今天我们来一个没有代码的教程,无需编程基础也能学会搭建智能对话系统,在学习之前,我们先来了解一下对话系统的专业术语:
- 单轮对话:简单的一问一答,问题可以用一句话来描述,不依赖于上下文
- 召回率:机器人能回答的问题数与问题总数的比值,机器人能回答的问题越多,召回率越高
- 准确率:机器人正确回答的问题数与问题总数的比值
- 问题解决率:机器人成功解决的问题数与问题总数的比值
- 多轮对话:进行多次对话,每次对话考虑话语间的相互关系
- 任务完成率:成功结束的多轮对话数与多轮对话总数的比值
- 意图识别:识别提问者的潜在目的及其表达诉求
- 对话理解方法:基于语义解析(任务型)和基于语义匹配(问答型)
搭建智能对话系统,百度官方提供了三个步骤:
- 设置BOT技能
- 标注数据
- 训练测试
因为我们使用的是UNIT,所以我们先来了解一下改平台的专业术语:
- BOT:一个BOT对应一个特定场景下独立完整的对话系统,用来满足特定场景下的对话理解与交互需求
- 技能:某一个方向的对话能力,技能下包含对话意图与问答意图
- 意图:意图指在一个对话任务中BOT要理解的用户目的
- 词槽:满足用户对话意图时的关键信息或限定条件,可以理解为用户需要提供的筛选条件
- 词典:属于词槽的所有词汇组成词典
- 对话样本:用来给对话系统做示范,教它在用户说的具体句子里,该如何理解对话意图,哪个词是重要信息,对应的词槽是什么
- 对话模板:用来给对话系统按具体语法、句式做出的示范,教它在某一个特定语法、句式中,该如何理解对话意图,哪个词是重要信息,对应的词槽、特征词是什么
- 特征词:约束某条对话模板的匹配范围的同时,提供一定限度的泛化能力
- 问答对:问题与答案的组成,称为问答对
- 问答集:问答集是承载问答对的容器,与技能中问答意图的定义一一对应
- 训练模型:把BOT下所有的配置、标注的对话样本、对话模板等打包提交给UNIT平台来训练对话理解模型,训练的时长跟训练的对话样本量、对话模板量有关系,量越多训练时间越长。训练完成后沙盒环境中的BOT会自动加载并生效模型, -般需要几分钟时间。
