学习DOTS之High Performance C# (HPC#)
Microsoft Certified Trainer
As a C# Performance Architect, your job is to create solution architectures that provide the best possible performance for your business or organization. And to do your job well, you’ll need a solid understanding of basic C# code optimizations.
In this post, we’ll look at structs and classes in C#. Understanding the performance difference between these two will help you pick the correct code for every occasion.
Take a look at the following code.
- public class PointClass
- {
- public int X { get; set; }
- public int Y { get; set; }
- public PointClass(int x, int y)
- {
- X = x;
- Y = y;
- }
- }
It’s a simple class that contains two public integer properties and a constructor to initialize them. You’ll typically find classes like this in graph libraries, to store data points in a chart.
But wait! There’s another way of doing this. Check out this code:

- public struct PointStruct
- {
- public int X { get; set; }
- public int Y { get; set; }
- public PointStruct(int x, int y)
- {
- X = x;
- Y = y;
- }
- }
It’s the exact same code, I just changed class to struct.
So what do you think is better? A class or a struct?
In both cases, I have a data structure that contains two integers for storing an X- and Y coordinate pair. In terms of memory use and code performance, you’d expect similar results, right?
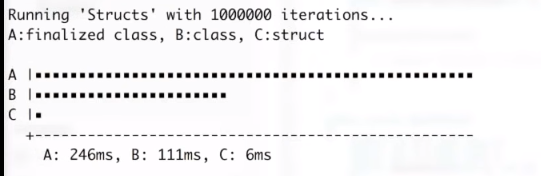
Well, let’s find out. I’ve coded a quick benchmark to compare the two:
Did you see the results? The class benchmark took 111 milliseconds. But the struct benchmark took only 6 milliseconds, so structs are 18.5 times faster than classes!
As an extra twist, I added a finalizer to the PointClass class. That benchmark took 246 milliseconds, so the finalizer made my code run another 2.2 times slower.
That’s a huge difference.
Here’s what’s going on. When I store a list of PointClass instances on the heap, the memory layout looks like this:
The list reference is in a local variable, so it’s stored on the stack. It points to a List<PointClass> instance on the heap.
But here’s the twist: PointClass is a reference type, so it’s stored elsewhere on the heap. The list only maintains an array of object references that point to PointClass instances stored elsewhere on the heap.
When you access a specific item in the list, the .NET runtime needs to first calculate where that list item is stored, then retrieve that particular object reference, and then ‘follow’ the reference to get at the PointClass instance.
When the list goes out of scope, the .NET garbage collector has to dispose up the list and every single PointClass instance to reclaim the memory. When I added a finalizer, I slowed that process down even further. The .NET Framework runs finalizers on a single thread, so that thread had to process each list item in turn before it could reclaim the memory.
Now compare that to the memory layout of a list of structs:
Structs are value types, which means they are stored inline inside their containing data type. So now all PointStruct instances are stored inside the list itself. There is only a single object on the heap.
When you access a specific item in the list, the .NET runtime calculates where that list item is stored, and then retrieve the struct directly because it’s stored right there, inside the list array.
And when the list goes out of scope, the .NET garbage collector now only needs to dispose a single object.
All these savings add up. My benchmarks repeatedly filled up huge lists with structs and classes, and it made the class-benchmark run more than 18 times slower than the struct-benchmark.
So when should you use a struct, and when should you use a class?
Here’s what you need to do:
- When you’re storing more than 30-40 bytes of data, use a class.
- When you’re storing reference types, use a class.
- When your list isn’t very large, use a class.
- When you list is long-lived, use a class.
- In all other cases, use structs instead.
For versus Foreach in C#
As a C# Performance Architect, your job is to create solution architectures that provide the best possible performance for your business or organization. And to do your job well, you’ll need a solid understanding of basic C# code optimizations.
In this post, we’ll look at the different types of loops in C#. Understanding the difference will help you pick the correct code fragment for every occasion.
Take a look at the following code.
- static void Main(string[] args)
- {
- var list = GetSomeLargeList();
- foreach (int number in list)
- {
- // do something with number
- }
- }
It’s a simple foreach-loop that sequentially iterates through each element in a large list of integers.
But wait! There’s another way of doing this. Check out this code:
- static void Main(string[] args)
- {
- var list = GetSomeLargeList();
- for (int i=0; i < list.Count; i++)
- {
- var number = list[i];
- // do something with number
- }
- }
It’s basically the same code, but now I’m using a normal for-loop to iterate through the numbers.
