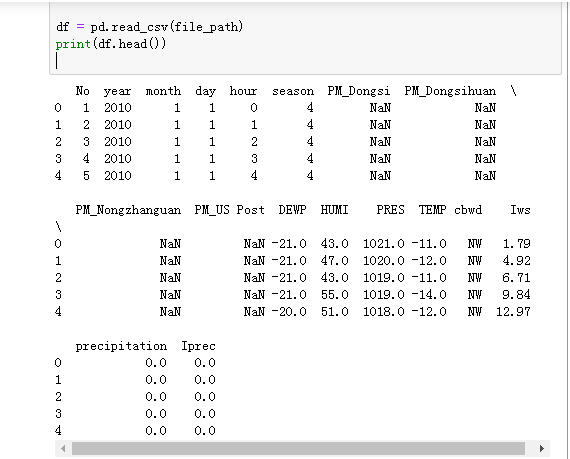
首先导入数据,并且查看数据的样式
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 file_path = './PM2.5/BeijingPM20100101_20151231.csv' 4 5 df = pd.read_csv(file_path) 6 print(df.head())
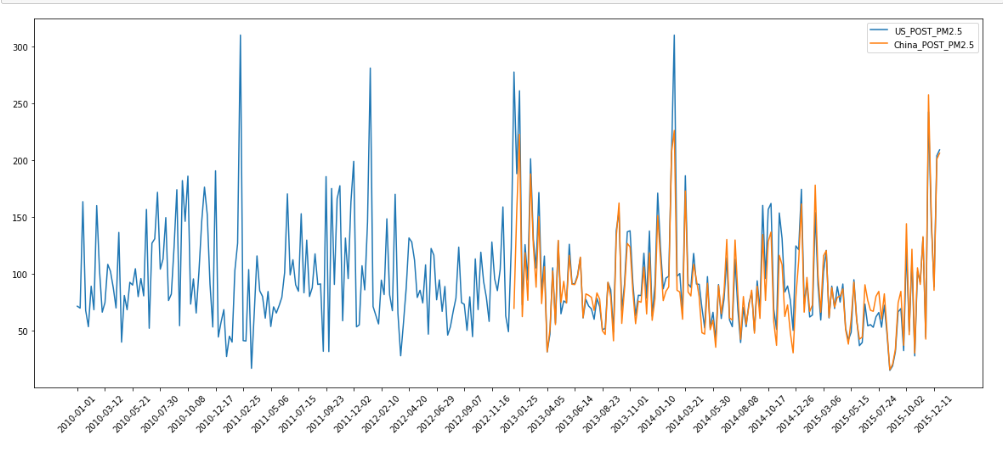
现在,要以PM_US Post和PM_Dongsi这两列为Y轴,时间X轴来画折线图。
这里可以发现几个问题,首先;时间中年月日小时是分开的,需要将其合并为2010-01-01 05:00这样可读的pandas类型。第二:PM_US Post这一列有NaN值,需要处理掉。
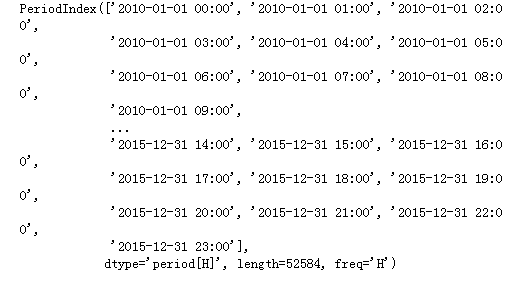
解决方法:针对第一个问题,可以使用pd.PeriodIndex()方法(效果如下图)。针对第二个问题,可以选择删除NAN的数据,因为空数据不多。
1 #把分开的时间字符串通过PeriodIndex方法转换为pands的时间类型 2 period = pd.PeriodIndex(year=df['year'], month=df['month'],day=df['day'],hour=df['hour'],freq='H') 3 print(period)
全部代码:
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 file_path = './PM2.5/BeijingPM20100101_20151231.csv' 4 5 df = pd.read_csv(file_path) 6 #把分开的时间字符串通过PeriodIndex方法转换为pands的时间类型 7 period = pd.PeriodIndex(year=df['year'], month=df['month'],day=df['day'],hour=df['hour'],freq='H') 8 9 #将整合的时间添加到数据中去 10 df['datetime'] = period 11 12 #将datetime设置为索引,原地修改 13 df.set_index('datetime', inplace=True) 14 15 #由于数据量太多,画图时不美观,所以以一周进行降采样(取平均值) 16 df = df.resample('7D').mean() 17 18 #处理q缺失数据 (PM_US POST列),删除 19 data = df['PM_US Post'] #删除应该是data = df['PM_US Post'].dropna() ,d但这里不删除,因为PM_Dongsi 这列数据缺失有点多。 20 21 22 #画图 23 _x = data.index 24 #重新格式化日期显示格式 25 _x = [i.strftime('%Y-%m-%d') for i in _x] 26 _y = data.values 27 28 _x_china = [i.strftime('%Y-%m-%d') for i in data_china.index] 29 _y_china = data_china.values 30 31 32 plt.figure(figsize = (20,8)) 33 plt.plot(range(len(_x)), _y, label='US_POST_PM2.5') 34 plt.plot(range(len(_x)), _y_china, label = 'China_POST_PM2.5') 35 36 plt.xticks(range(0,len(_x),10),list( _x)[::10],rotation = 45) 37 38 plt.legend() 39 plt.show()