- 沙盒环境:每个BOT都配有一个沙盒环境,将训练好的BOT模型生效到沙盒环境后,就可以进行效果验证了
- 生产环境:生产环境是UNIT平台在百度云.上为开发者提供的可定制的稳定的对话服务环境。
以上概念较多,可能会有没有整理完的地方,如有疑问,可以观看官方给的视频进行学习:http://abcxueyuan.cloud.baidu.com/#/courseDetail?id=14752
我们先进入UNIT的首页:
https://ai.baidu.com/unit/home

点击进入UNIT,在我的机器人里,新建机器人:

新建好BOT以后,我们找到"我的技能",点击新建技能:
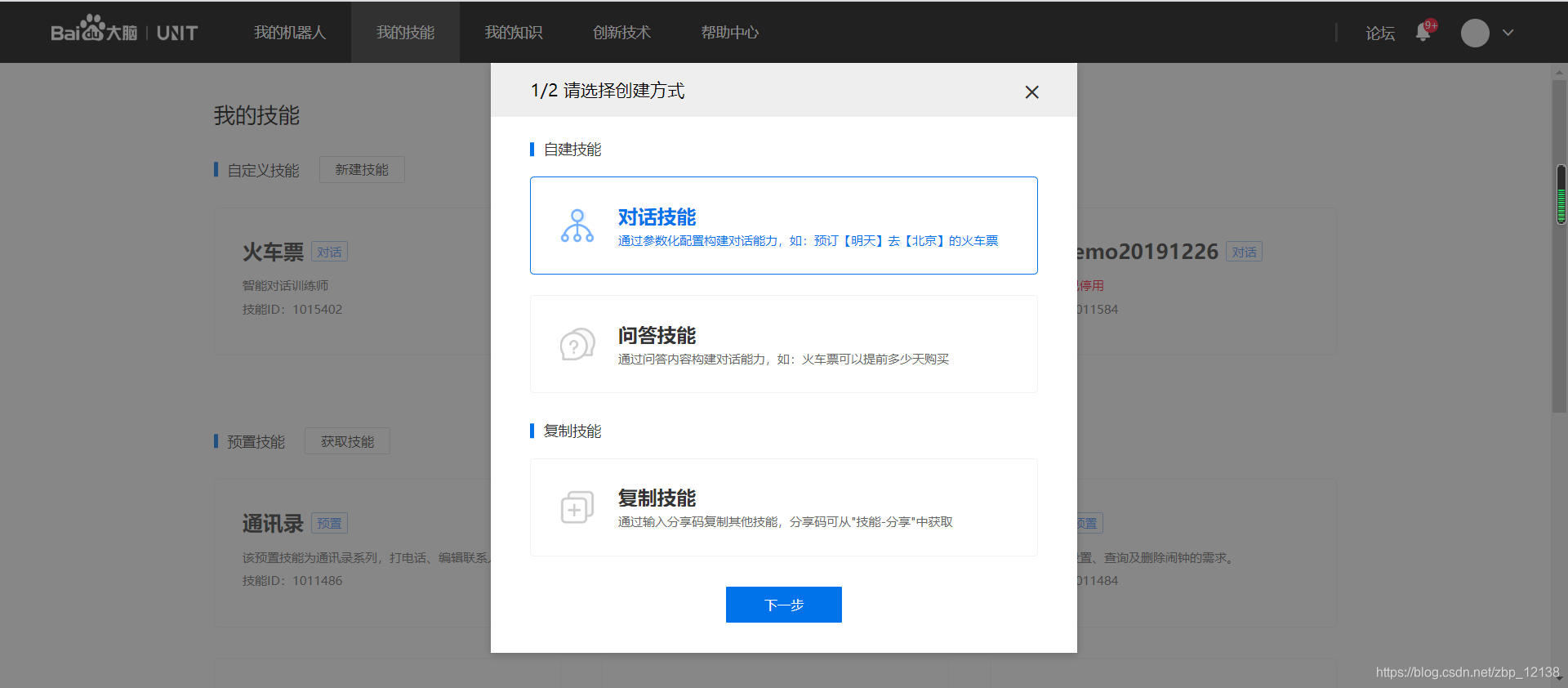
这里我们以创建订火车票为示例,创建以下四个对话意图:
- BOOK_TICKET(订票)
- INQUIRY_PRICE(询价)
- REFUND_TICKET(退票)
- TIME_CONSUMING(耗时)
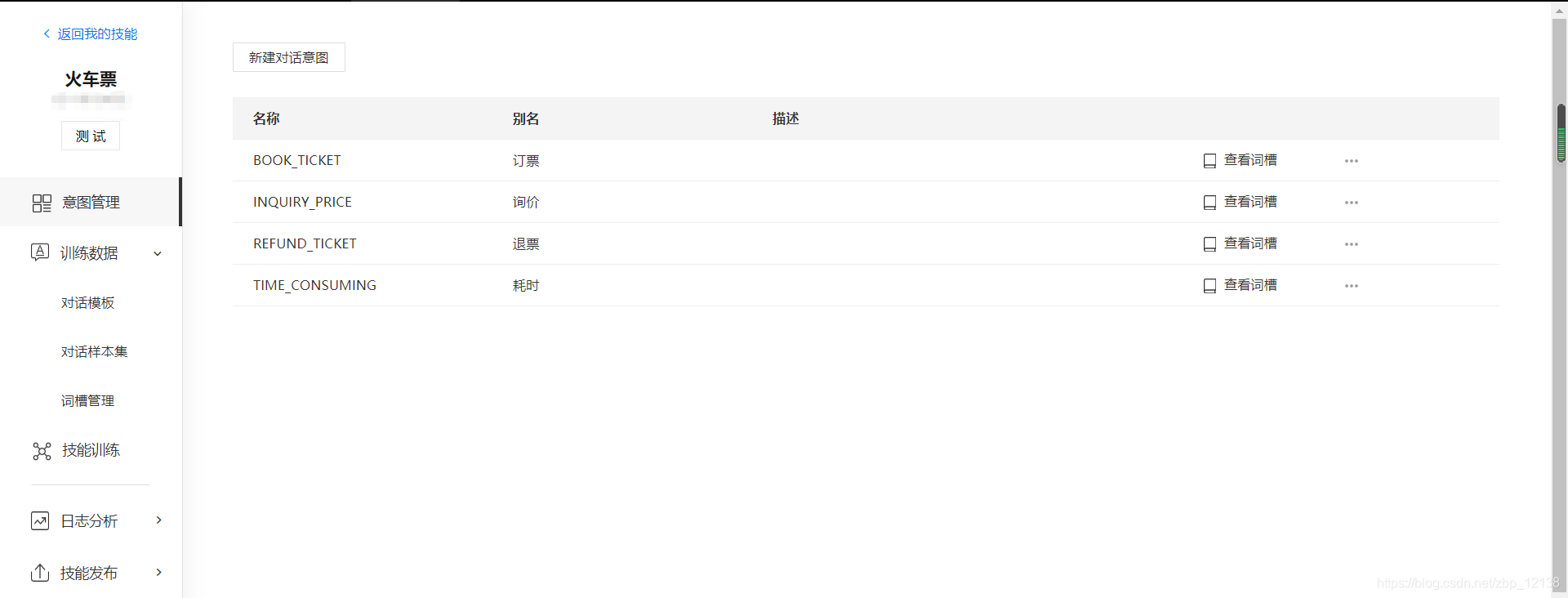
以订票的意图为例,我们创建以下词槽:
- user_departure 出发地
- user_destination 目的地
- user_departure_time 出发时间
- user_train_type 列车类型
- user_seat_type 坐席类型
- user_ticket_type 车票种类
- user_train_num 列车车次
- … …
词槽可以根据需要自行添加,以出发地为例:

词典可以选择系统词典,也可以选择自定义。在这里的澄清话术中,为了让机器人的表达更像人,我们可以添加更多不同的话术。
以下是在订票意图下添加的词槽:
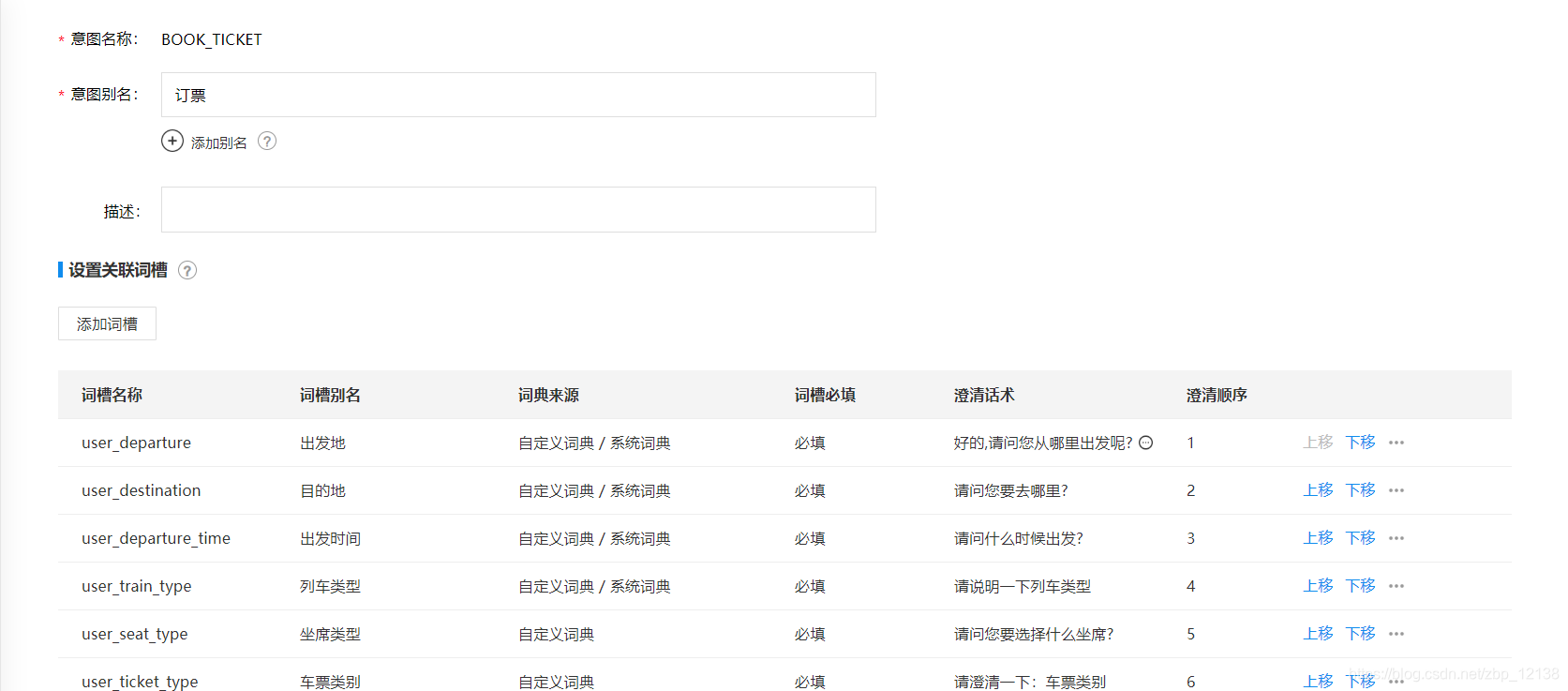
添加好词槽以后,可以调整澄清顺序,当所有词槽都添加完毕后,可以在下方添加回复内容,我们点击智能生成触发规则:
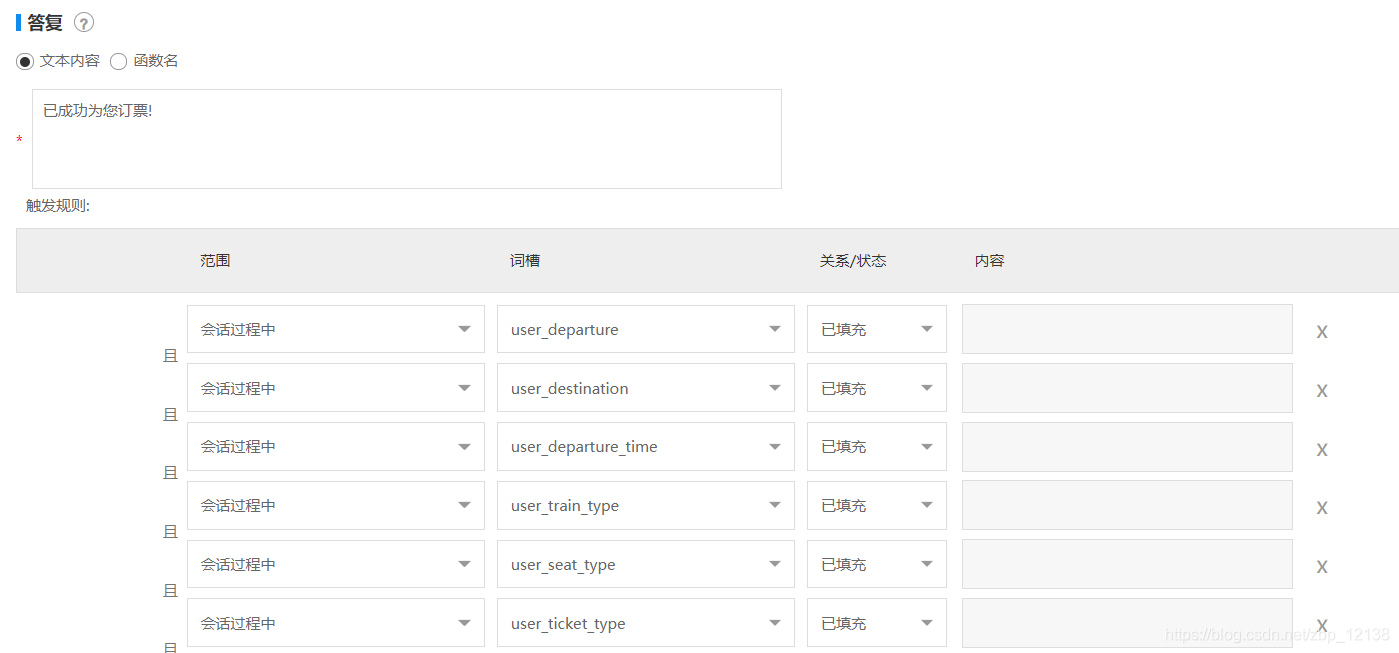
当所有必填词槽已填充时,回复:“已成功为您订票!”
