立索引后执行查询分析可得下图:

索引优化法则(技巧)
1.尽量全值匹配
全值匹配,意思就是索引建啥我查啥。例如建立索引:
CREATE index idx_nap ON staffs(name,age,position);
那么根据全值匹配法则,下列语句是较优的:
SELECT name FROM staffs WHERE name = 'sam';
SELECT name,age FROM staffs WHERE name = 'sam' AND age = 23;
SELECT name,age,position FROM staffs WHERE name = 'sam' AND age = 23 AND position = 'CEO';
在此法则下,不管是待查询的列(select后的语句),还是检索条件(where后的语句),所涉及的列都是索引中的列。
2.最佳左前缀法则
以上面的索引为例,建立的复合索引顺序是name,age,position。就像是开火车一样,name是车头,name不在后面的车厢就不会起作用。同样的,age若不在,就会只剩车头name,position会作为车尾与火车脱节。因此以下的查询会有一个或者多个索引失效(注意:最后一个索引有效):
SELECT name FROM staffs WHERE age = 23; //索引失效
SELECT name FROM staffs WHERE position = 'CEO'; //索引失效
SELECT age,position FROM staffs WHERE age = 23 AND position = 'CEO'; //索引失效
SELECT name,position FROM staffs WHERE name = 'sam' AND position = 'CEO'; //name索引生效,position索引失效
SELECT name,age,position FROM `staffs` WHERE age = 23 AND name = 'sam' AND position = 'CEO'//使用到索引,where后面顺序可以颠倒。
3.不在建索引的列上做任何操作
接上表staffs可知,单独为name建立一个索引。那么下列语句会使用到索引
SELECT * FROM staffs WHERE name = 'sam';
如果将其中where语句后面的条件改为如下语句时,索引则会失效。
SELECT name FROM staffs WHERE LEFT(name,3) = 'sam'; //匹配name字段左边三个字符符合sam的所有行
4.范围条件右边的索引会失效
同样是staffs表,建立的复合索引顺序是name,age,position。如下语句则会使用到索引:
SELECT name,age,position FROM staffs WHERE name = 'sam' AND age = 23 AND position = 'CEO';
但是,将age条件改为>23,那么age后的position索引会失效。
SELECT name,age,position FROM staffs WHERE name = 'sam' AND age > 23 AND position = 'CEO';
在上面SQL中,name列的索引被用于查找,age列的索引被用于排序。而position列的索引会失效。
5.尽量使用覆盖索引
同第一条法则
6.MySQL在使用!=或者<>会导致索引失效
不解释,简单。
7.is null和is not null无法使用索引
使用staffs表,建立name单值索引。
SELECT name FROM staffs WHERE name IS NULL;
SELECT name FROM staffs WHERE name IS NOT NULL;
8.like以通配符%开头会导致索引失效
使用staffs表,建立name单值索引。以下语句会使索引失效。
SELECT name FROM staffs WHERE name LIKE '%sa%';
SELECT name FROM staffs WHERE name LIKE '%sa';
对第一句使用explain查询得到分析结果如下:

可见,使用到了全表扫描。但是在具体业务逻辑中有时必须要用到%xxx%的查询条件,那么该如何优化呢?解决方案是建立与name相关联的复合索引,并使用覆盖索引查询(即查询字段被复合索引包括且符合最佳左前缀法则)。这里建立name,age复合索引。此时执行上面的查询语句得到如下结果:

可见,由全表扫描变为了全索引扫描,在性能上比全表扫描好了许多。
9.字符串不加引号索引失效
使用staffs表,建立name单值索引,在针对name进行查询时候,如下语句会导致索引失效:
SELECT name,age,position FROM staffs WHERE name = sam
该语句能够正确查询出结果,是因为MySQL内部会为sam字段做了类型转换。而恰恰是类型转换会使索引失效。所以记得加上引号。
10.用or关键词会使得索引失效
SELECT name,age,position FROM staffs WHERE name = 'sam' or name = 'lisa';
