RDD中操作分类两大类型:转换(transformation)和行动(action)
转换:通过操作将一个RDD转换成另外一个RDD。
行动:将一个RDD进行求值或者输出。
所有这些操作主要针对两种类型的RDD:
(1) 数值RDD
(2) 键值对RDD
我们用的最多的就是键值对RDD,然后引起一些比如说数据的不平衡,这个也就是键值对RDD引起
的。
RDD的所有转换操作都是懒执行的,只有当行动操作出现的时候Spark才会去真的运行,也就是说不
管你前面定义了多少RDD的转换,你在做这件事的时候它是不执行的,只有你在触发RDD的action操
作的时候,它所有你前面定义的东西,它才会全部执行,那为什么这么做呢?其实spark是为了做优
化,就是在你定义的这条路径里面,就是不是所有人都能够定义的非常优化的一些操作,这个时候
spark就会去为你分析你的执行路径是否是最优的,如果不是最优的,它会帮你去把它做到最优化,
因为你前面都还没有触发,所以说spark可以决定哪些东西能触发,哪些东西不能触发,比如说你前
面定义了很多的转换操作,但是最后你没有设置一个行动操作,OK,那前面这些步骤对spark来说都
是无用的,也就是说我不用动这些东西,那么这个就是RDD的操作。
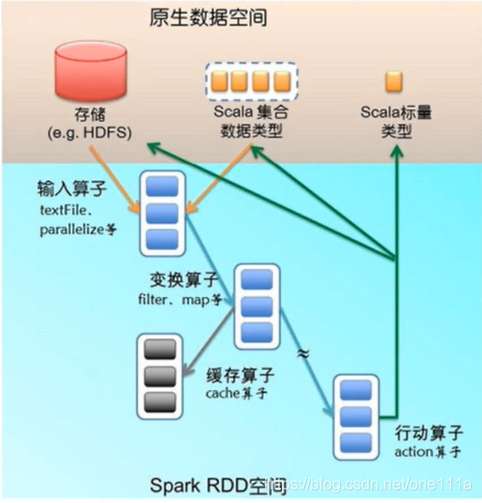
转换操作:是从一个RDD转换到另外一个RDD,也就是说它的输出结果是另外一个RDD。
行动操作:它的目的是把一个RDD转换成最终的数据,这个最终的数据要么是转换成scala里面的具
体的集合类型,要么直接存储到外部存储上,比如说save到整个的Hadoop上。
那这个是行动操作和转换操作它们的区别。
转换操作
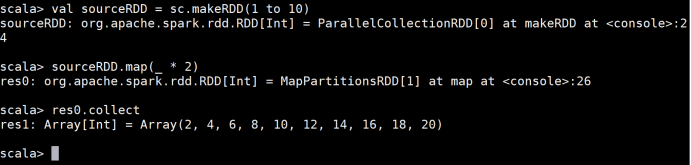
1 def map[U: ClassTag](f: T => U) 将函数应用于RDD的每一个元素,并返回一个新的RDD
2 def filter(f: T => Boolean) 通过提供的产生boolean条件的表达式来返回符合结果为True的新的
RDD

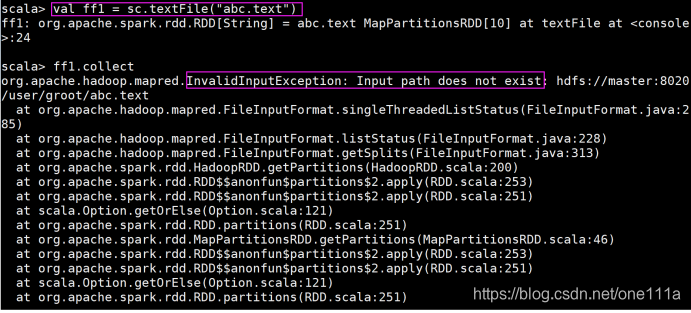
下面这个示例则证明了RDD的懒执行:
当我们在加载一个不存在的text文件时,我定义成功了,那这个时候我执行了一个collect,这个
collect就是将所有Worker节点上的数据去全都搂到Master节点上,那搂的时候就执行collect了,但这
个时候就发现它不存在,从这种方式就可以看出整个RDD的执行其实就是懒执行的操作。
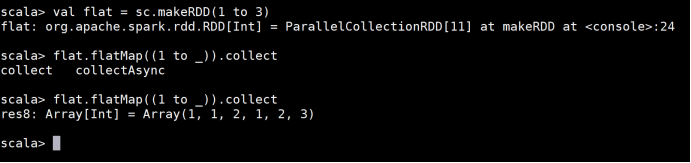
