一、安装模块
pip install xlrd
二、Excel文件
本次案例采用的文件来源于中华人民共和国教育部:http://www.moe.gov.cn/jyb_xxgk/s5743/s5744/201906/t20190617_386200.html
点击直接下载即可
三、数据库设计
根据表格内容设计简单的数据库
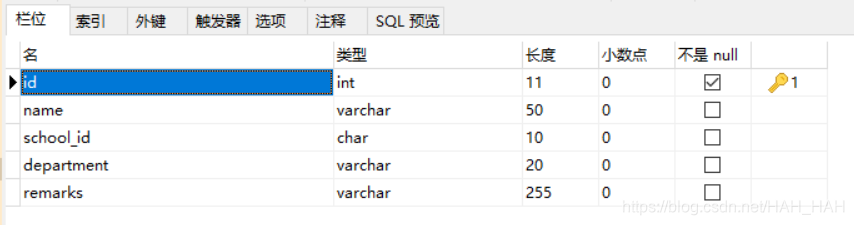
1.成人高校数据库(adult_school):

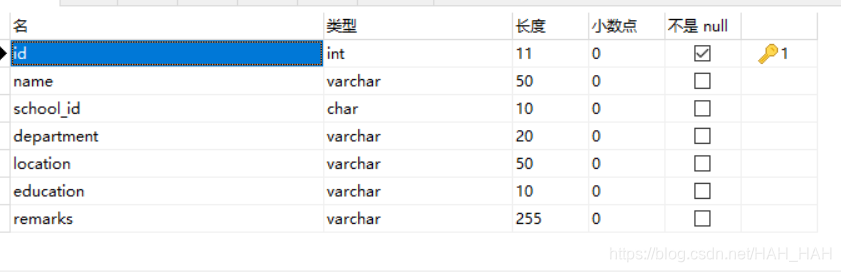
2.普通高校数据库(ordinart_school):

四、上代码
- 导入模块
import xlrd
import pymysql
- 定义方法open_file(),用来读取Excel文件并取出具体数据
def open_file(path):
try:
workbook = xlrd.open_workbook(path)
sheet = workbook.sheets()[0]
rownum = sheet.nrows
# print(rownum)
data = []
for value in range(4,rownum):
values = sheet.row_values(value)
# print(type(values[0]))
if type(values[0]) == float:
data.append(values)
# print(values)
return data
except Exception as e:
print(e)
workbook = xlrd.open_workbook(path):打开文件读取数据
sheet = workbook.sheets()[0]:通过索引顺序获取一个工作表
rownum = sheet.nrows:获取工作表中的行数
values = sheet.row_values(value):获取每一行中所有单元格的值
观察两个Excel文件,从第五行开始为所需要的数据
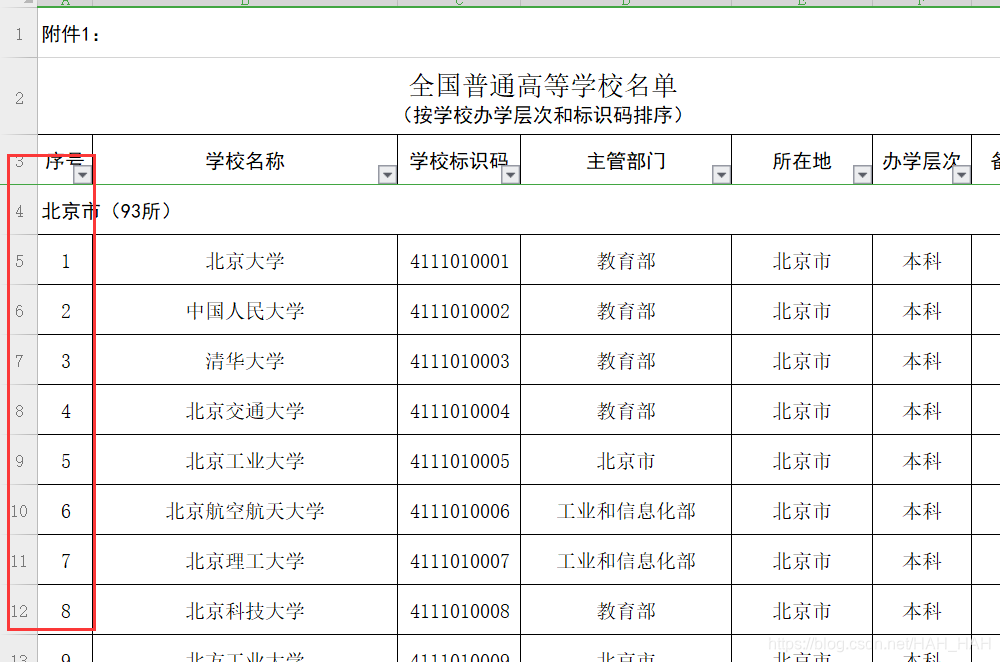
序号列用作表中的键,但是有些行显示的是城市名称,需要把这些行过滤掉。
通过遍历,打印每一行中第一个单元格的值
for value in range(4,rownum):
values = sheet.row_values(value)
print(type(values[0]))
结果:
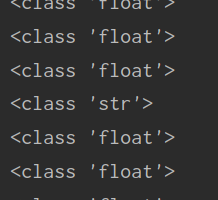
取出的值分别为float和str类型的,由此可以判断出只要是str类型的那一行都需要过滤掉,所以判断一下:
if type(values[0]) == float:
data.append(values)
并把取出的符合表的格式的数据存放于data列表中并返回。
- 定义方法in_sql(),用于写入数据库
def in_sql(data,name):
connection = pymysql.connect(
host='localhost', # 数据库地址
user='root', # 数据库用户名
password='19981216', # 数据库密码
db='school', # 数据库名称
# charset = 'utf8 -- UTF-8 Unicode'
)
# print(data)
cursor = connection.cursor()
print(name)
if name == 'adult_school':
sql = 'insert into ' + name + ' values(%s,%s,%s,%s,%s)'
else:
sql = 'insert into ' + name + ' values(%s,%s,%s,%s,%s,%s,%s)'