其他四个意图的配置方法也是如此:
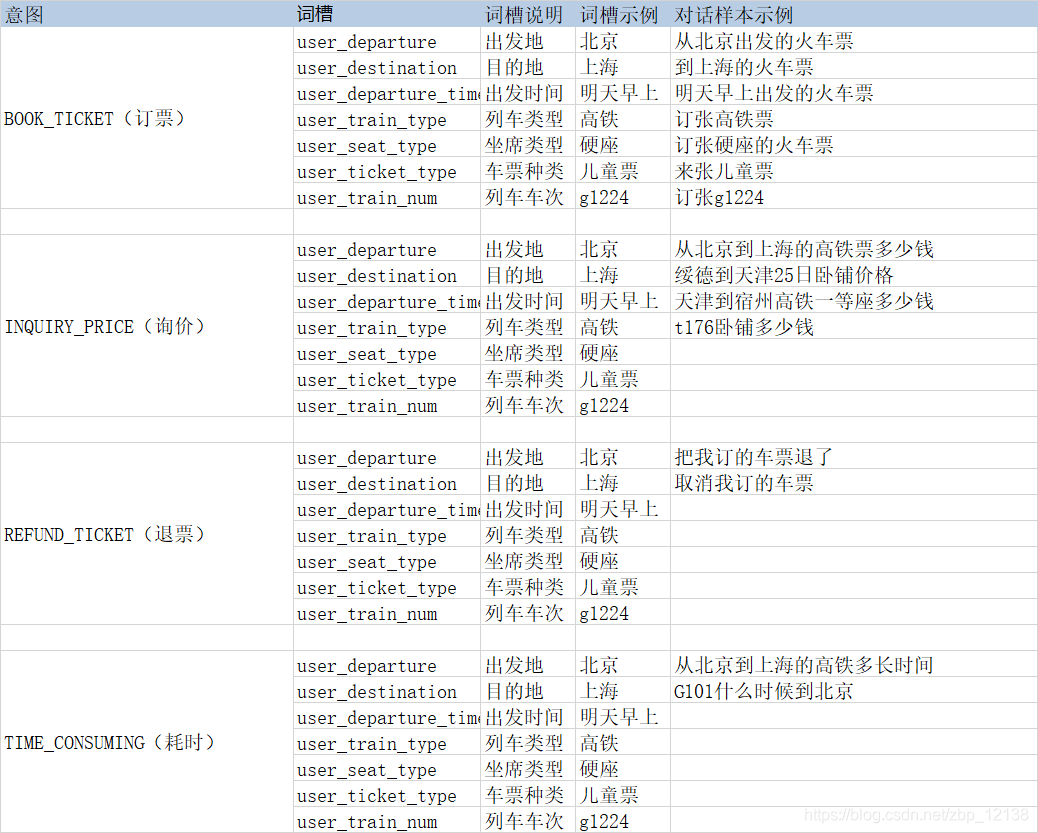
如果选择的是自定义词槽,我们可以找到词槽管理:
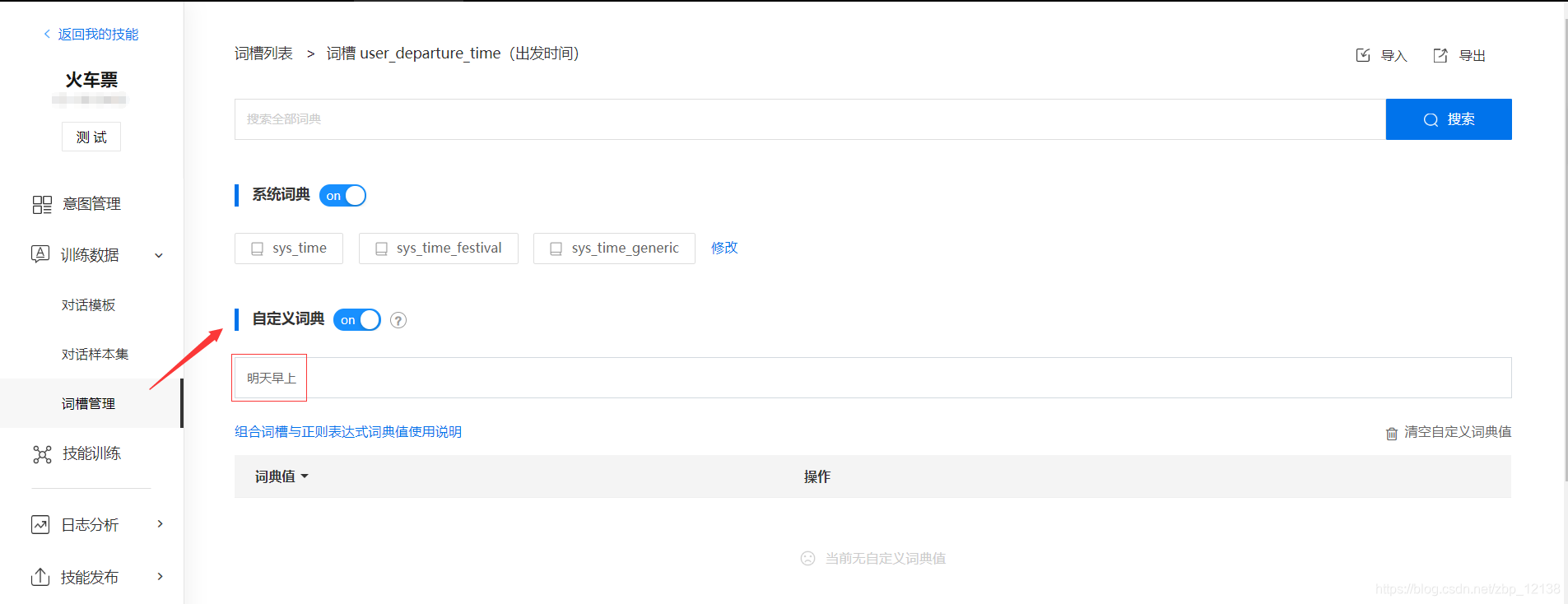
我们进入user_departure_time这个词槽,编辑自定义词典,我们输入一个"明天早上",确认后,回车:
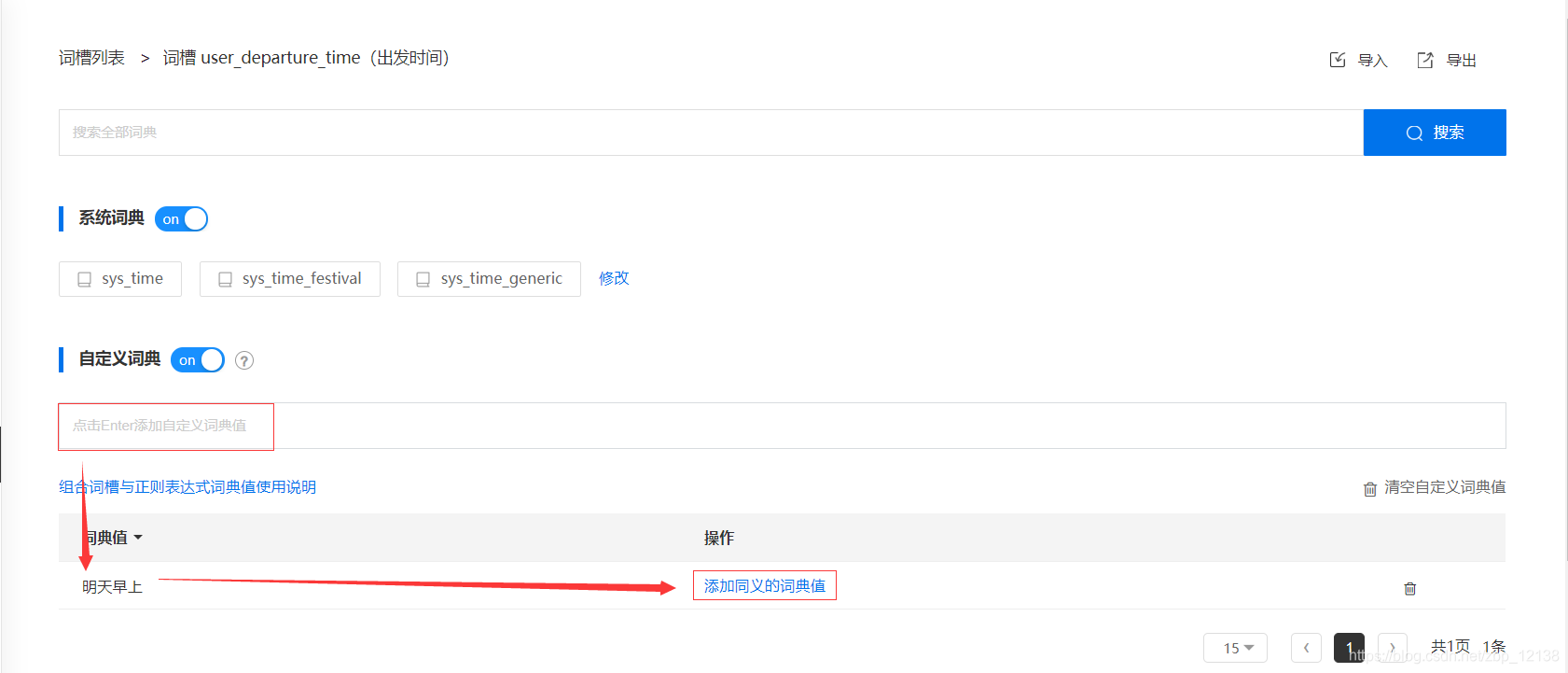
我们还可以添加同义词:

当然,如果觉得这样做比较麻烦,我们可以事先写好:

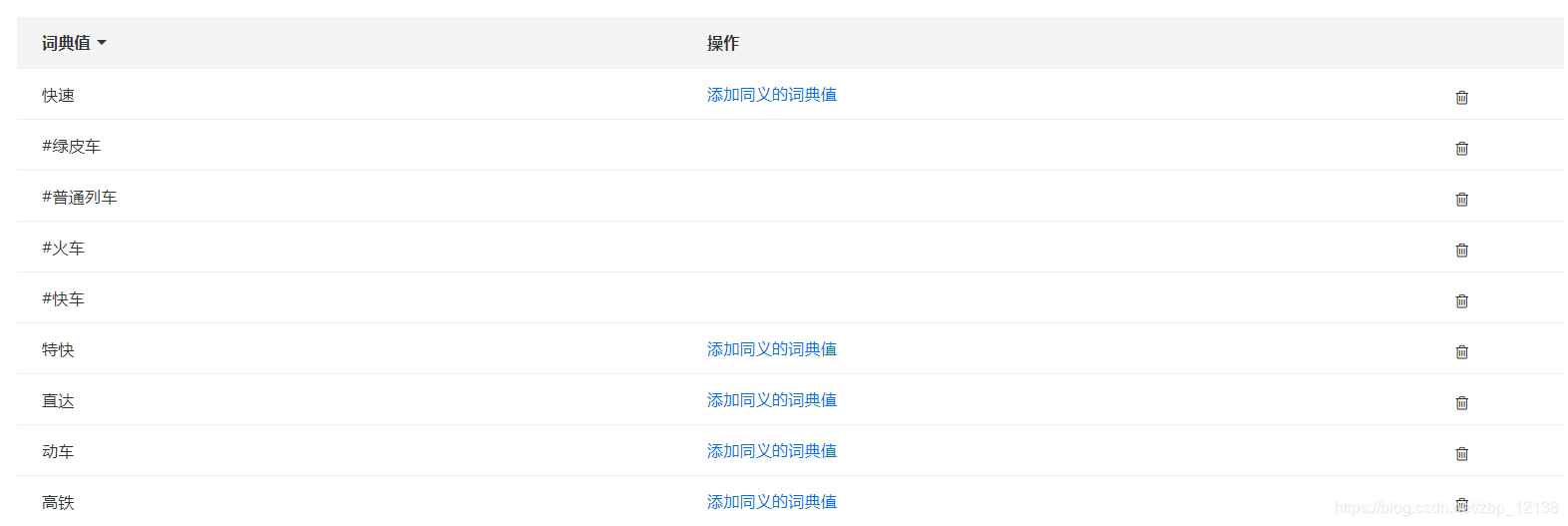
这里讲一下格式,在.txt文件里,每行编辑一个词典值,不带#的词典值是归一词的形式,是某个词的正规表达格式或程序里需要的归一化格式;每个归一化格式的词典值下面都可以用#开头关联多个同义词、近义词或归一词简写性质的词典值。最后把该文本用UTF-8的编码保存:

然后我们导入词槽:
成功导入:
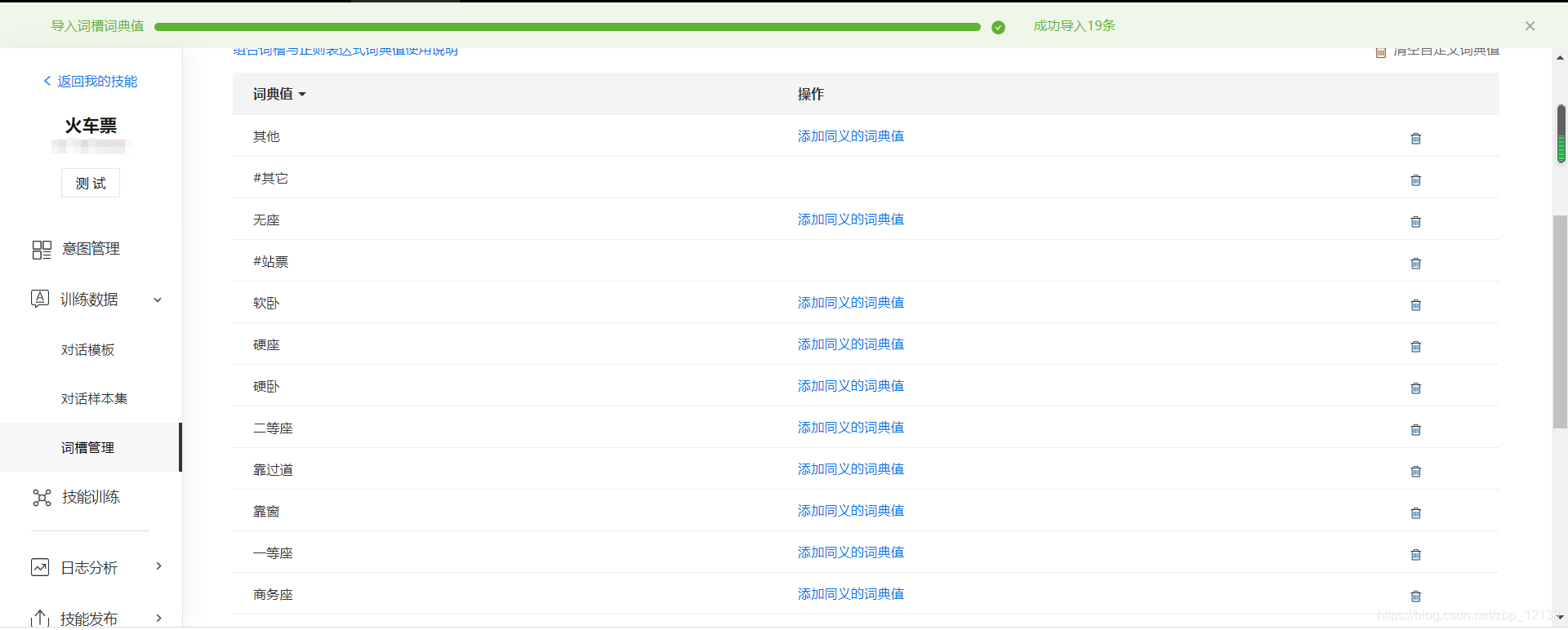
接下来,就要开始添加对话模板。添加对话模板的第一件事是要选择意图,每一条对话模板都要有一个与之对应的意图。同时一条query过来以后,如果他命中了这条模板就意味着query表达的目的就是这条对话模板对应的意图。