Which code do you think is faster?
It’s pretty much the same code. Either I am using foreach, or I’m using for. But in both cases, I need to loop through each element in the list. So you would expect the same execution time, right?
Well, check it out. I’ve coded a quick benchmark to compare the two:
Did you see the results? The first benchmark with the foreach-loop took 273 milliseconds. The second benchmark with the for-loop took only 112 milliseconds. The for-loop is 2.4 times faster than the foreach-loop.
That’s a big difference. The reason becomes clear when we look at foreach in detail. What looks like a simple loop on the outside is actually a complex data structure called an enumerator:
An enumerator is a data structure with a Current property, a MoveNext method, and a Reset method. The Current property holds the value of the current element, and every call to MoveNext advances the enumerator to the next item in the sequence.
Enumerators are great because they can handle any iterative data structure. In fact, they are so powerful that all of LINQ is built on top of enumerators.
But the disadvantage of enumerators is that they require calls to Current and MoveNext for every element in the sequence. All those method calls add up, especially in mission-critical code.
Conversely, the for-loop only has to call get_Item for every element in the list. That’s one method call less than the foreach-loop, and the difference really shows.
So when should you use a foreach-loop, and when should you use a for-loop?
Here’s what you need to do:
- When you’re using LINQ, use foreach
- When you’re working with very large computed sequences of values, use foreach
- When performance isn’t an issue, use foreach
- But if you want top performance, use a for-loop instead
Array Types In C#
As a C# Performance Architect, your job is to create solution architectures that provide the best possible performance for your business or organization. And to do your job well, you’ll need a solid understanding of basic C# code optimizations.
In this post, we’ll look at the different types of arrays in C#. Understanding the difference will help you pick the correct data structure for every occasion.
Take a look at the following code.
- static void Main(string[] args)
- {
- var array = new int[SIZE, SIZE, SIZE];
- for (int i=0; i < SIZE; i++)
- {
- for (int j=0; j < SIZE; j++)
- {
- for (int k=0; k < SIZE; k++)
- {
- array[i, j, k]++;
- }
- }
- }
- }
It’s a simple 3-way nested loop that increments every item in the multidimensional array.
But wait! There’s another way of doing this. Check out this code:
- static void Main(string[] args)
- {
- var array = new int[SIZE * SIZE * SIZE];
- for (int i=0; i < SIZE; i++)
- {
- for (int j=0; j < SIZE; j++)
- {
- for (int k=0; k < SIZE; k++)
- {
- var index = k + SIZE * (j + SIZE * i);
- array[index]++;
- }
- }
- }
- }
It’s basically the same code, but now I’ve flattened the array into a 1-dimensional data structure. I still have the three loop variables, so I’m using a new variable index to calculate the index of the array element to increment.
Which code do you think is faster?
It’s pretty much the same code. Either I am doing the array element index calculation myself, or I use a 3-dimensional array and let the .NET runtime do it for me. But in both cases, it’s the same expression. So you wouldn’t expect any difference, right?
Well, check it out. I’ve coded a quick benchmark to compare the two:
Did you see the results? The first benchmark with the multidimensional array took 125 milliseconds. The second benchmark with the flattened array took only 93 milliseconds. Flattening the array sped up my code by about 26%.
That’s quite a difference. The reason becomes clear when we look at the compiled code. This is what the first code fragment compiles to:
- // compute memory address of array element
- IL_0024: ldloc.0
- IL_0025: ldloc.1
- IL_0026: ldloc.2
- IL_0027: ldloc.3
- IL_0028: callvirt instance int32& int32[,,]::Address(int32, int32, int32)
- // increment array element
- IL_002d: dup
- IL_002e: ldind.i4
- IL_002f: ldc.i4.1
- IL_0030: add
- IL_0031: stind.i4
The runtime simply calls the class method int32[,,]::Address to calculate the memory address of the array element, and then increments it. Pretty straightforward.
