X64四级页表寻址的硬件机制
https://zhuanlan.zhihu.com/p/50824798
64位的CPU体系架构下,CPU层面的页映射使用的是四级映射。这个四级映射本质上就是把线性地址的48位分割成为5部分,前四部分用于索引找到最后的4KB的页,最后一部分作为页内的索引来最后定位物理地址。前四部分的索引就是四级映射的过程。
映射这里有两个非常明显的问题。一个是一个48位的线性地址,为什么要分成五级去映射到最后的地址,而不是直接使用这个48位的地址值去寻找到那个地址位置?另外一个是大页如何处理?
四级映射在4KB的页映射的时候,确实是四级索引,算上页内偏移一共五级。但是Intel的CPU还是支持其他的大页的,64位的架构下,还可以支持2MB和1GB的大页。2MB的时候,最后一级的页索引地址就直接与页内便宜融合了,变成了三级索引。前三级的位数与默认的四级索是一样的,只是少了最后一级。1GB的大页则是进一步减少了一级的索引,也就是只是使用了两级的索引来完成页查找,后面的地址位就都是作为页内偏移存在了。虽然如此,64位下的寻址方式仍然叫做四级寻址,随后后面两级是可以选择关闭的。
64位的地址寻址空间下,只使用了48位,这是Intel在实现64位的CPU的时候,考虑到48位已经足够了,所以就只使用了48位(毕竟多一位就要对应的多非常昂贵的地址线),我们根据上述的对不同的页大小的支持可以很容易的分析出来每一级需要的位的数量。
4KB的大页,课件最后一级的偏移肯定是12位的,2MB的大页会吃掉最后一级的寻址位,2MB是21位,减去4KB的12位,对应的第四级索引就是9位。1GB是30位,减去2MB的21位,对应的第三级的索引就是9位,可见三级和四级的索引位数是一样的,都是9位,最后一级是12位,那么第一级和第二级的总位数就是48-30=18位。
四级索引中第一级比较特殊,有一个专门的名字,叫做PML4表,这个表的位置占了线性地址的前9位,也就是说第一级的索引也是9位,第二级的索引自然也是9位。如此我们可以发现,整个四级索引,每一级都是9位,一共36位的页索引地址,最后12位是页内偏移。
这里就要引出索引和偏移的区别,本来48位的线性地址,硬生生的被分为索引和偏移两部分,两个代表的却都不是实际的地址。都相当于是偏移,只是针对的是不同的数组的偏移。
4级索引的第一级的PML4表,固定的位于系统寄存器CR3指向的地址。CR3中的51-12位,一共40位,指定了PML4表位于的绝对地址。这里的51就是说48位的线性地址实际上是展开成52位的原因,因为任何一个页表都是4KB的大小,所以地址的低12位都是没有意义的,都应当是零。所以在表示索引表的地址的时候,都是从12位以上的部位开始,虽然理论上只需要36位就可以表示了所有的页,但是Intel的CPU还是设计了40位,也就是总线型地址的大小是52位。但是我们实际在索引和表示的时候都是使用48位,事实上51-12位中,多出来的前面四位都是零的话,实际上也就是48位在索引了。
由于40位的页地址已经超过了整个线型地址空间的大小,所以PML4表可以分布在任何的线性地址空间上。但是区别是CR3中的地址的内容是不需要再经过页转换的物理地址,而日常系统和进程使用的线性地址,是强制需要经过CPU的页转换架构才能得到最后的48位的物理地址的(实际上是可以展开成52字节)。
PML4表是一个512个元素的数组,每个元素的大小是64位,所以整个表正好是4KB的大小,也就是一个标准最小页的大小。四级缓存机制的一个有趣的设计是每一级的参数类似,例如每一级都占线性地址的9位。第二级的表叫做page-directory-pointer table (PDPT),顾名思义,这个表是一个指向页目录的指针表。如果把页定义位struct page,page directory就是struct page[],PDPT就是struct page[][],那么PML4就是struct page[][][]。我们编程的时候一般常见二级数组,在组织这种指向数组的指针的时候一般采用struct page**这种二级指针,所以PDPT看起来我们还能理解,也所以,PML4的名字看起来不能理解,三级数组,这在编程中实在是少见。也正是因为整个表组织成了不同级别的数组,PML4的表位于CR3指向的地址,那么PDPT的表又位于哪里的?既然是下一级的数组,那么必然是每一个PML4的条目都对应一个PDPT表,所以共有512个PDPT表,每一个PDPT表的位置,都是位于一个PML4条目的51-12位。这个设计又直接呼应了CR3的51-12位对应PML4表的地址一样。这51-12位是40位,用于索引页,不能能覆盖,还能超出所有的页地址的范围。