这里我们选择为BOOK_TICKET(订票)这个意图添加模板:
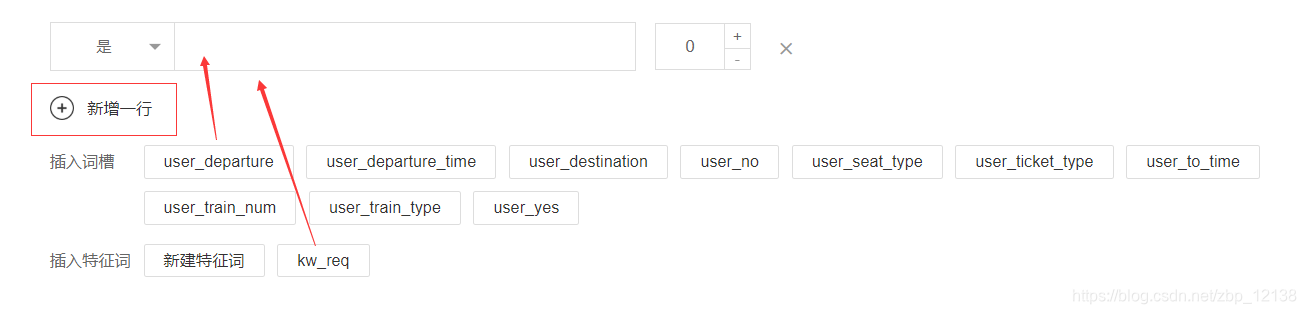
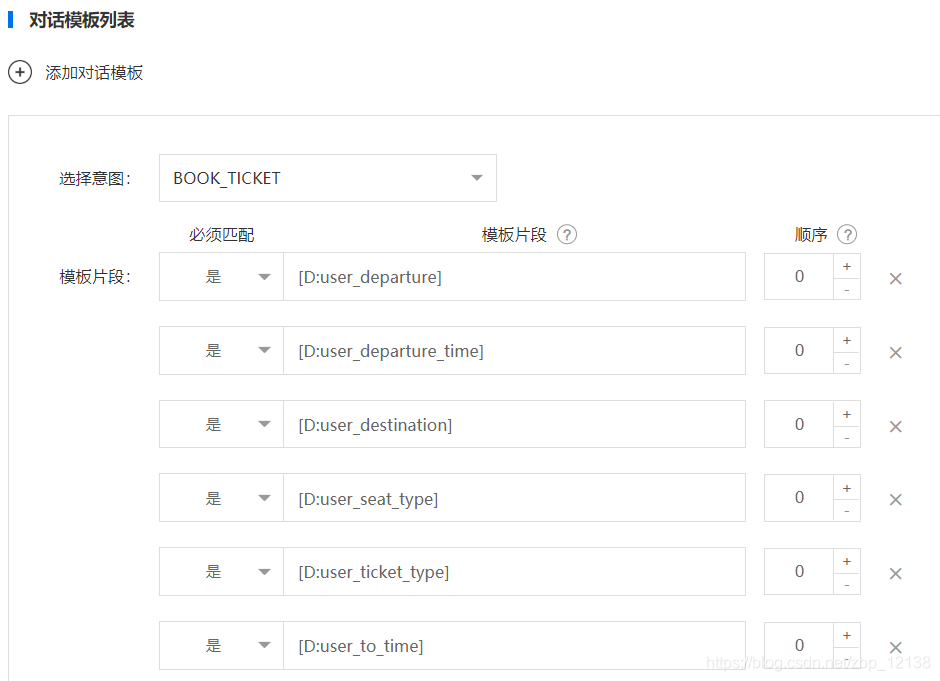
选择了意图,我们要介绍另外一个概念。对话模板都是由多条模板片段组成,我们刚才已经分析出来了它的关键信息。我们就可以把之前的关键信息全部放到模板片段当中一条一条的列出来,等我们把之前分析出来的关键信息全都配置到这条对话模板的模板片段之中以后,我们还要看两件事情:
首先,这里有一个必须匹配的选项,默认为是;还有一个顺序的选项,默认全都是零。
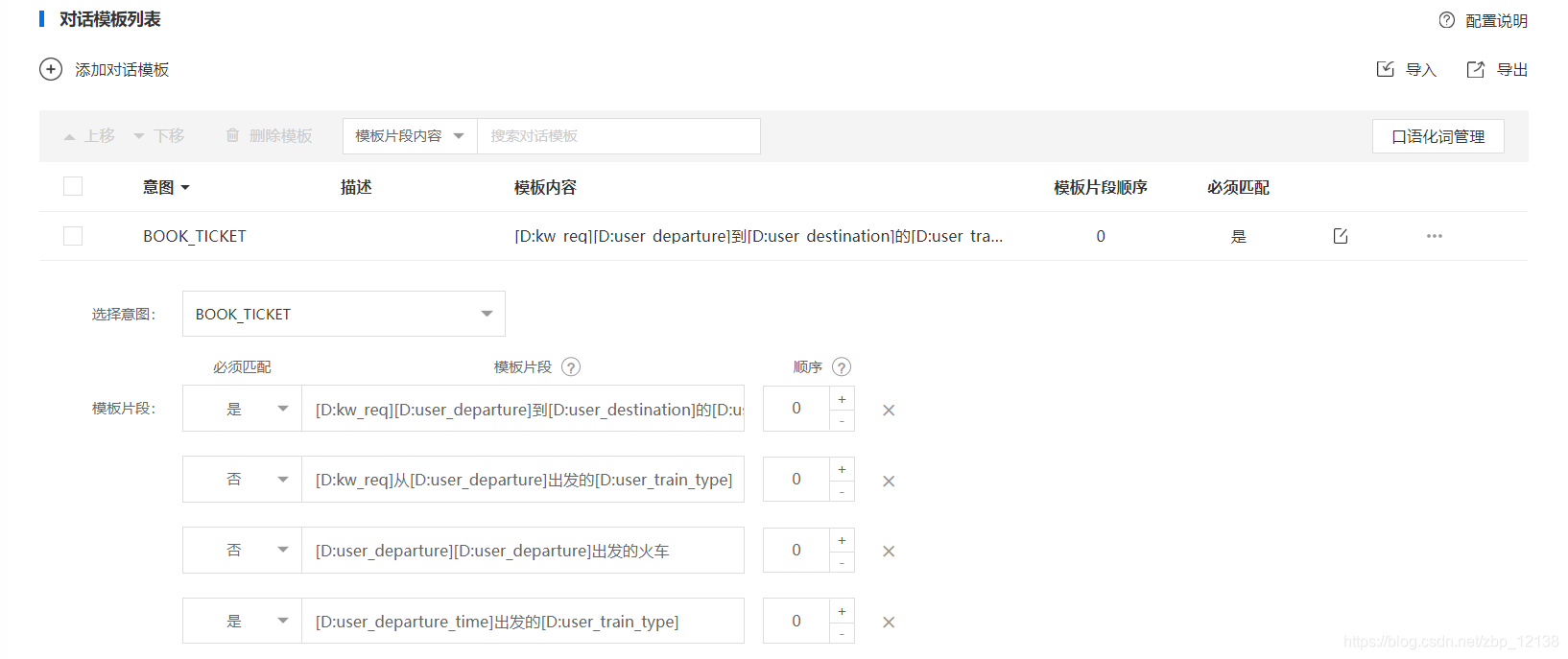
我们先来介绍一下何为必须匹配。当一条query进来以后,模板首先会识别里面的关键信息,命中了以后他就会把关键信息提炼出来,紧接着,他会把这些关键信息和对话模板的模板片段做匹配,如果模板片段全部都被关键信息命中了。那么这些关键信息就会被提取出来。
除此之外,同一句话可能会出现两种意图:(例如:饺子包好了这句话)
- 1.指饺子已经制作好了
- 2.指饺子用包装盒打包好了
