最近疫情肆虐,实现了我在家办公的愿望,也有更多的时间学习了,于是我参加百度深度学习集训营,刚刚接触新领域,以下是我整理的学习笔记,与大家分享:

首先是此次的作业帖:https://ai.baidu.com/forum/topic/show/957882看大家的帖子,也会有不少启发,下面,我们一起用Jieba模型对人民日报语料完成切词,并通过统计每个词出现的概率,计算信息熵。
“熵”就是关于不确定性的一个极好的数学描述。
而信息熵可以简单理解为“不确定现象”的数学化度量,换句话说,信息量越大,则信息熵也越大
编程需要依据具体的原理,下面我们来看看计算信息熵的公式:
其中n是类别数,p(xi)是第i类的概率
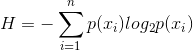
有了这个基础以后,就可以来编写代码了:
def calcShannonEnt(self,dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
print(key,"出现的概率:",prob)
shannonEnt -= prob * log(prob,2)
print("信息熵:",shannonEnt)
return shannonEnt
网上有很多代码,这里我选了一个比较适用的并简单修改了一下
在使用之前,我们还需要数据,这里选择了人民日报语料(语料地址:https://github.com/fangj/rmrb/tree/master/example/1946%E5%B9%B405%E6%9C%88)
直接在GitHub上下载的速度挺慢的,好在有万能的群友:
下面是码云的地址:https://gitee.com/
亲测有效!在GitHub上下一个网上都没有下完的项目,在码云里分分钟搞定!
下面我们开始切词!(因为数量太多,这里只选了三篇文章)
def demarcate(self):
path = r"C:\Users\Administrator\Downloads\zheng_bo_pu-rmrb-master\rmrb\example\1946年05月"
texts = ["1946-05-15_新闻界的祝贺",
"1946-05-15_劳动的妇女们",
"1946-05-15_五月杂感"]
lists = []
jieba.enable_paddle()# 启动paddle模式。 0.40版之后开始支持,早期版本不支持
for text in texts:
str = open(path+'\\'+text+'.md',encoding='utf-8').read()
# print(str)
seg_list = jieba.cut(str,use_paddle=True) # 使用paddle模式
lists += seg_list
print(lists)
# print("Paddle Mode: " + '/'.join(list(seg_list)))
self.calcShannonEnt(lists)
来看看效果(数量太多,只展示一部分):
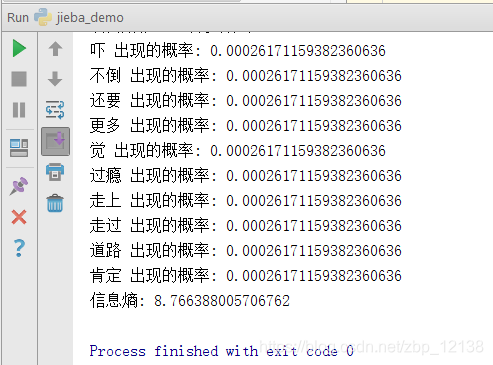
这样看到三篇文章合起来的信息熵是8.8
再来看看每个词出现的概率,我们往上翻:
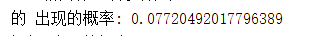
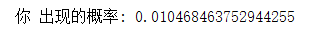
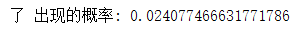
这几个词出现的概率都挺高的,大部分被切出来的词只出现过一次
接下来,思考一下:假设输入一个词表里面含有N个词,输入一个长度为M的句子,那么最大前向匹配的计算复杂度是多少?