3 def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] 将函数应用于RDD中的每一项,
对于每一项都产生一个集合,并将集合中的元素压扁成一个集合。
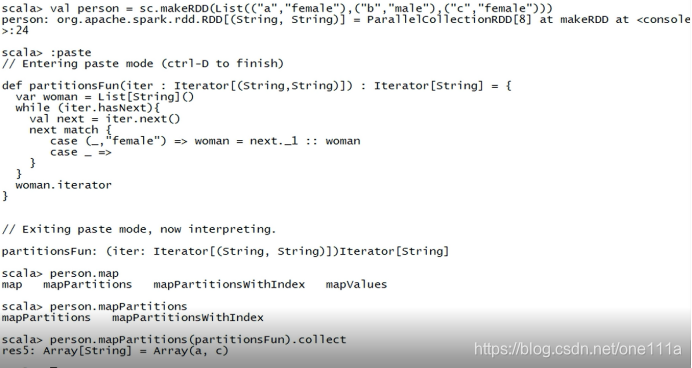
4 mapPartitions
def mapPartitions[U: ClassTag](f: Iterator[T] => Iterator[U],preservesPartitions: Boolean = false):
RDD[U]
将函数引用于RDD的每一个分区,每一个分区运行一次,函数需要能够接受Iterator类型,
然后返回Iterator.
// Entering paste mode (ctrl-D to finish)
def partitionsFun(index : Int, iter : Iterator[(String,String)]) : Iterator[String] = {
var woman = List[String]()
while (iter.hasNext){
val next = iter.next()
next match {
case (_,"female") => woman = "["+index+"]"+next._1 :: woman case _ => } }
woman.iterator
}
// Exiting paste mode, now interpreting.
partitionsFun: (index: Int, iter: Iterator[(String, String)])Iterator[String]
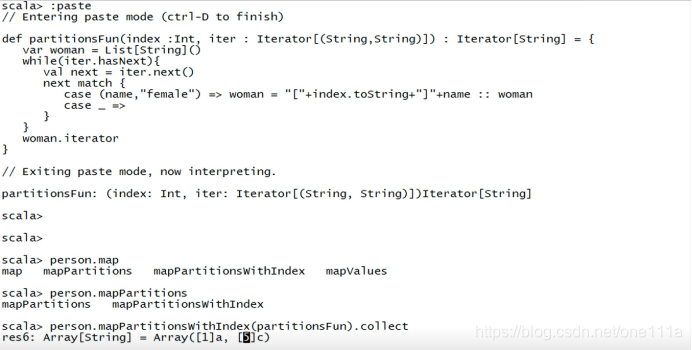
5 mapPartitionsWithIndex
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
将函数应用于RDD中的每一个分区,每一个分区运行一次,函数能够接受一个分区的索引值和一个代表分区内所有数据的Iterator类型,需要返回Iterator类型。
首先创建一个RDD:
val person = sc.makeRDD(List(("a","female"),("b","male"),("c","female")))
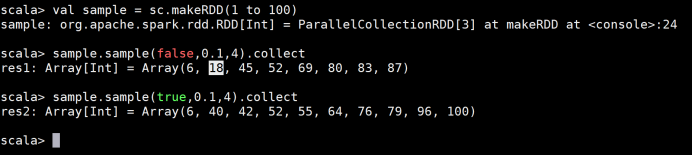
6 sample
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T]
在RDD中以seed为种子返回大致上有fraction比例个数据样本RDD,withReplacement表示是否采
用放回式抽样。