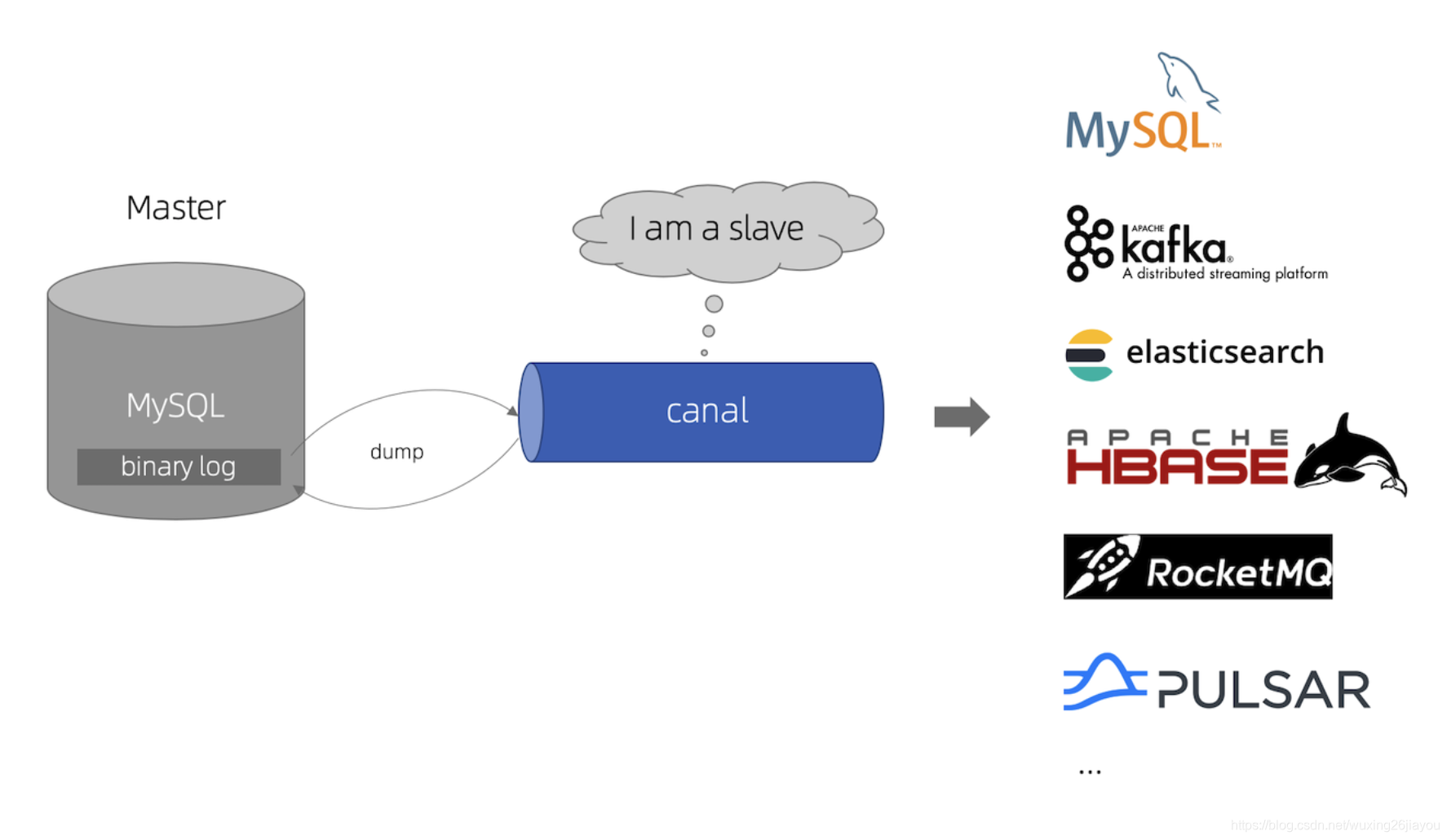
 简介
简介
canal主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费,应用场景十分丰富。
常用场景
- 电商场景下商品、用户实时更新同步到至Elasticsearch、solr等搜索引擎;
- 价格、库存发生变更实时同步到redis;
- 数据库异地备份、数据同步;
- 代替使用轮询数据库方式来监控数据库变更,有效改善轮询耗费数据库资源。
工作原理
MySQL主备复制原理
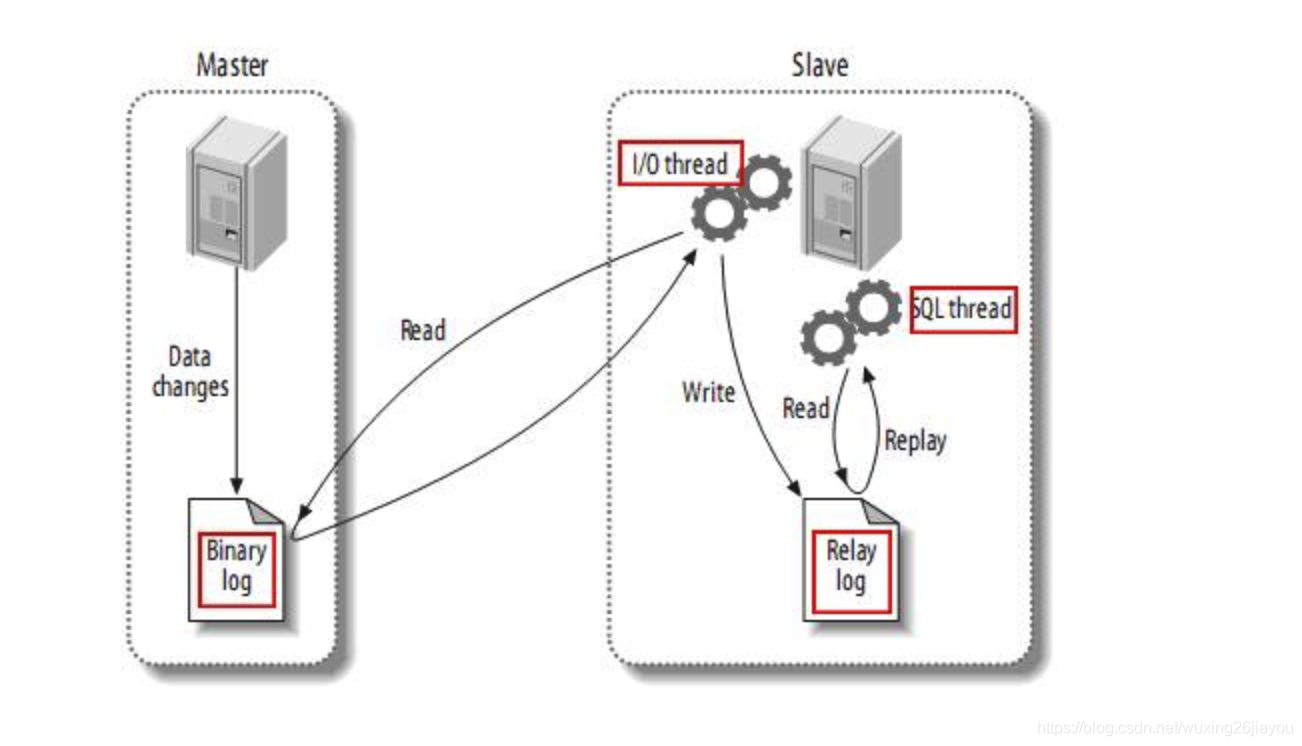
- Master发生数据变更时会将变更信息记录至binlog日志;
- Slave将Master的binlog日志中的事件拷贝到它relay log;
- Slave重放relay log中事件,将数据变更反映它自己的数据;
canal工作原理