所以我们要对模板进行一下调整,首先要确认一下一定需要的模板片段,所谓一定需要的模板片段就是可能会影响这句话含义的片段。在订票这个意图里,订字是关键:
例如: [帮我订一下] [北京] 到 [上海] 的 [火车票]
我们可以写成:
[D:kw_req][D:user_departure]到[D:user_destination]的[D:user_train_type]
其中的[D:kw_req]是一个特征词,我们可以自行添加: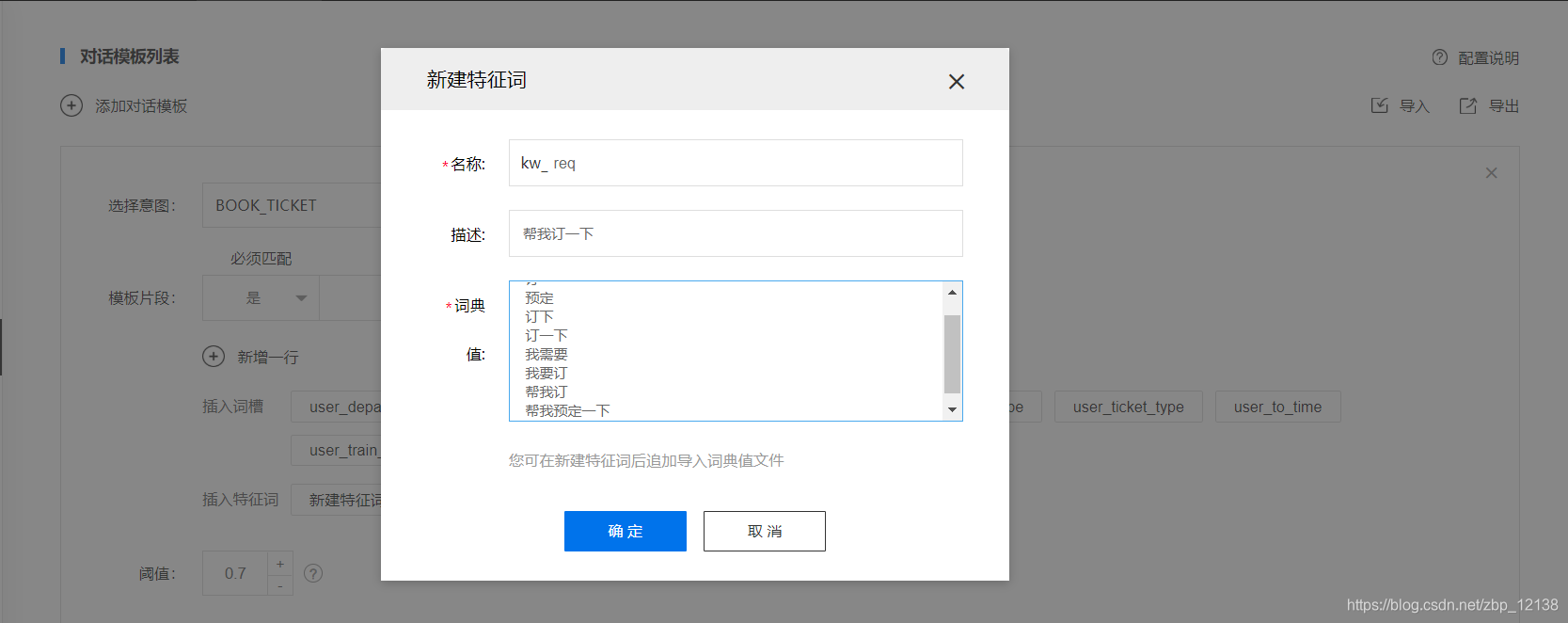
不仅如此,我们还可以使用通配符:
通配符匹配指定长度的任意字符串0-8个任意汉字表示为"[W:0-16]"一个汉字占两个字节, 所以是16
例如:[帮我订一下] [北京] 出发的 [软卧] , [谢谢你]
可以表示为:
[D:kw_req][D:user_departure]出发的[D:user_seat_type],[W:0-16]
这里的必须匹配我们把大部分都设置为否。那么,既然词槽是不一定必须匹配的,那为什么还要配在模板片段里面,这就要提到第二个点:阈值:

一句话的有效信息是放在分子上的,这句话总的长度是放到分母上的,也就是说,如果这句话包含的模板片段的内容占整个句子的内容比例越大,我们就认为它符合这个意图的可能性越高,这就是阈值,所以说如果模板片段只包含了这两个特征词,并没有包含其他的词槽的话,会出现准确率降低的情况。