This is what the second code fragment compiles to:
- // index = k + SIZE * (j + SIZE * i)
- IL_0026: ldloc.3
- IL_0027: ldc.i4 300
- IL_0030: ldloc.2
- IL_0031: ldlc.i4 300
- IL_0034: ldloc.1
- IL_0035: mul
- IL_0036: add
- IL_0037: mul
- IL_0038: add
- IL_0039: stloc.s 4
- // increment array[index]
- IL_0041: ldloc.0
- IL_0042: ldloc.s 4
- IL_0044: ldelema [System.Runtime]System.Int32 // <-- look at this
- IL_0048: dup
- IL_0049: ldlind.i4
- IL_004a: ldc.i4.1
- IL_004b: add
- IL_004c: stind.i4
Note that there isn’t a single method call in the compiled code. The runtime calculates the array index expression and then uses a specialized IL instruction ldelema to load the address of the array element. Once the address is known, the runtime uses the same ldind and stind instruction pair to increment the memory location.
Not having to call the int32[,,]::Address method but having a specialized IL instruction for calculating the array item address is a small optimization. But in mission-critical loops, it can really add up.
So here’s what you need to do:
- For non-critical code, feel free to use multidimensional arrays.
- But if you need optimal performance, consider flattening your arrays and grab that extra 26% speed boost.
Strings versus StringBuilders In C#
As a C# Performance Architect, your job is to create solution architectures that provide the best possible performance for your business or organization. And to do your job well, you’ll need a solid understanding of basic C# code optimizations.
In this post, we’ll look at two ways to concatenate strings. Understanding the difference between these two methods will help you pick the correct strategy for every occasion.
Take a look at the following code.
- static void Main(string[] args)
- {
- string result = string.Empty;
- for (int i=0; i < SOME_LARGE_NUMBER; i++) {
- result += "*";
- }
- }
I start with an empty string result and add an asterisk character to it in a loop. The loop itself repeats many times, leading to thousands or perhaps even millions of individual string concatenations.
But wait! There’s another way of doing this.
Check out the following code:
- static void Main(string[] args)
- {
- StringBuilder result = new StringBuilder();
- for (int i=0; i < SOME_LARGE_NUMBER; i++) {
- result.Append("*");
- }
- }
So now I’m using a StringBuilder instead, and inside the loop I’m using the Append() method to add the asterisk.
Pretty much the same code, right? So which one do you think is faster?
I’ve coded a quick benchmark to compare the two parse methods. Take a look:
Did you see the results? The first benchmark used strings and performed 50,000 concatenations in half a second. The second benchmark used a StringBuilder instead, and it completed 100,000,000 concatenations in 0.45 seconds. The string code was a whopping 2000 times slower than the StringBuilder code!
That’s a massive difference. The reason is that strings are immutable. When you modify a string, the .NET framework creates an entirely new string on the heap and leaves the original unchanged. So my string benchmark code had to allocate and copy 50,000 strings on the heap. That really adds up.
Conversely, the StringBuilder class simply allocates a buffer in memory and writes data directly into it. This is much faster and makes StringBuilders ideally suited for building large strings.
You might be wondering if you should always use StringBuilders instead of strings, even when you’re only doing two or three additions? Should you chuck out all of your String.Format calls and replace everything with StringBuilders?
Well, check out the following comparison:
For up to 5 additions, using strings is actually faster. This is because there’s some overhead involved in setting up a new StringBuilder, and for a small number of additions the string class can still outperform the StringBuilder. But at 6 or more additions, the StringBuilder starts outperforming strings.
So here’s what you need to do:
- For a small number of additions, stick to using strings.
- When you’re doing more than 5 additions, use a StringBuilder instead
The Exception Penalty In C#
As a C# Performance Architect, your job is to create solution architectures that provide the best possible performance for your business or organization. And to do your job well, you’ll need a solid understanding of basic C# code optimizations.
In this post, we’ll look at the overhead of throwing and catching exceptions in your code. Catching exceptions will slow down your code a lot, so it’s very important to have a clear understanding of your error-handling strategy.
Take a look at the following code.
- static void Main(string[] args)
- {
- string input = GetInputData();
- try {
- int result = int.Parse(input);
- // do something with result
- }
- catch (FormatException) {
- // suppress the exception
- }
- }
I’m calling the method GetInputData() which returns a string. This can be either a valid or invalid integer, so I’m parsing the data using int.Parse() and catch any FormatExceptionthat might get thrown.
But wait! There’s another way of doing this.
Check out the following code:
- static void Main(string[] args)
- {
- string input = GetInputData();
- int result = -1;
- bool valid = int.TryParse(input, out result);
- if (valid) {
- // do something with result
- }
- }
Pretty much the same code, right? Not much difference between the two.
