Hashtable 的概念:字符串的键先会被传递给一个 hash 函数(hashing function,中文也翻译为散列函数),然后这个函数会返回一个整数,而这个整数就是“通常”的数组的索引,通过这个数字索引可以访问到 字符串的键对应的数据。
本质上PHP的数组是有序的字典,表示k-v对的是有序列表,其中k-v映射是使用hashTable实现的,PHP将字符串key通过哈希函数运算返回一个整数,这个整数倍用作普通数组的索引,但是可能存在hash冲突,其中HashTable需要实现某种机制来解决冲突
关于 HashTable 的几个概念
- 键(key):用于操作数据的标示,例如PHP数组中的索引,或者字符串键等等。
- 槽(slot/bucket):哈希表中用于保存数据的一个单元,也就是数据真正存放的容器。
- 哈希函数(hash function):将key映射(map)到数据应该存放的slot所在位置的函数。
- 哈希冲突(hash collision):哈希函数将两个不同的key映射到同一个索引的情况。
PHP使用了双向链表和Hash表结合的方式实现HashTable,这使得HashTable能够在O(1)的时间复杂度上实现任意key的查询,同时又可以支持HashTable的遍历。
接下来看看HashTable的定义,大致做了下注释,和鸟哥的注释是一样的:
//zend_types.h
typedef struct _Bucket {
zval val;
zend_ulong h; /* hash value (or numeric index) 哈希算法算出 */ 来的hash值
zend_string *key; /* string key or NULL for numerics */
} Bucket;
typedef struct _zend_array HashTable;
struct _zend_array {
zend_refcounted_h gc;
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount,
zend_uchar nIteratorsCount,
zend_uchar reserve)
} v;
uint32_t flags;
} u;
uint32_t nTableMask; //哈希值计算掩码,等于nTableSize的负值(nTableMask = ~nTableSize + 1),计算最终落在那个Bucket的值
Bucket *arData; //存储元素数组,指向第一个Bucket,数组中每个元素都是Bucket
uint32_t nNumUsed; //arData数组已经使用的数量,已用Bucket数
uint32_t nNumOfElements; //哈希表已有元素数
uint32_t nTableSize; //哈希表总大小,为2的n次方
uint32_t nInternalPointer;//内部的指针,用于HashTable遍历
zend_long nNextFreeElement; //下一个可用的数值索引,如:arr[] = 1;arr["a"] = 2;arr[] = 3; 则nNextFreeElement = 2;
dtor_func_t pDestructor; // 析构函数
};HashTable中有两个非常相近的值:nNumUsed、nNumOfElements,nNumOfElements表示哈希表已有元素数,那这个值不跟nNumUsed一样吗?为什么要定义两个呢?
实际上它们有不同的含义,在hashtable中保存了5个元素,arData[0]到arData[4]的槽(slot)会被用到,下一个空闲槽是arData[5]。这个数字会记录在nNumUsed中,当将一个元素从哈希表删除时并不会将对应的Bucket移除,而是将Bucket存储的zval标示为IS_UNDEF,只有扩容时发现nNumOfElements与nNumUsed相差达到一定数量(这个数量是:ht->nNumUsed - ht->nNumOfElements > (ht->nNumOfElements >> 5))时才会将已删除的元素全部移除,重新构建哈希表。所以nNumUsed>=nNumOfElements。
HashTable中另外一个非常重要的值arData,arData数组保存了所有的buckets(也就是数组的元素),这个数组被分配的内存大小为2的幂次方,它被保存在nTableSize这个字段(最小值为8)。这个值指向存储元素数组的第一个Bucket,插入元素时按顺序依次插入数组,比如第一个元素在arData[0]、第二个在arData[1]…arData[nNumUsed],这跟元素对应的键没有任何关系,这只跟插入的顺序相关。PHP数组的有序性正是通过arData保证的。
哈希表实现的关键是有一个数组存储哈希值与Bucket的映射,但是HashTable中并没有这样一个索引数组。