我们再来看顺序,如果某一个模板片段的顺序是零。意味着这条模板片段可以出现在句子的任意位置,如果是1,则意味着这个模板片段要出现在2、3、4之前,如果是2就意味着该模板片段要出现在3、4之前,但是要在1的后面。
如果我们把所有模板片段的顺序都调成了0,那我们来看一个句子:
我想明天下午三点去北京,帮我订一张高铁票。
那如果我说:
帮我订一张票,明天下午三点去北京的高铁票。
因为顺序全部都是0,所以说模板片段可以出现在句子的任意位置。
除此之外,通过控制阈值的高低还可以调节它的召回率和准确率。
比如将阈值调成1的话,意味着分子上的模板片段和分母只要是相同的,也就是说在这种情况下不能出现任何一个字的无效信息,那它的准确率一定会提高。
以上就是模板片段顺序以及必须匹配。如果必须匹配,意味着我们可以在后续多轮对话中澄清补充。
**就像我们刚才举的例子,我想订票。如果是人跟人之间的对话,对方的人肯定会反问他好的,那您想去哪?或者他会问你想几点去?
同样的,机器人也是这个效果,当你跟机器人说我想预约的时候,机器人下一步就会反问,请问您从哪里出发?您要到哪里?**
这就是后续再澄清补充的目的。
接下来,我们开始添加对话样本集:

当我们添加超过10条以后,可以一键添加样本:

