| 作业要求 | https://edu.cnblogs.com/campus/jssf/infor_computation17-31/homework/10534 |
|---|---|
| 我在这个课程的目标是 | 提高自己的相关能力 |
| 此作业在哪个具体方面帮我实现目标 | 接触并掌握新的软件功能 |
| 作业正文 | https://www.cnblogs.com/wyc1/p/12635120.html |
作业1
每个人针对之前两次作业所写的代码,针对要求,并按照代码规范(风格规范、设计规范)要求评判其他学生的程序,同时进行代码复审(按照代码复审核表 https://www.cnblogs.com/xinz/archive/2011/11/20/2255971.html),要求评价数目不少于8人次,
评价内容直接放在你被评价的作业后面评论中
同时另建立一个博客,将你作的评论的截图或者链接,放在博客中,并在你的博客中谈谈自己的总体看法
写博客仍然按照之前格式要求处理








总结
评价的很多代码没有进行必要注释,就增加了代码的阅读难度。大部分同学们的作业都开始注意规范,但是还有一些作业没有满足要求,而代码复审让我们通过别人发现自己的错误与不足,也通过别人提高自己。
作业二
两人自由组队进行结对编程
参考结对编程的方法、过程(https://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html)开展两人合作完成本项目
实现一个简单而完整的软件工具(中文文本文件人物统计程序):针对小说《红楼梦》要求能分析得出各个人物在每一个章回中各自出现的次数,将这些统计结果能写入到一个csv格式的文件。
进行单元测试、回归测试、效能测试,在实现上述程序的过程中使用相关的工具。
进行个人软件过程(PSP)的实践,逐步记录自己在每个软件工程环节花费的时间。
使用源代码管理系统 (GitHub, Gitee, Coding.net, 等);
针对上述形成的软件程序,对于新的文本小说《水浒传》分析各个章节人物出现次数,来考察代码。
将上述程序开发结对编程过程记录到新的博客中,尤其是需要通过各种形式展现结对编程过程,并将程序获得的《红楼梦》与《水浒传》各个章节人物出现次数与全本人物出现总次数,通过柱状图、饼图、表格等形式展现。
《红楼梦》与《水浒传》的文本小说将会发到群里。
运行结果
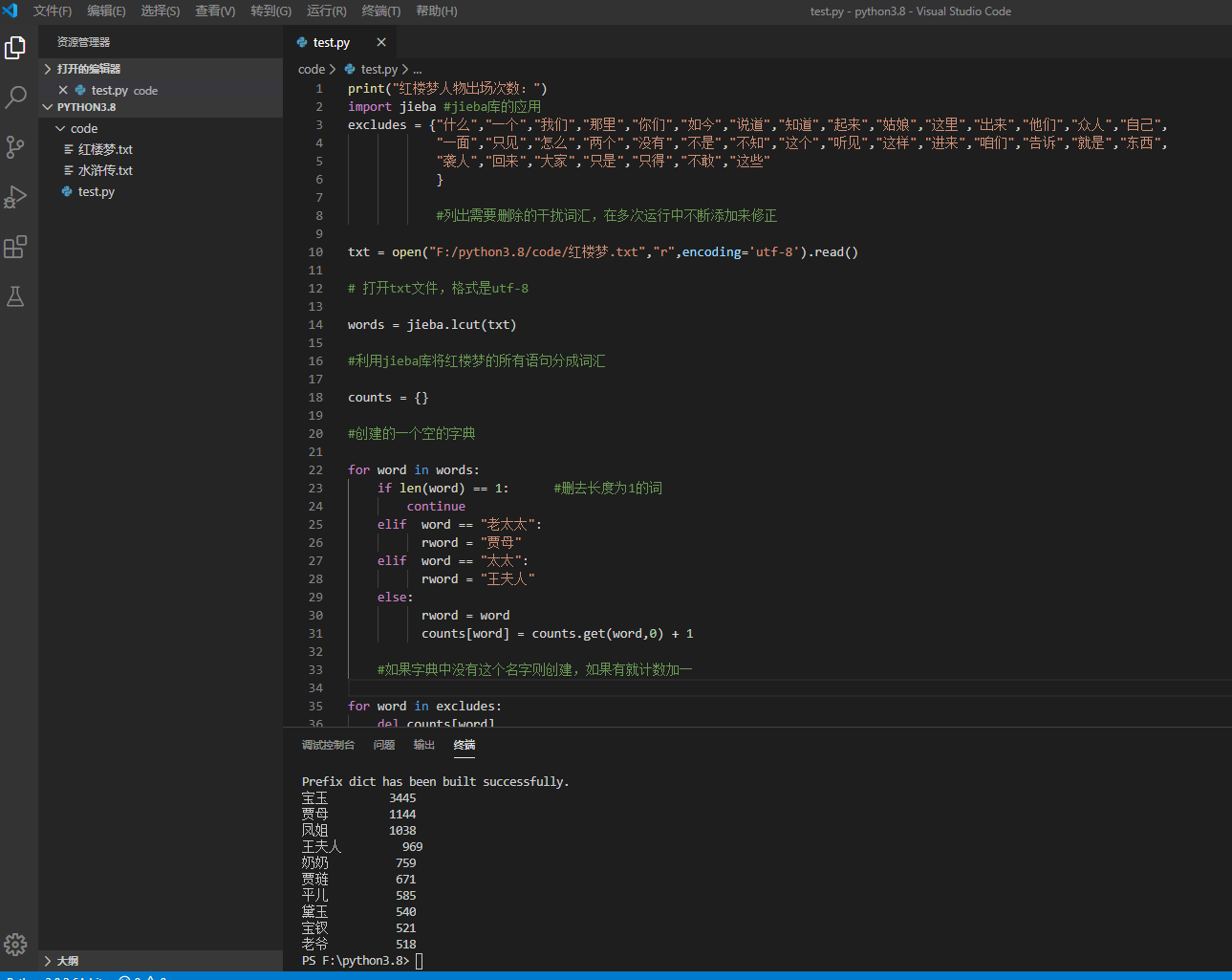
程序
print("红楼梦人物出场次数:")
import jieba #jieba库的应用
excludes = {"什么","一个","我们","那里","你们","如今","说道","知道","起来","姑娘","这里","出来","他们","众人","自己",
