这个算法看了半天才理解,在这里做一个不太详细的讲解。
首先用一个非常巧妙的方式,将所有可能的奇数/偶数长度的回文子串都转换成了奇数长度:在每个字符的两边都插入一个特殊的符号。比如 abba 变成 #a#b#b#a#, aba变成 #a#b#a#。 为了进一步减少编码的复杂度,可以在字符串的开始加入另一个特殊字符,这样就不用特殊处理越界问题,比如$#a#b#a#。
下面以字符串12212321为例,经过上一步,变成了 S[] = "$#1#2#2#1#2#3#2#1#"。
然后用一个数组 P[i] 来记录以字符S[i]为中心的最长回文子串向左/右扩张的长度(包括S[i],也就是把该回文串“对折”以后的长度),比如S和P的对应关系(可以看出,P[i]-1正好是原字符串中回文串的总长度):
那么怎么计算P[i]呢?该算法增加两个辅助变量(其实一个就够了,两个更清晰)id和mx,其中 id 为已知的 {右边界最大} 的回文子串的中心,mx则为id+P[id],也就是这个子串的右边界。
然后可以得到一个非常神奇的结论,这个算法的关键点就在这里了:如果mx>i,那么P[i]>=MIN(P[2*id-i],mx-i)。还是借助图来理解比较容易。
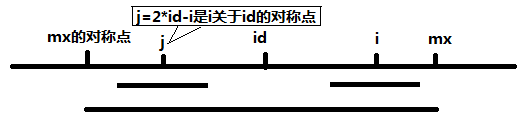
当 mx-i>P[j]的时候,以S[j]为中心的回文子串包含在以S[id]为中心的回文子串中,由于i和j对称,以S[i]为中心的回文子串必然包含在以S[id]为中心的回文子串中,所以必有P[i]=P[j],见下图。
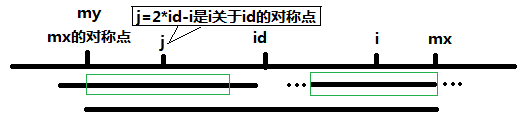
当 P[j]>=mx-i的时候,以S[j]为中心的回文子串不一定完全包含于以S[id]为中心的回文子串中,但是基于对称性可知,下图中两个绿框所包围的部分是相同的,也就是说以S[i]为中心的回文子串,其向右至少会扩张到mx的位置,也就是说P[i]>=mx-i。至于mx之后的部分是否对称,就只能老老实实去匹配了。
对于mx<=i的情况,无法对P[i]做更多的假设,只能P[i]=1,然后再去匹配了。
看一道模板题HDU3068。
Code:
#include<iostream>
#include<algorithm>
#include<cstdio>
#include<cstdlib>
#include<cmath>
#include<cstring>
#define N 33000005
using namespace std;
int p[N];char s[N];
int main()
{
while(~scanf("%s",s))
{
int id=0,Max=0,ans=0,len=strlen(s);
for(int i=len;i>=0;i--)
{
s[i+i+2]=s[i];
s[i+i+1]='#';
}
s[0]='$';
for(int i=1;i<len*2+1;i++)
{
if(p[id]+id>i)p[i]=min(p[2*id-i],p[id]+id-i);
else p[i]=1;
while(s[i+p[i]]==s[i-p[i]])p[i]++;
if(i+p[i]>Max)
{
Max=i+p[i];
id=i;
}
if(ans<p[i])ans=p[i];
}
printf("%d\n",ans-1);
}
}