数据离散
pd.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates=‘raise’)
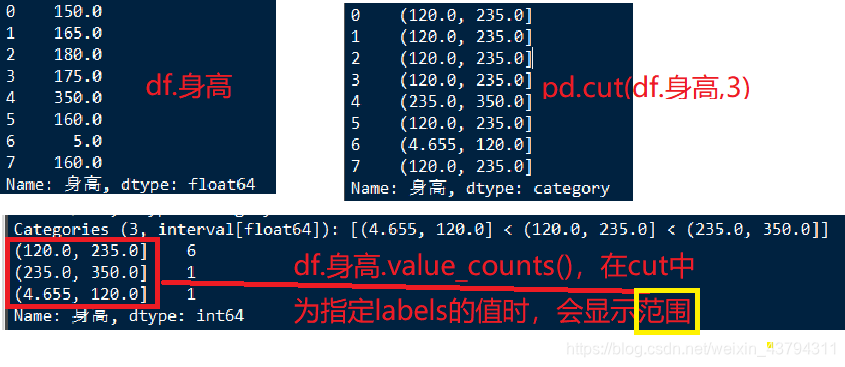
需要注意的是,当cut()函数未给定labels的参数时,下面的value_counts()会显示分组的范围。x必须是一维数组
import pandas as pd
import numpy as np
df=pd.read_csv('test_innom.csv',encoding='gbk')
print(df.身高)
df.身高=pd.cut(df.身高,3,labels=range(1,4))
print(df.身高)
print(df.身高.value_counts())
按分位数平均散列pd.qcut(x, q, labels=None, retbins=False, precision=3, duplicates=‘raise’)
x:一维数组数据或series数据
q:整数或分位数的百分比(0.1,0.25…),注意的是,分位数的百分比的个数应该比分的段数多一个数据
labels:指的是分组的名称