print(sql)
cursor.executemany(sql,data)
connection.commit()
print(cursor.rowcount)
in_sql 方法有data和name两个参数,data参数就是调用open_file()返回的值,name参数指的是表的名字,因为两个Excel文件内容是不一样的。
添加一个判断,用来判断应该写入哪个表:
if name == 'adult_school':
sql = 'insert into ' + name + ' values(%s,%s,%s,%s,%s)'
else:
sql = 'insert into ' + name + ' values(%s,%s,%s,%s,%s,%s,%s)'
print(sql)
- main函数:
if __name__ == '__main__':
adult_school = open_file('./W020190617630075984660.xls')#成人 5列
ordinart_school = open_file('./W020190617630075964590.xls')#普通 7列
in_sql(adult_school,'adult_school')
in_sql(ordinart_school,'ordinart_school')
完整代码:
import xlrd
import pymysql
def open_file(path):
try:
workbook = xlrd.open_workbook(path)
sheet = workbook.sheets()[0]
rownum = sheet.nrows
# print(rownum)
data = []
for value in range(4,rownum):
values = sheet.row_values(value)
print(type(values[0]))
if type(values[0]) == float:
data.append(values)
# print(values)
return data
except Exception as e:
print(e)
def in_sql(data,name):
connection = pymysql.connect(
host='localhost', # 数据库地址
user='root', # 数据库用户名
password='19981216', # 数据库密码
db='school', # 数据库名称
# charset = 'utf8 -- UTF-8 Unicode'
)
# print(data)
cursor = connection.cursor()
print(name)
if name == 'adult_school':
sql = 'insert into ' + name + ' values(%s,%s,%s,%s,%s)'
else:
sql = 'insert into ' + name + ' values(%s,%s,%s,%s,%s,%s,%s)'
print(sql)
cursor.executemany(sql,data)
connection.commit()
print(cursor.rowcount)
if __name__ == '__main__':
adult_school = open_file('./W020190617630075984660.xls')#成人 5列
ordinart_school = open_file('./W020190617630075964590.xls')#普通 7列
in_sql(adult_school,'adult_school')
in_sql(ordinart_school,'ordinart_school')