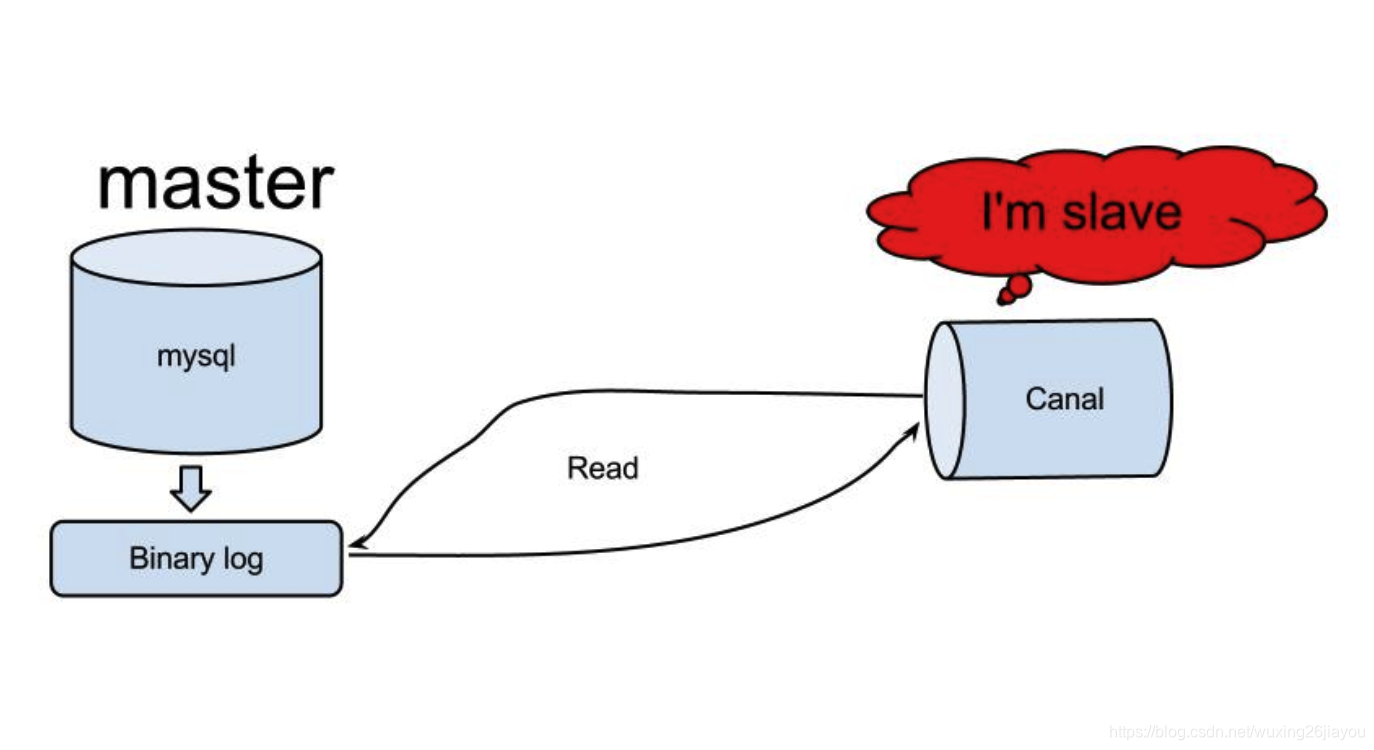 简单地讲,canal将伪装自己为MySQL Slave并向Master发送dump协议,获取binlog并解析
简单地讲,canal将伪装自己为MySQL Slave并向Master发送dump协议,获取binlog并解析
Canal内部组件解析
Canal server内部由几个模块组成, 外部的Server负责接收Canal Client的请求并返回数据。每个Server 内部由多个Instance组成,每个Instance都有五个模块,Parser负责解析,Sink负责过滤,Store负责存储,Manager 对元数据进行管理,Alarm则用于报警,Instance通常是一个数据库。
工作流程
Canal Server 启动后,会根据配置启动多个Instance, 每个Instance都会通过Socket连接到MySQL Master并dump binlog,然后将binlog二进制数据交给Parser解析,通过Sink过滤,最后存储在Store里面,当客户端连接时,会从zookeeper上读取对应的client的信息,而Manager负责管理zookeeper,如果这个过程出现错误,Alarm则会打印出报警信息。