以下是获取到的样本:
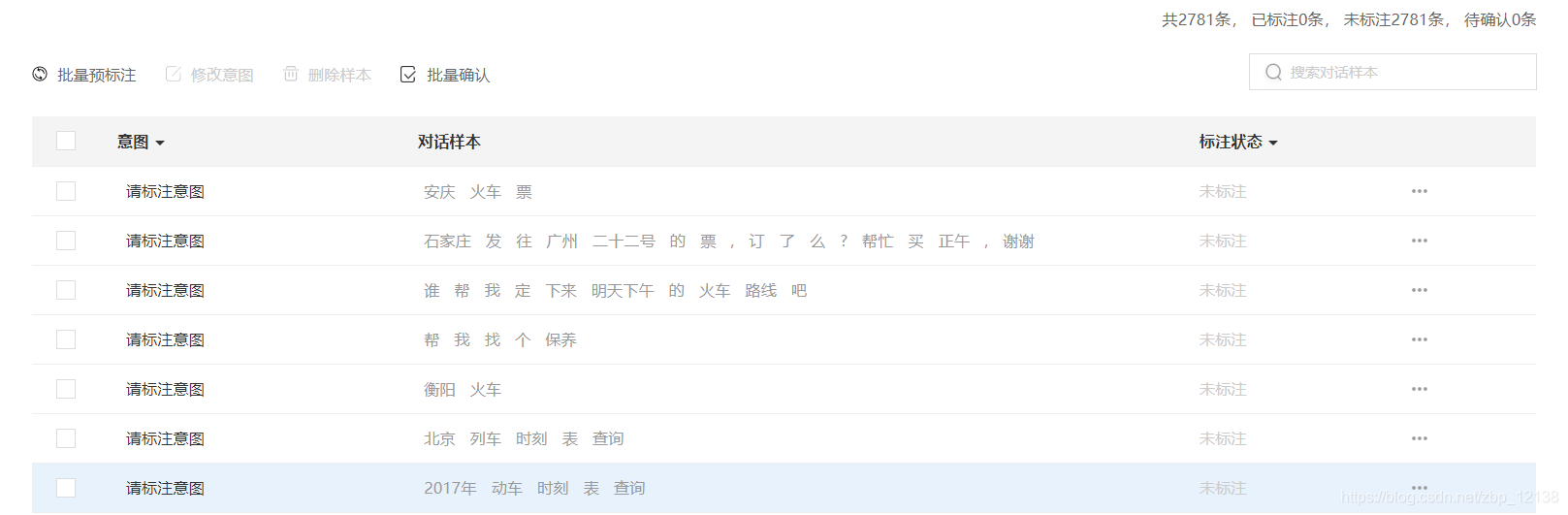
我们可以直接在上面进行标注,准备了一定量的数据以后,我们就可以开始训练了:
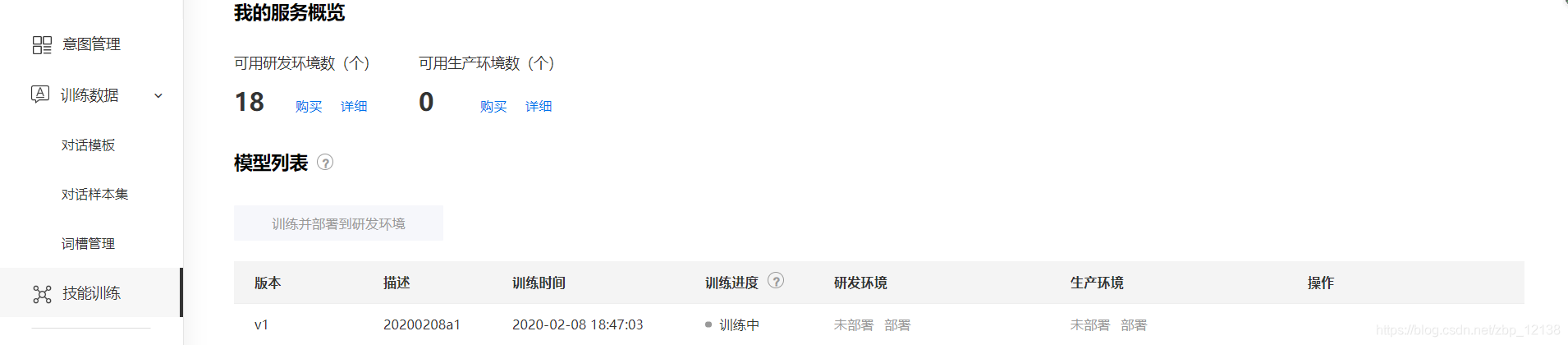
1分钟左右就可以了,我们来测试一下:
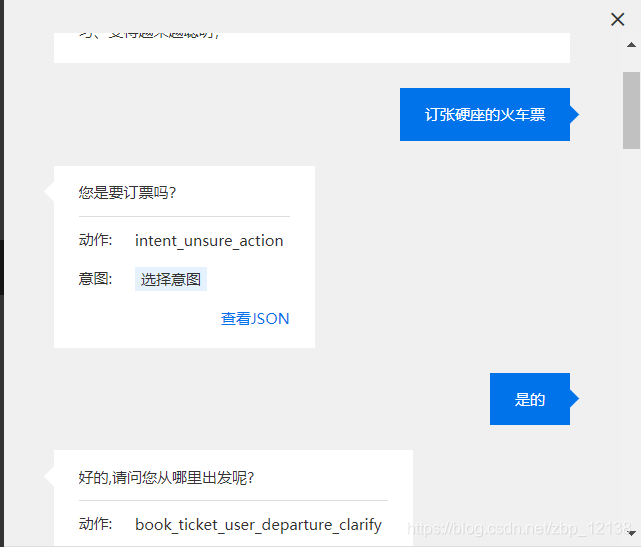
这里我们让机器人明确我们的意图,因为意图识别正确,所以我们回答:是的

在机器人问了三个问题以后,问到了列车类型,我回答:高铁吧
这时,可以很明显地看出机器人没有很好地识别出高铁就是列车类型,这是我们可以自行标注一下:
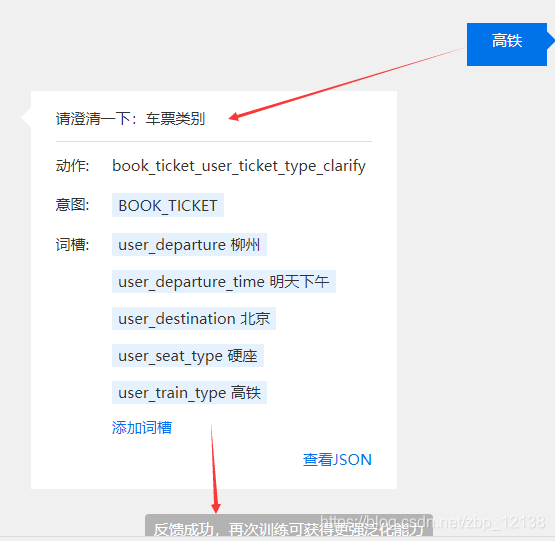
我们接着往下,又回答了几个问题以后:

到这里,可以看出,user_train_type这个词槽还需要改进,于是我们来到该词槽添加一些常见的列车类型:
我们再来训练一下测试 第二次训练出来的效果如何,这次我们换一个退票的意图:
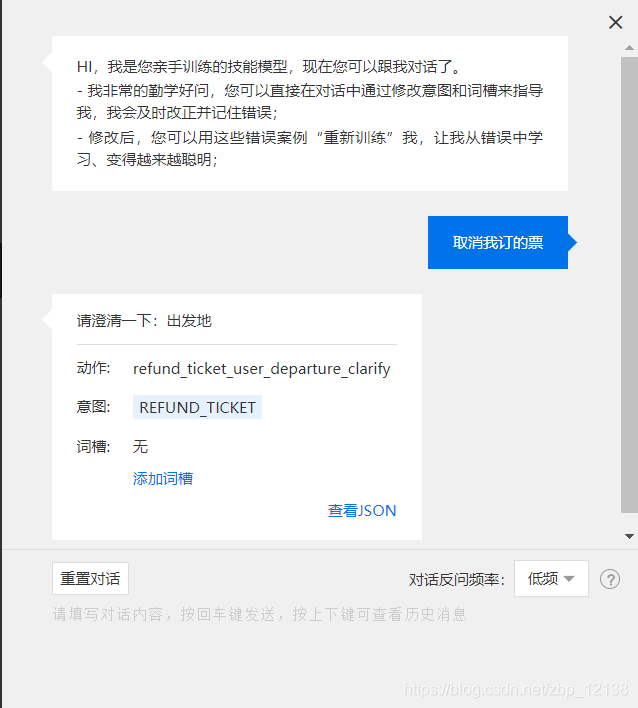
这个意图是正确的,但是不是我想要的结果,况且,正常情况下,如果购票人没有指定退哪张票,那么很有可能,他只买了一张票;而如果买了多张票,在退票时会指明了退哪张票。因此,我们回到意图管理,修改一下:
