1.语言模型
语言模型仅仅对句子出现的概率进行建模,并不尝试去“理解”句子的内容含义。语言模型告诉我们什么样的句子是常用句子(挑选较为合理的句子的作用),但无法告诉我们两句话的意思是否相似或者相反。
SeqSeq模型可以看作一个条件语言模型,它相当于是在给定输入的情况下对目标语言的所有句子估算概率,并选择其中概率最大的句子作为输出。
假设一门语言的词汇量为V,如果将p(Wm|W1,W2,W3,…Wm-1)的所有参数保存在一个模型里,将需要V ** m 个参数。
为了控制参数数量,n-gram模型做了一个假设:当前单词的出现概率仅仅与前面的n-1个单词相关。(n通常取1、2、3、4)
那么n-gram模型需要估计的不同参数数量为O(V ** n)量级。当n越大时,n-gram模型在理论上越准确。但也越复杂,需要的计算量和训练语料数据量也就越大,因此n>=4的情况非常少。
n-gram模型的参数一般采用最大似然估计(MLE)方法计算。为了避免乘以0而导致整个句概率为0,使用最大似然估计方法时需要加入平滑避免参数取值为0。
语言模型好坏的常用评价指标是复杂度(perplexity)。在一个数据集上得到的perplexity越低,说明建模的效果越好。perplexity实际是计算每一个单词得到的概率倒数的几何平均(模型预测下一个词时的平均可选择数量)。目前在PTB数据集上最好的语言模型perplexity为47.7,也就是说,平均情况下,该模型预测下一个词时,有47.7个词等可能地可以作为下一个词的合理选择。
在语言模型训练中,通常采用perplexity的对数表达形式,相比于乘积求平方根的方式,使用加法形式,可以加速计算,同时避免概率乘积数值过小而导致浮点数向下溢出的问题。
在数学上,log perplexity 可以看成真实分布与预测分布之间的交叉熵。(交叉熵描述了两个概率分布之间的一种距离)
2.神经语言模型
n-gram模型为了控制参数变量,需要将上下文信息控制在几个单词之内。
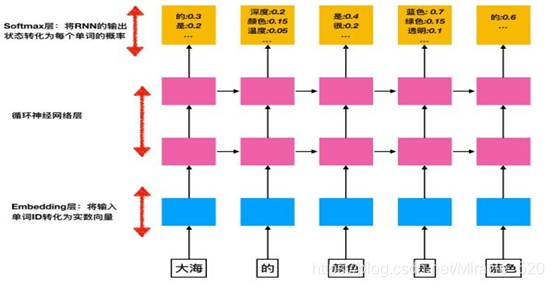
RNN,每个时刻的输入为一个句子中的单词wi,而每个时刻的输出为一个概率分布,将每个位置上的概率取对数再平均起来,就可以得到在这个句子上计算的log perplexity。
tf.nn.sparse_softmax_cross_entropy_with_logits与tf.nn.softmax_cross_entropy_with_logits函数的区别
import tensorflow as tf
# 假设词汇表的大小为3 ,语料库包含两个单词2,0
word_labels = tf.constant([2, 0])
# 计算概率用tf.nn.softmax()
predict_logits = tf.constant([[2.0, -1.0, 3.0], [1.0, 0.0, -0.5]])
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=word_labels, logits=predict_logits)
sess = tf.Session()
sess.run(loss)
# 需要将预测目标以概率分布的形式给出
word_prob_distribution = tf.constant([[0.0, 0.0, 1.0], [1.0, 0.0, 0.0]])
loss = tf.nn.softmax_cross_entropy_with_logits(
labels=word_prob_distribution,
logits=predict_logits
)
print(sess.run(loss))
sess.close()
2.1PTB数据集的预处理
将文本转化为模型可以读入的单词序列,需要将这10000个不同的词汇分别映射到0~9999之间的整数编号。
- 统计单词出现的频率,并从词汇表中去除低频词,将低频词用替换。
- 将每个单词换成词汇表中的编号。
2.2PTB数据的batching方法
序列过长可能会造成训练中的梯度爆炸的问题。对此问题的解决方法是,对长序列切割为固定长度的子序列。RNN在处理完一个子序列后,它将最终的隐藏状态将复制到下一个序列中作为初始值,这样在前向计算时,效果等同于一次性顺序地读取了整个文档;而在反向传播时,梯度则只在每个子序列内部进行传播。
2.3基于RNN的神经语言模型
词向量层:
在输入层,每一个单词用一个实数向量表示,这个向量被称为“词向量”(word embedding)也可以翻译为词嵌入。词向量可以形象的理解为将词汇表嵌入到一个固定维度的实数空间中。
将单词编号转换为词向量主要有两个作用:
- 降低输入的维度。如果不使用词向量层,而直接将单词以one-hot vector的形式输入,那么输入的维度大小将与词汇表大小相同,通常在10000以上。而词向量的维度通常在200-1000之间,这将大大减少RNN的参数数量与计算量。
- 增加语义信息。学习到的词向量通常会将含义相近的词赋予取值相近的词向量值,使得上层的网络可以更容易地抓住相似单词之间的共性。
3.神经网络机器翻译
** 语言模型的基本方法是由一个循环神经网络每一步预测一个单词来实现的,在训练时采用log perplexity作为优化的目标函数。机器翻译的Seq2Seq模型可以看作增加了一个编码器的语言模型,其中编码器和解码器各自由一个循环神经网络实现。注意力机制在Seq2Seq的基础上增加了对单词编码的动态查询,使得解码器不必完全依赖于循环神经网的隐藏状态来存储所有信息。