"一面","只见","怎么","两个","没有","不是","不知","这个","听见","这样","进来","咱们","告诉","就是","东西",
"袭人","回来","大家","只是","只得","不敢","这些"
}
#列出需要删除的干扰词汇,在多次运行中不断添加来修正
txt = open("F:/python3.8/code/红楼梦.txt","r",encoding='utf-8').read()
# 打开txt文件,格式是utf-8
words = jieba.lcut(txt)
#利用jieba库将红楼梦的所有语句分成词汇
counts = {}
#创建的一个空的字典
for word in words:
if len(word) == 1: #删去长度为1的词
continue
elif word == "老太太":
rword = "贾母"
elif word == "太太":
rword = "王夫人"
else:
rword = word
counts[word] = counts.get(word,0) + 1
#如果字典中没有这个名字则创建,如果有就计数加一
for word in excludes:
del counts[word]
#删除干扰词
items = list(counts.items())
#把保存[姓名:个数]的字典转换成列表
items.sort(key=lambda x:x[1],reverse = True)
#对上述列表进行排序,'True'是降序排列
for i in range(10):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))
#输出前十个结果
总结
为了解决这个问题,我开始去了解python语言,并通过一些教程从安装开始慢慢学习入门python,期间也遇到了很多问题,最终也通过搜索各种方法解决了。
知道了jieba库这个的可以帮助统计分词的第三方库,也开始尝试使用vscode作为编辑器来编写程序。
目前对于python这门语言和软件的具体使用方法仅仅是片面的了解,运用起来非常不熟练,必须依靠搜索到的教程及去模仿别人的程序。
但是python语言也有自身的优势,相对易学,Python标准库很庞大,python有可定义的第三方库可以使用。
它可以帮助你处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。“功能齐全”。
除了标准库以外,还有许多其他高质量的库,如wxPython、Twisted和Python图像库等等。
希望以后也可以慢慢去学习运用这门新的语言。