实际上这个索引数组包含在arData中,索引数组与Bucket列表一起分配,arData指向了Bucket列表的起始位置,而索引数组可以通过arData指针向前移动访问到,即arData[-1]、arData[-2]、arData[-3]……索引数组的结构是uint32_t,它存储的是Bucket元素在arData中的位置。
所以,整体来看HashTable主要依赖arData实现元素的存储、索引。插入一个元素时先将元素插入Bucket数组,位置是idx,再根据key的哈希值与nTableMask计算出索引数组的位置,将idx存入这个位置;查找时先根据key的哈希值与nTableMask计算出索引数组的位置,获得元素在Bucket数组的位置idx,再从Bucket数组中取出元素。
结构图:

arData指向一个数组,数组里面是由一个个Bucket,Bucket里面存的是key-value对
散列算法:通过key算出一个散列值,然后以tableMask进行或运算,然后就可以保证元素散列到我们指定的Bucket上
在Bucket前面有一个个索引,其中Bucket记录着一个个的key-value对,这样做的原因是
1、前面的索引记录的key对应的位置,这样我就能根据我的散列记录我的key在那个bucket上
2、如果发生冲突我就能根据前面的索引建立一个逻辑上的链表,也就是拉链法进行解决冲突
插入和查找示例图:

对于nTableMask刚初始化是-8,索引数组都是-1,所以或上的值肯定在索引数组里面,
插入和查找 $a['foo']=1: 假如nIndex=-7,然后到索引第七个位置,首先因为保证数组插入的顺序,因为我们进行foreach的时候还要根据插入的顺序遍历出来,所以我们 第一个元素 $a['foo']=1肯定存在第0的位置,这里的key位foo,但是实际上存的是指向zend_string的指针,然后会把0的位置写到-7。当我查找的时候,先取h值或上nTableMask,得到-7,然后从索引数组里面找到-7的位置为0,然后在第0的bucket里面找
插入和查找 $a[]=2:这个时候我们看到nNextFreeElement的值为0,这个时候我们算出来nIndex的值为-8,放到了第一位置,这个时候因为没有key,h=0,然后1写到前面-8的位置,里面nNumUsed和nNumofelement+1变成2,同时nNextFreeElement变成1
插入和查找 $a[‘s’]=3:假设nIndex=-7,这个时候发生了hash冲突,索引数组-7的位置变成了2,这个时候找不到foo的值,所以里面的位置是val.u2.next=0如果不相等继续往下找,通过索引数组的next值建立了一个逻辑上的链表,
冲突解决办法是拉链法,并且是头插法,最后来的放在最前面
Packed Array和Hash Array

PHP中的所有数组都使用了Hashtable。不过在通常情况下,对于连续的、整数索引的数组(真正的数组)而言,这些hash的东西没多大意义,所以PHP 7中引入了“packed hashtables”这个概念
Packed Array: 后面是bucket,前面是索引数组,但是前面的索引数组用不着,因为packed Array是从 0123..这样递增的,所以不需要算hash值 TableMask:为-2
Hash Array:因为key,不是顺序递增的,所以算出这个值需要维护索引的数组
需要注意的是,即使是整数索引的数组,PHP也必须维持它的顺序。数组[0=>1,1=>2]和数组[1=>2,0=>1]并不是相同。packed hashtable只会作用于键递增的数组,这些数组的key之间可以有间隔,但必须总是递增的。所以如果一个元素以一个”错误“的顺序(例如逆序)插入到数组中,那么packed hashtable就不会被用到。
rehash 扩容
rehash中,在扩展容器本身的容量时,每个对象(key,value)的位置也会相应的发生调整。
哈希表的大小为2^n,插入时如果容量不够则首先检查已删除元素所占比例,如果达到阈值(ht->nNumUsed - ht->nNumOfElements > (ht->nNumOfElements >> 5),则将已删除元素移除,重建索引,如果未到阈值则进行扩容操作,扩大为当前大小的2倍,将当前Bucket数组复制到新的空间,然后重建索引。
//zend_hash.c
static void ZEND_FASTCALL zend_hash_do_resize(HashTable *ht)
{
IS_CONSISTENT(ht);
HT_ASSERT(GC_REFCOUNT(ht) == 1);
if (ht->nNumUsed > ht->nNumOfElements + (ht->nNumOfElements >> 5)) { //只有到一定阈值才进行rehash操作
HANDLE_BLOCK_INTERRUPTIONS();