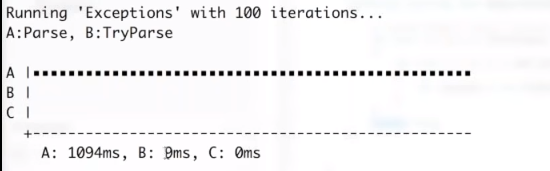
Think again! I’ve coded a quick benchmark to compare the two parse methods. Take a look:
Did you see the results? The code that catches the exception is 121 times slower than the code that uses int.TryParse().
That’s a massive difference. The reason is that exceptions are meant for diagnostics and debugging. When you throw an exception, the .NET runtime takes a snapshot of the thread state and stack trace, and then unwinds the stack until it encounters a matching catch block. This process is really slow, on average it takes about a microsecond. Almost an eternity at CPU scale.
To avoid this slowdown, stick to these three tips:
- Don’t use exceptions for control flow (duh)
- Use the TryXXX methods when parsing dirty input data
- Never suppress exceptions in mission-critical code
Basically, only throw exceptions if you want code execution to stop, period.
How To Avoid Boxing And Unboxing In C#
As a C# Performance Architect, your job is to create solution architectures that provide the best possible performance for your business or organization. And to do your job well, you’ll need a solid understanding of basic C# code optimizations.
In this post, we’ll look at a process called ‘Boxing’, which blurs the line between value types and reference types. Unexpected boxing can slow down your code a lot, so it’s very important to have a clear understanding of what boxing is and when it happens.
Take a look at the following code.
- static void Main(string[] args)
- {
- int a = 1234;
- object b = a; // <--- how can this work?
- }
I have a variable a containing the value 1234. Then I declare a second variable b of type object and assign a to b. This should work, because in C# all types inherit from object, including integers. So I can assign anything to my object type variable.
But wait! Integers are value types, and objects are reference types. So in memory, my variables are stored like this:
Integers are value types, so they store their value inline with the variable itself. I’ve declared a as a local variable so it lives on the stack, and because it’s a value type, the value ‘1234’ is also stored on the stack.
Objects are reference types, so they store a reference to heap memory where the object data is stored. I’ve declared b as a local variable, so the reference itself is stored on the stack, but the reference can only point to a location in heap memory.
So now we have a problem. The number 1234 is stored on the stack, but objects can only refer to heap memory. How is the assignment possible?
To make this work, the framework uses a process called boxing. Here’s what that looks like in memory:
The .NET Framework copies the integer value from the stack, packs it into an object, and stores it on the heap. Now, b has something to refer to – the new integer object on the heap.
Boxing happens every time behind the scenes when you have a variable, parameter, field or property of type object, and you assign value type data to it. Boxing is nice because it blurs the line between value types and reference types, but it can also be a pain because it introduces extra overhead and slows your code down.
You might be wondering if there is a corresponding process called ‘unboxing’?
Yes, there is. Check out this code:
- static void Main(string[] args)
- {
- int a = 1234;
- object b = a; // <--- boxing happens here
- int c = (int)b; // <--- but how can this work?
- }
Here I declare a new integer variable c and cast the object value into it. But c is a value type on the stack, whereas b refers to a boxed integer on the heap. How does this work?
You’ve probably guessed that it will look something like this:
This process is called unboxing. The framework takes the packaged integer object on the heap, and copies its value back to the stack into variable c.
Boxing and unboxing operations are pretty fast, because they only copy a tiny amount of memory between the stack and the heap. But in mission-critical loops all those memory operations will start to add up. You will also be putting more pressure on the garbage collector to remove all the packaged value types from the heap.
In my benchmarks, I’ve found that boxing and unboxing can make your code run 5 times slower than normal.
But boxing is easy to avoid. Just stick to these three tips:
- Avoid object types in mission-critical code.
- If you do have to use object types, don’t assign any value type data to them
- And don’t use structs with interfaces in mission-critical code
Surprised by that third tip? Remember that structs are value types and an interface is a reference type. Casting a struct to an interface will trigger a boxing operation!
How to Write Very Fast C# Code






























![]()
High performance IO with System.IO.Pipelines











https://www.nuget.org/packages/System.IO.Pipelines/



