从PML4表看,它相当于把整个48位的线性地址空间划分位512个地址空间,也就是每一个地址空间对应的是512GB(2^(48-9)),选择了一个PML4表中的一个条目,就相当于选择了一个512GB的地址块。同理,在PDPT中也是存在512个64位的索引表(与PML4格式一模一样),那么相当于选择了一个PDPT也就是选择了一个1GB的地址块(2^(48-9-9))。这个时候就会引出上面说的大页的问题了。如何实现大页的秘密就在PDPT中,由于PDPT的每一个条目都只有40位来表示下一级页目录的地址,而一个条目有64个位,所以就剩下24个位可以用来做跟这个层级的地址空间相关的控制标志了(1GB大小的访问控制)。如下是PDPL每一位的定义。
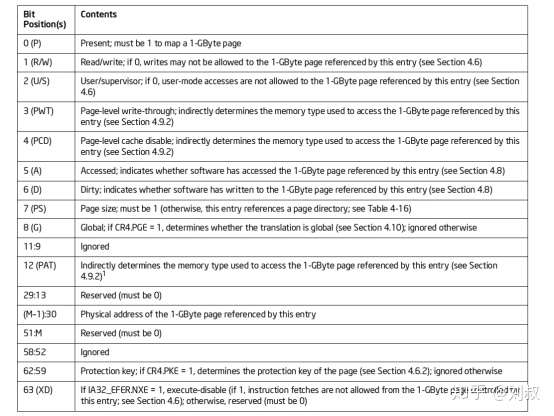
51-12位就是之前说的那40位用于指明下一级的索引页的地址。上表中有一个特殊的地方,就是第7位的PS位。如果这个PDPT的PS位是0,那么就表示这个PDPT条目本身就已经是最后一级的页索引了。前面说过一个PDPT条目相当于一个1GB的地址选择范围,那么如果PS位是0,那么就相当于是这个PDPT条目直接指向了实际的1GB的大页。
如果PS是0,我们这个PDPT采用了1GB的大页,那么这个时候线性地址空间中还会有48-18=30位作为页内偏移,也就是1GB的二进制大小。为了形成最后的52位的线性地址,还需要PDPT的22位提供,也就是51-30位的空间。一共就是最后的52位的物理地址了。
如果PS是0,索引会继续进行,那么这个PDPT并不是最后一级,就会像PML4一样,拿出自己的51-12位作为下一级索引的40位页地址。
下一级页表叫做PDE(page directory),这一级的意义和格式,几乎可以以此类推的很容易的想到。由于选择了一个PDE条目就相当于选择了一个2MB的地址空间,因而PDE这个条目就可以跟PDPT一样的方式支持2MB的大页了。也还是一样的索引方式用于组成最后的物理地址,也还是一样的索引方式用于索引下一级的页表。
最后一级的页表叫做PTE,索引下一级的方式也是与上面的级别相同,不同的是,这一级由于是最后一级,不能选择再支持更大的页表了,因为到了这一级已经是固定的4KB的页表大小了。
整个四级索引的过程下来,我们可以看到,一个线性地址的前面4个9位,都是用于各自级别的表的索引,而不是一个地址值。第一个表示PML4,这个表的位置由CR3系统寄存器给出,后面的每个表的物理地址都是有上级的表条目中的51:12位给出。而线性地址中的接下来的9位仅仅是用于在这个层级的表中的索引,选择一个条目,这个被选择的条目中包含了40位的下一级表的地址和24位的控制位。
页表制度最核心的功能都是通过每一级多出来的这24个位来实现的。否则我们单看整个流程下来,虽然48位被展开成了52位,但是展开之后的地址仍然是48位的实际访问空间,不如直接用线性地址直接访问。
接下来的问题就变成了,为什么需要这么大费周章的进行页表转换,而不是直接使用48位的线性地址来直接作为物理地址?一个众所周知的最大的作用就是写时映射。可以让物理内存小于实际的48位的地址空间(256TB)。如果不这么做,那么由于一个进程必须要写整个线性空间的地址,我们就得保证每一个进程都需要知道哪一些地址段是没有对应物理地址的,哪些是对应的,否则如果进程访问了没有对应物理存储的地址位置,就会引起错误。所以,这种机制也就使得我们不必要每个机器都必须要提供256TB的内存了。
这么多步骤,还不是为了让进程有一个连续可用的地址空间嘛!你可以叫用户看到的地址空间是虚拟空间,但是用于给到CPU的确实是真实的线性地址。只是CPU需要把这个线性地址实际的转变为物理地址。通过这一套的机制,使得每一个进程都可以看到全部可用的线性地址空间。
当然,大费周章的四级页表机制的意义远不止于此,只是这个缺页异常的理由比较常见和容易理解。别忘了,我们还有24个位没有解释他们的意义。四级页表每一级的每一个条目都有24位的控制位,那相当于恐怖的512*24*512*24*512*24*512*24,一共这么多个位能用来控制页表的行为。着实是一个很了不起的庞大的系统。