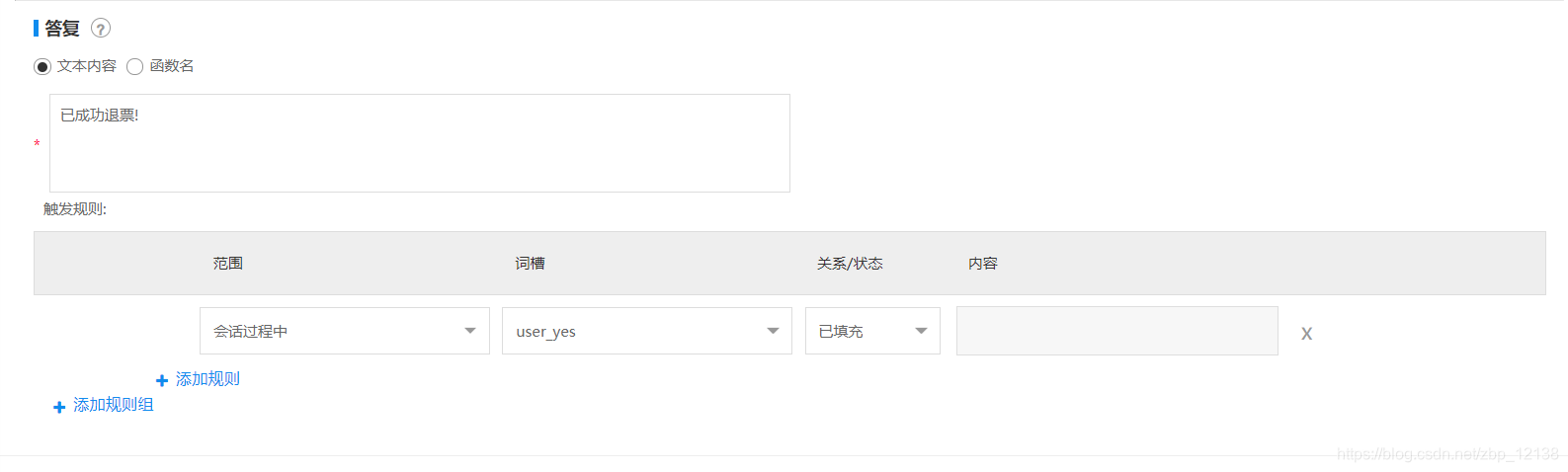
把触发规则改成确认退票时,触发退票,进入对话模板也修改一下:

这样一来,如果用户不加说明,只要有退票的特征词出现,我们就立即执行退票。同理,我们按照类似的思路检查一下其他三个意图。
在TIME_CONSUMING(耗时)这个意图中,出发时间、坐席类型以及车票种类不影响机器人判断消耗时间,因此,我们把这三个词槽也设置为非必填。
除此之外,我们打开交互学习日志:
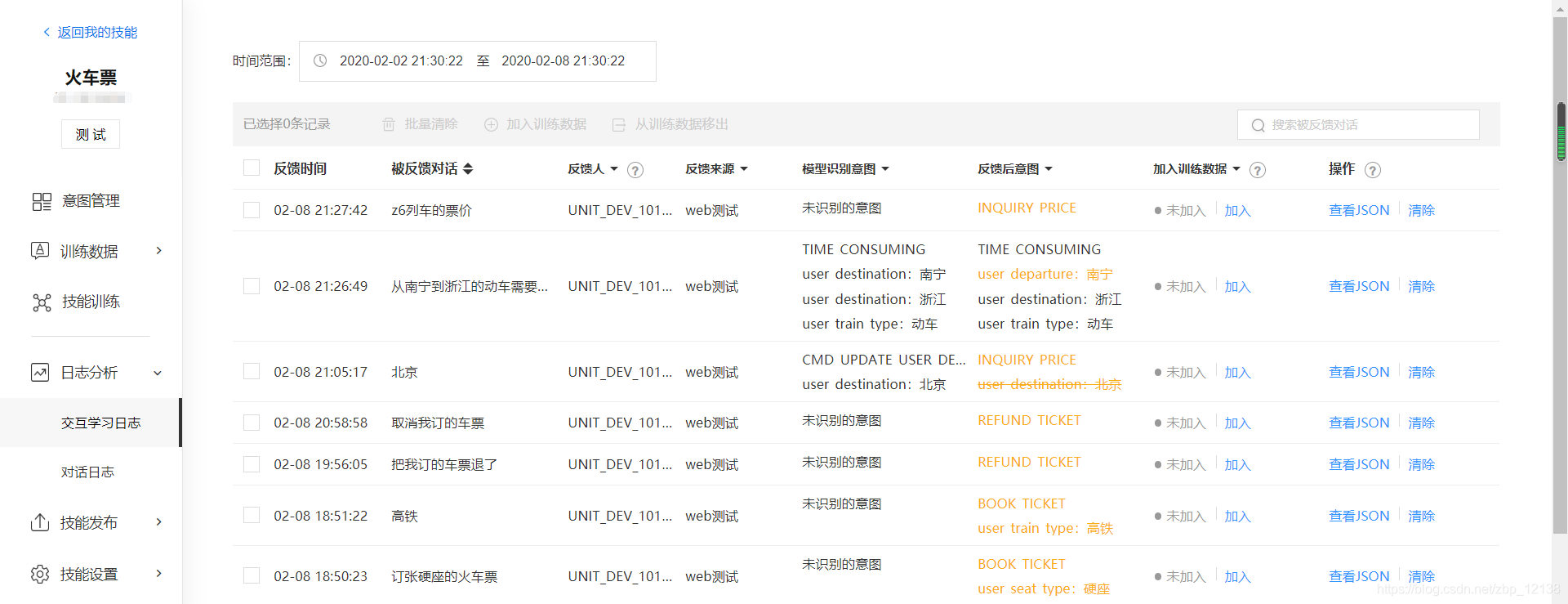
通过交互学习,可以使模型的效果更好。我们可以把配置好的技能接入微信:
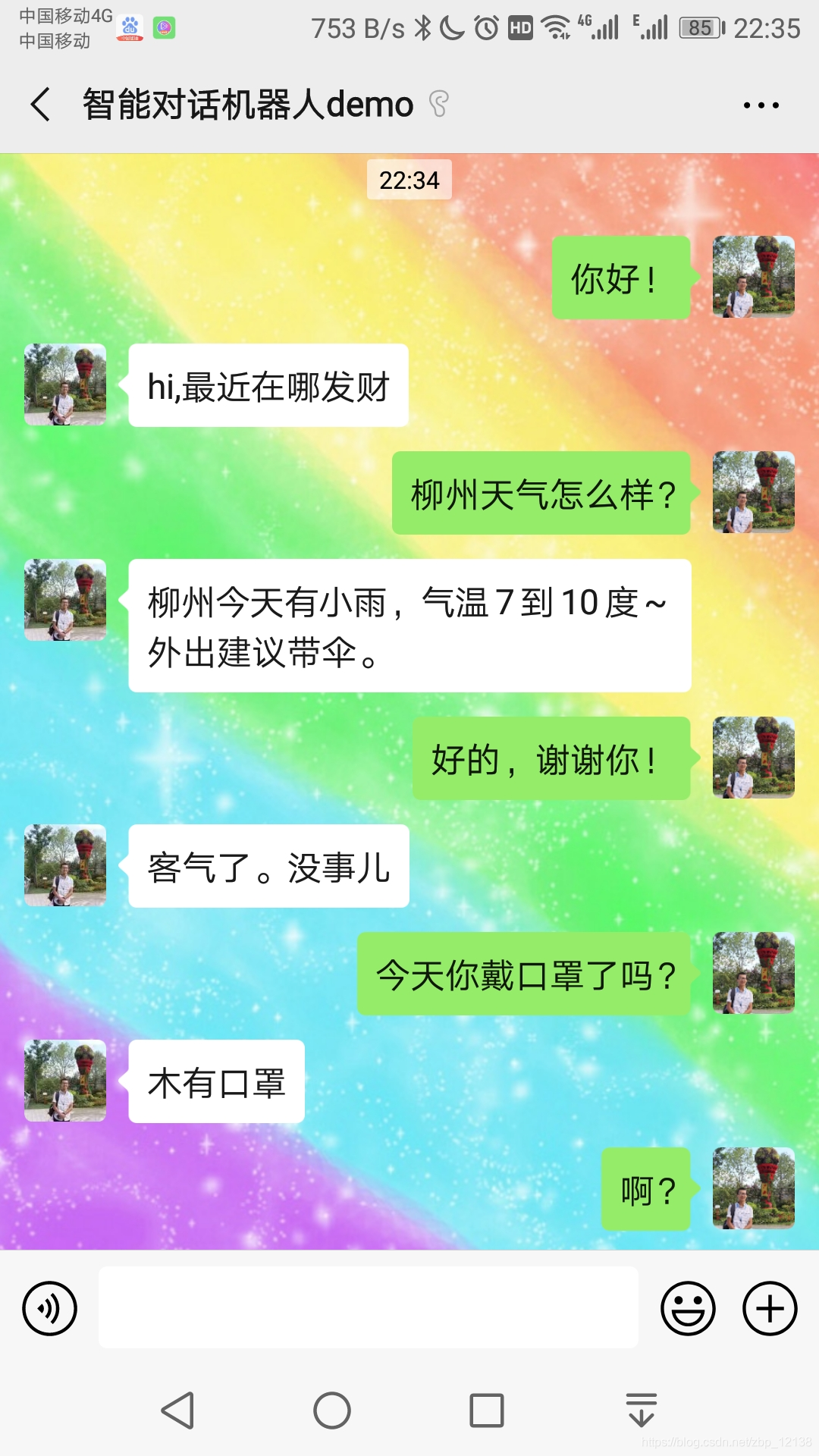
大家可以在微信搜索并尝试跟他聊天:智能对话机器人demo
以上就是全部内容,最后总结一下,在配置的过程中,尽量避免以下情况的使用:
- 每个模版只有一个模版片段
- 每个模版片段包含了多条关键信息,限制了句式的泛化能力
- 每个模版所有模版片段都为必须匹配
对于如何搭建智能对话系统,大家可以打开下面的链接进行更细致的学习:
http://bit.baidu.com/products?id=108