zend_hash_rehash(ht); //重建索引数组
HANDLE_UNBLOCK_INTERRUPTIONS();
} else if (ht->nTableSize < HT_MAX_SIZE) { //扩大为两倍
void *new_data, *old_data = HT_GET_DATA_ADDR(ht);
uint32_t nSize = ht->nTableSize + ht->nTableSize;
Bucket *old_buckets = ht->arData;
HANDLE_BLOCK_INTERRUPTIONS();
new_data = pemalloc(HT_SIZE_EX(nSize, -nSize), ht->u.flags & HASH_FLAG_PERSISTENT); //新分配arData空间,大小为:(sizeof(Bucket) + sizeof(uint32_t)) * nSize
ht->nTableSize = nSize;
ht->nTableMask = -ht->nTableSize; //nTableSize负值
HT_SET_DATA_ADDR(ht, new_data); //将arData指针偏移到Bucket数组起始位置
memcpy(ht->arData, old_buckets, sizeof(Bucket) * ht->nNumUsed); //将旧的Bucket数组拷到新空间
pefree(old_data, ht->u.flags & HASH_FLAG_PERSISTENT); //释放旧空间
zend_hash_rehash(ht); //重建索引数组
HANDLE_UNBLOCK_INTERRUPTIONS();
} else {
zend_error_noreturn(E_ERROR, "Possible integer overflow in memory allocation (%zu * %zu + %zu)", ht->nTableSize * 2, sizeof(Bucket) + sizeof(uint32_t), sizeof(Bucket));
}
}
#define HT_SET_DATA_ADDR(ht, ptr) do { \
(ht)->arData = (Bucket*)(((char*)(ptr)) + HT_HASH_SIZE((ht)->nTableMask)); \
} while (0)
重建索引
当删除元素达到一定数量或扩容后都需要进行索引数组的重建,因为元素所在Bucket位置移动了或哈希数组nTableSize变化了导致原哈希索引变化,已删除的元素将重新可以分配。
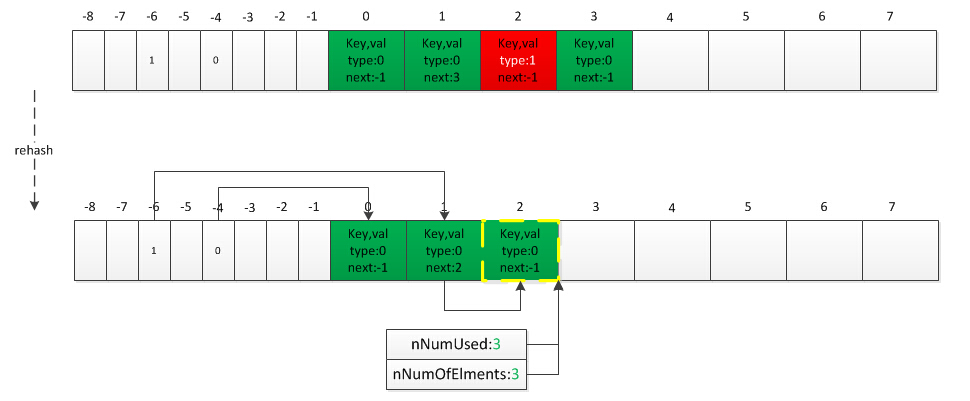
//zend_hash.c
ZEND_API int ZEND_FASTCALL zend_hash_rehash(HashTable *ht)
{
Bucket *p;
uint32_t nIndex, i;
...
i = 0;
p = ht->arData;
if (ht->nNumUsed == ht->nNumOfElements) { //没有已删除的直接遍历Bucket数组重新插入索引数组即可
do {
nIndex = p->h | ht->nTableMask;
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(i);
p++;
} while (++i < ht->nNumUsed);
} else {
do {
if (UNEXPECTED(Z_TYPE(p->val) == IS_UNDEF)) {//有已删除元素需要将其移到后面,压实Bucket数组
......
while (++i < ht->nNumUsed) {
p++;
if (EXPECTED(Z_TYPE_INFO(p->val) != IS_UNDEF)) {
ZVAL_COPY_VALUE(&q->val, &p->val);
q->h = p->h;
nIndex = q->h | ht->nTableMask;
q->key = p->key;
Z_NEXT(q->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(j);
if (UNEXPECTED(ht->nInternalPointer == i)) {
ht->nInternalPointer = j;
}
q++;
j++;
}
}
......
ht->nNumUsed = j;
break;
}
nIndex = p->h | ht->nTableMask;
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(i);
p++;
}while(++i < ht->nNumUsed);
}
}
