以下内容来自《自然语言处理实践-聊天机器人技术原理与应用》
目前,工业界已有很多成型的 KBQA 系统,其中最著名的是 IBM 2011 年推出的 Watson 问答系统 ,它因在美国最受欢迎的智力问答电视节目《危险边缘》中一举打败了人类智力竞赛冠军而名声大噪。下面从技术的角度对 Watson 进行分析。Watson 采用的知识库是一个广义的知识库,其中不仅包含各种结构化知识,也包含各种非结构化的文本语料和语言学知识。Watson 作为一个集理解、推理、学习、交互功能于一体的强大问答系统,学习处理信息的过程分 4 个阶段,在一定程度上也模拟了人的认知思考过程。
(1) 观察 。观察可见的现象和有形的证据。
(2) 推断 。根据已有知识理解所见之事,然后对其中含义做一些假设。
(3) 评估 。判断某个假设的对错。
(4) 决策 。做出决策,选择最佳选项,并依此采取行动。整个流程称为 Deep QA,包含问题分解、假设生成、基于证据进行假设评估及排序等关键步骤,这里的 Deep QA 并非指通过深度学习技术提供问答。如下图所示为 Watson 问答系统的学习过程。首先,通过分析问题的语义,找出查询所需的依赖关系及查询的焦点;然后,根据查询线索生成候选答案,并给出相关性的评分;最后,归并重复的候选答案,由候选答案评估算法做排序选出最终的答案。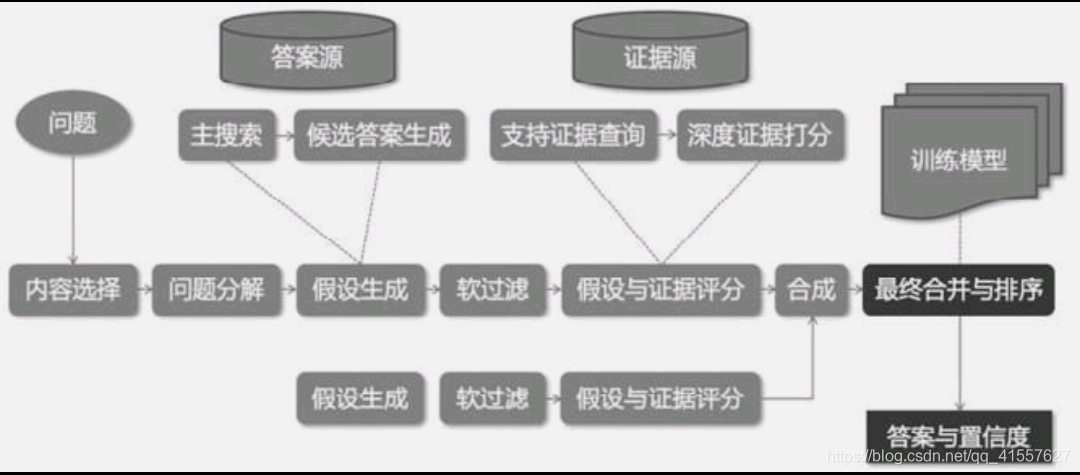
当 Watson 在某个特定领域开始工作的时候,它需要学习相应的语言、术语,以及该领域中的思维模式。以癌症为例,癌症有许多类型,每种都有不同的症状和治疗方案,然而除了癌症,其他疾病也可能出现这些症状,因此 Watson 会基于医疗实践和该领域内最优秀的技术文献进行标准评估,从而识别出最佳治疗方案,供医生为患者进行治疗时选择。Watson 的训练需要在「掌握」某个特定领域知识语料库的领域专家的指导下进行。Watson 的训练过程如图。
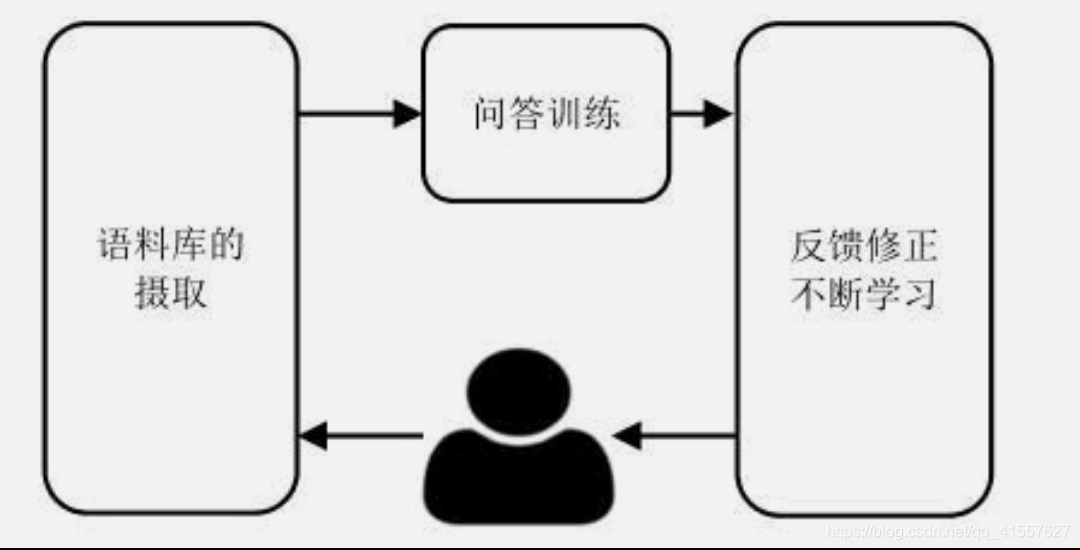
- 首先,进行语料库的「摄取」工作。语料库包含大量优秀的技术文献,还需加以一定的人工干涉进行降噪,并对数据进行预处理,构建索引和其他元数据,并依此构建一个知识图谱。
- 然后,对 Watson 进行问答训练。摄取语料库之后,Watson 需要接受人类专家的培训,学习如何理解信息。为了提升 Watson 的学习质量,主要通过机器学习的方法来训练。专家将训练数据以基本问答对的形式输入给 Watson,这里指的并不是问题的明确答案,而是教会它这个领域中专业知识所对应的语言模式。
- 最后,反馈修正不断学习。接受问答训练以后,Watson 会通过持续交互继续学习,用户和 Watson 之间的交互会定期由专家进行审核,并将反馈输入系统,帮助 Watson 更好地理解信息。新信息发布后,Watson 会根据新信息进行自我更新,以便不断适应特定领域中知识和语言阐释方面的变化。
当用户输入一个问题后,Watson 会经历以下处理过程,才生成最终的答案反馈给用户。 - 首先, 通过自然语言理解处理问句,识别出问题中的一些信息词;
- 接着 Watson 会根据信息词从答案源中生成候选答案,即生成假设;
- 然后它会寻找支持或推翻每一个假设的论据,并根据每个论据的统计建模结果,对每个论据进行评分,也就是「加权论据得分」;
- 最后,合并每一个假设的所有证据评分并进行综合排序,Watson 会根据答案响应率的高低估计答案的可信度,反馈给用户。