先来看看什么是最大前向匹配算法:
我们分词的目的是将一段中文分成若干个词语,前向最大匹配就是从前向后寻找在词典中存在的词
这里我打算举个例子来分析:“祝人民日报创刊”
这句话含有3个词(祝、人民日报、创刊),句子的长度为7,使用最大向前匹配算法取词,如果匹配失败,每次去掉匹配字段最后面的一个字:
第一轮:
- “祝人民日报创刊”,没有匹配,去掉一个字,变为"祝人民日报创"
- “祝人民日报创”,没有匹配,去掉一个字,变为"祝人民日报"
- “祝人民日报”,没有匹配,去掉一个字,变为"祝人民日"
- “祝人民日”,没有匹配,去掉一个字,变为"祝人民"
- “祝人民”,没有匹配,去掉一个字,变为"祝人"
- “祝人”,没有匹配,去掉一个字,变为"祝"
- “祝"成功匹配,去掉"祝”,进行下一轮
第二轮:
- “人民日报创刊”,没有匹配,去掉一个字,变为"人民日报创"
- “人民日报创”,没有匹配,去掉一个字,变为"人民日报"
- “人民日报”,成功匹配,去掉"人民日报",进行下一轮
第三轮:
- "创刊"成功匹配,句子结束,结束循环
由此我们看到使用最大向前匹配算法切词时,词表里面含有N个词则进行N轮循环,而一轮循环下又有循环,最大循环次数为M(句子长度),因此时间复杂度用大O表示法可以表示为O(NM)
接着是第二个问题:给定一个句子,如何计算里面有多少种分词候选
我们还是拿刚刚的例子举例:‘祝人民日报创刊’,一说到有多少种情况,我想到的是阶乘,这句话有7个字,如果按照7的阶乘算:7654321=5040
当然,这里不是列出这七个字所有的排列组合,至少把顺序给出来了,那结果肯定就要比5040要少。除此之外,我们还可以通过规定词语的最大长度,但是题目没有规定,我们则按最大长度为7来执行,下面是词典:
self.dic = ['祝人民日报创刊','祝人民日报创','人民日报创刊','祝人民日报','人民日报创','民日报创刊','祝人民日','人民日报','民日报创','日报创刊','祝人民','人民日','民日报','日报创','报创刊','祝人','人民','民日','日报','报创','创刊','祝','人','民','日','报','创','刊']
下面是完整的代码,在参考了 “纠缠state” 写的代码后进行的修改:
class NLP_DEMO(object):
def __init__(self):
self.dic = ['祝人民日报创刊','祝人民日报创','人民日报创刊','祝人民日报','人民日报创','民日报创刊','祝人民日','人民日报','民日报创','日报创刊','祝人民','人民日','民日报','日报创','报创刊','祝人','人民','民日','日报','报创','创刊','祝','人','民','日','报','创','刊']
self.str = '祝人民日报创刊'
self.length = len(self.str)
self.res_list, self.res = [], []
def count_seg(self, idx):
if idx>=self.length:
if self.res.copy() not in self.res_list:
self.res_list.append(self.res.copy())
print(self.res)
return
for i in range(idx,self.length+1):
if self.str[idx:i] in self.dic:
self.res.append(self.str[idx:i])
self.count_seg(i)
self.res.pop()
def out_put(self):
print("一共有{:d}种分词方式".format(len(self.res_list)))
def main():
nlp_demo = NLP_DEMO()
nlp_demo.count_seg(0)
nlp_demo.out_put()
if __name__ == '__main__':
main()
程序运行结果如下:
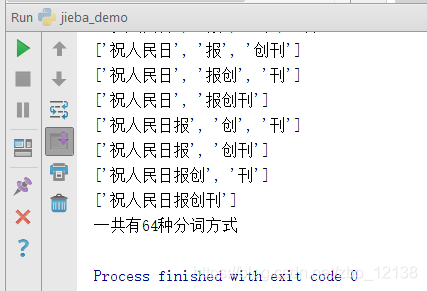
一共有64种分词方式,分别是:
