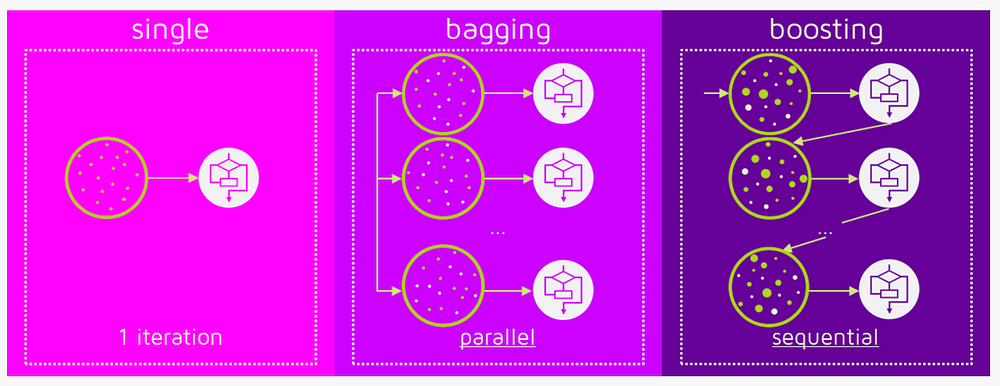
Objective of ensemble methods is to combine the predictions of serveral base estimators ( Linear Regression, Decisison Tree, etc. ) to create a combined effect or more genralized model.
Two types of Ensemble Method
Averaging Method : Build several estimators independently & average their predictions. Examples are RandomForest etc.
Boosting Method : Base estimators are built sequentially using weighted version of data .i.e fitting models with data that were mis-classified. Examples are AdaBoost
Recap - Limitations of decison tree is that it overfits & shows high variance.
RandomForest is an averaging ensemble method whose prediction is function of prediction of ‘n’ decision trees.
Algorithm算法
Data consist of R rows & M features.
Sample of training data is taken.
Random set of features are selected.
As many as configured number of trees are created using above two steps.
Final prediction in case of classification is majority prediction.
Final prediction in case of regression is mean/median of individual tree prediction
数据由R行和M特征组成。
取训练数据样本。
选择随机特征。
使用以上两个步骤创建的树数多达配置的数目。
分类时的最终预测为多数预测。
回归时的最终预测是单个树预测的均值/中位数
Comparing Decision Tree & Random Forest for MNIST data
from sklearn.datasets import load_digits
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
d:\Anaconda3\lib\site-packages\sklearn\ensemble\forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22.
"10 in version 0.20 to 100 in 0.22.", FutureWarning)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)
rf.score(testX,testY)
0.9422222222222222
Important Hyper-parameters重要的超参数
n_estimators : number of trees to be configured, larger is better but compute cost.
max_features : maximum number of features to be considered for splitting the node. For classification this equals to sqrt(n_features). And, for regression max_features = n_features.
n_jobs : Configure as -1 so that we can make use of all cores.
Boosting in general is about building a model from the training data, then creating a second model that attempts to correct the errors from the first model. Models are added until the training set is predicted perfectly or a maximum number of models are added.
AdaBoost was first boosting algorithm.
AdaBoost can be used for both classification & regression
Algorithm算法
Core concept of adaboost is to fit weak learners ( like decision tree ) sequantially on repeatedly modifying data.
Initially, each data is assigned equal weights.
A base estimator is fitted with this data.
Weights of misclassified data are increased & weights of correctly classified data is decreased.
Repeat the above two steps till all data are correctly classified or max number of iterations configured.
Making Prediction : The predictions from all of them are then combined through a weighted majority vote (or sum) to produce the final prediction.
A machine learning technique for regression and classification problems, which produces a prediction model in the form of an ensemble of weak prediction models, typically decision trees.
One of the very basic assumption of linear regression is that it’s sum of residuals is 0.
These residuals as mistakes committed by our predictor model.
Although, tree based models are not based on any of such assumptions, but if sum of residuals is not 0, then most probably there is some pattern in the residuals of our model which can be leveraged to make our model better.
So, the intuition behind gradient boosting algorithm is to leverage the pattern in residuals and strenghten a weak prediction model, until our residuals don’t show any pattern.
Algorithmically, we are minimizing our loss function, such that test loss reach it’s minima.
Problem : House Price Prediction using GradientBoostingTree
from sklearn.datasets import load_boston
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.ensemble import GradientBoostingRegressor
house_data = load_boston()
X = house_data.data
y = house_data.target
Core concept of VotingClassifier is to combine conceptually different machine learning classifiers and use a majority vote or weighted vote to predict the class labels.
Voting classifier is quite effective with good estimators & handles individual’s limitations, ensemble methods can also participate.
Types of Voting Classifier
Soft Voting Classifier, different weights configured to different estimator
Hard Voting Classifier, all estimators have equal weighage
Problem : DIGIT identification using VotingClassifier
from sklearn.ensemble import VotingClassifier,RandomForestClassifier,AdaBoostClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
d:\Anaconda3\lib\site-packages\sklearn\svm\base.py:193: FutureWarning: The default value of gamma will change from 'auto' to 'scale' in version 0.22 to account better for unscaled features. Set gamma explicitly to 'auto' or 'scale' to avoid this warning.
"avoid this warning.", FutureWarning)
d:\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
d:\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:469: FutureWarning: Default multi_class will be changed to 'auto' in 0.22. Specify the multi_class option to silence this warning.
"this warning.", FutureWarning)
0.9777777777777777
for est,name inzip(vc.estimators_,vc.estimators):print(name[0], est.score(testX,testY))
rf 0.9577777777777777
svc 0.49777777777777776
knc 0.9822222222222222
abc 0.8511111111111112
lr 0.9488888888888889
d:\Anaconda3\lib\site-packages\sklearn\svm\base.py:193: FutureWarning: The default value of gamma will change from 'auto' to 'scale' in version 0.22 to account better for unscaled features. Set gamma explicitly to 'auto' or 'scale' to avoid this warning.
"avoid this warning.", FutureWarning)
d:\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
d:\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:469: FutureWarning: Default multi_class will be changed to 'auto' in 0.22. Specify the multi_class option to silence this warning.
"this warning.", FutureWarning)
0.98