canal客户端支持Java、Golang、PHP、Python、Rust、C#六种语言,其他语言可将变更记录投放到 Kafka/RocketMQ中,借助MQ多语言特性进行处理。
日常管理
canal 1.1.4版本,已引入canal-admin工程,提供相对友好的WebUI操作界面,方便更多用户配置管理、节点运维等的操作。
canal-admin的核心模型主要有:
- instance,对应canal-server里的instance,一个最小的订阅mysql的队列
- server,对应canal-server,一个server里可以包含多个instance
- 集群,对应一组canal-server,组合在一起面向高可用HA的运维
使用示例(基于docker)
拉取镜像
docker pull canal/canal-server本地编译
git clone [email protected]:alibaba/canal.git
cd canal/docker && sh build.sh运行cannal
sh run.sh -e canal.auto.scan=false \
-e canal.destinations=test \
-e canal.instance.master.address=127.0.0.1:3306 \
-e canal.instance.dbUsername=canal \
-e canal.instance.dbPassword=canal \
-e canal.instance.connectionCharset=UTF-8 \
-e canal.instance.tsdb.enable=true \
-e canal.instance.gtidon=false \性能监控
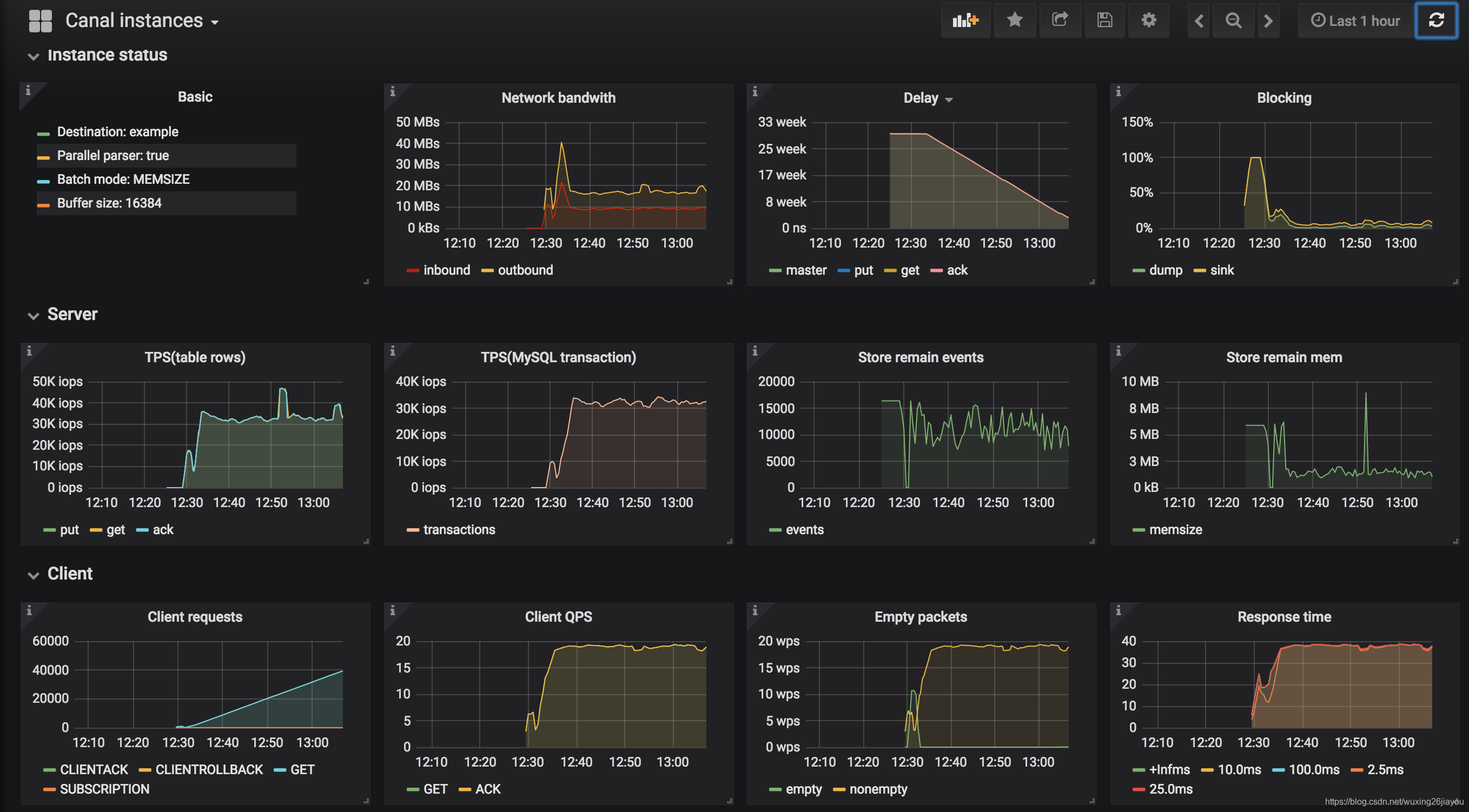
Canal server性能指标监控基于prometheus的实现。如果没接触过,可以先了解一下,目前主流的互联网公司都会用到prometheus,篇幅有限,这里不做展开,明天单独进行详细的介绍。