[‘祝’, ‘人’, ‘民’, ‘日’, ‘报’, ‘创’, ‘刊’]
[‘祝’, ‘人’, ‘民’, ‘日’, ‘报’, ‘创刊’]
[‘祝’, ‘人’, ‘民’, ‘日’, ‘报创’, ‘刊’]
[‘祝’, ‘人’, ‘民’, ‘日’, ‘报创刊’]
[‘祝’, ‘人’, ‘民’, ‘日报’, ‘创’, ‘刊’]
[‘祝’, ‘人’, ‘民’, ‘日报’, ‘创刊’]
[‘祝’, ‘人’, ‘民’, ‘日报创’, ‘刊’]
[‘祝’, ‘人’, ‘民’, ‘日报创刊’]
[‘祝’, ‘人’, ‘民日’, ‘报’, ‘创’, ‘刊’]
[‘祝’, ‘人’, ‘民日’, ‘报’, ‘创刊’]
[‘祝’, ‘人’, ‘民日’, ‘报创’, ‘刊’]
[‘祝’, ‘人’, ‘民日’, ‘报创刊’]
[‘祝’, ‘人’, ‘民日报’, ‘创’, ‘刊’]
[‘祝’, ‘人’, ‘民日报’, ‘创刊’]
[‘祝’, ‘人’, ‘民日报创’, ‘刊’]
[‘祝’, ‘人’, ‘民日报创刊’]
[‘祝’, ‘人民’, ‘日’, ‘报’, ‘创’, ‘刊’]
[‘祝’, ‘人民’, ‘日’, ‘报’, ‘创刊’]
[‘祝’, ‘人民’, ‘日’, ‘报创’, ‘刊’]
[‘祝’, ‘人民’, ‘日’, ‘报创刊’]
[‘祝’, ‘人民’, ‘日报’, ‘创’, ‘刊’]
[‘祝’, ‘人民’, ‘日报’, ‘创刊’]
[‘祝’, ‘人民’, ‘日报创’, ‘刊’]
[‘祝’, ‘人民’, ‘日报创刊’]
[‘祝’, ‘人民日’, ‘报’, ‘创’, ‘刊’]
[‘祝’, ‘人民日’, ‘报’, ‘创刊’]
[‘祝’, ‘人民日’, ‘报创’, ‘刊’]
[‘祝’, ‘人民日’, ‘报创刊’]
[‘祝’, ‘人民日报’, ‘创’, ‘刊’]
[‘祝’, ‘人民日报’, ‘创刊’]
[‘祝’, ‘人民日报创’, ‘刊’]
[‘祝’, ‘人民日报创刊’]
[‘祝人’, ‘民’, ‘日’, ‘报’, ‘创’, ‘刊’]
[‘祝人’, ‘民’, ‘日’, ‘报’, ‘创刊’]
[‘祝人’, ‘民’, ‘日’, ‘报创’, ‘刊’]
[‘祝人’, ‘民’, ‘日’, ‘报创刊’]
[‘祝人’, ‘民’, ‘日报’, ‘创’, ‘刊’]
[‘祝人’, ‘民’, ‘日报’, ‘创刊’]
[‘祝人’, ‘民’, ‘日报创’, ‘刊’]
[‘祝人’, ‘民’, ‘日报创刊’]
[‘祝人’, ‘民日’, ‘报’, ‘创’, ‘刊’]
[‘祝人’, ‘民日’, ‘报’, ‘创刊’]
[‘祝人’, ‘民日’, ‘报创’, ‘刊’]
[‘祝人’, ‘民日’, ‘报创刊’]
[‘祝人’, ‘民日报’, ‘创’, ‘刊’]
[‘祝人’, ‘民日报’, ‘创刊’]
[‘祝人’, ‘民日报创’, ‘刊’]
[‘祝人’, ‘民日报创刊’]
[‘祝人民’, ‘日’, ‘报’, ‘创’, ‘刊’]
[‘祝人民’, ‘日’, ‘报’, ‘创刊’]
[‘祝人民’, ‘日’, ‘报创’, ‘刊’]
[‘祝人民’, ‘日’, ‘报创刊’]
[‘祝人民’, ‘日报’, ‘创’, ‘刊’]
[‘祝人民’, ‘日报’, ‘创刊’]
[‘祝人民’, ‘日报创’, ‘刊’]
[‘祝人民’, ‘日报创刊’]
[‘祝人民日’, ‘报’, ‘创’, ‘刊’]
[‘祝人民日’, ‘报’, ‘创刊’]
[‘祝人民日’, ‘报创’, ‘刊’]
[‘祝人民日’, ‘报创刊’]
[‘祝人民日报’, ‘创’, ‘刊’]
[‘祝人民日报’, ‘创刊’]
[‘祝人民日报创’, ‘刊’]
[‘祝人民日报创刊’]
最后一个问题:除了最大前向匹配和N-gram算法,你还知道其他分词算法吗?
既然刚刚提到了最大前向匹配算法,那我自然而然就想到了最大后向匹配算法,与前向最大匹配算法类似,只是方向相反,即从后向前寻找词典中存在的词并输出。
而双向最大匹配算法是前两者的集合:
- 比较正向最大匹配和逆向最大匹配结果。
- 如果分词数量结果不同,那么取分词数量较少的那个;如果分词数量结果相同: (1).分词结果相同,可以返回任何一个 (2).分词结果不同,返回单字数比较少的那个
AI Studio用户名:哓哓晓培
账号:18877286876
