import matplotlib.pyplot as plt
import numpy as np
x_data = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.] # 进化前CP数据(10组)
y_data = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.] # 进化后CP数据(10组)
# y_data=b+w*x_data(假设模型)
x = np.arange(-200, -100, 1) # bias(b),从-200~-100,以步长1为间隔返回数组(100)
y = np.arange(-5, 5, 0.1) # weight(w),同上(100)
Z = np.zeros((len(x), len(y))) # 形状为len(x)*len(y)零数组(100*100),存放loss值的矩阵(x,y组成的数据对共100*100个)
X, Y = np.meshgrid(x, y) # 生成坐标矩阵
# 计算loss functon(遍历x,y,计算出每组数据的loss):当b=x[i],w=y[j]时,loss(f(w,b))=Σ(y_data[n]-b-w*x_data[n])**2
for i in range(len(x)):
for j in range(len(y)):
# 利用x,y中所有元素
b = x[i]
w = y[j]
Z[j][i] = 0 # 初始化loss值,用于累加
for n in range(len(x_data)):
Z[j][i] = Z[j][i] + (y_data[n] - b - w * x_data[n]) ** 2 # 计算数据对b=x[i],w=y[j]时总的loss值(利用十组样本数据)
Z[j][i] = Z[j][i] / len(x_data) # 求b=x[i],w=y[j]时的平均loss值
# y_data=b+w*x_data
b = -120 # 初始化w,b(随机的初始化,保证w,b在范围内即可)
w = -4
lr = 0.0000001 # learning rate(步长)
iteration = 100000 # 迭代数
# 存储b,w的历史值用于画图
b_history = [b]
w_history = [w]
# iterations
for i in range(iteration):
b_grad = 0.0 # b_grad,w_grad用于累加,所以初始化为0(≠b,w)
w_grad = 0.0
for n in range(len(x_data)):
b_grad = b_grad - 2.0 * (y_data[n] - b - w * x_data[n]) * 1.0 # loss函数对b求偏导
w_grad = w_grad - 2.0 * (y_data[n] - b - w * x_data[n]) * x_data[n] # loss函数对w求偏导
# update parameters
b = b - lr * b_grad # 向loss值减小方向移动,更新b,w值
w = w - lr * w_grad
# store parameters for plotting
b_history.append(b) # 将更新后的b,w值加入列表,绘制等高线
w_history.append(w)
# plot the figure
plt.contourf(x, y, Z, 50, alpha=0.5,
cmap=plt.get_cmap('jet')) # 输入x,y,Z(loss值)生成等高线,按照高度分为50层(颜色代表Z大小),并设置属性--透明度0.5,颜色‘jet’一种过度色
plt.plot([-188.4], [2.67], '+', ms=12, markeredgewidth=2, color='orange') # markeredgewidth设置标记的宽度,‘+’表示标记的形状
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100) # 限制x,y坐标范围
plt.ylim(-5, 5)
plt.xlabel(r'$b$', fontsize=16) # 设置坐标标签及其属性
plt.ylabel(r'$w$', fontsize=16)
plt.show()
print(w,b)#显示最终w,b的最佳值:2.6692640713379903 -188.3668387495323
代码主要是两部分:
1-loss矩阵(每对w,b的loss平均值)的求解
2-梯度下降法求解优化后的w,b(主要)
loss值以等高线的形式展示;
w,b为坐标轴
图中’+‘为w,b的最优解位置,黑色即为w,b的变化路线,背景色表示Z(loss)值的大小。

对learning rate进行优化—设置自适应learning rate(开始时lr大,随后逐渐变小),同时对不同的参数采取不同的lr,也即adagrad方法
公式为

其中g为第t次迭代的梯度,η为自己所设置的学习率。公式推导如下:

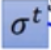
为RMS-均方根。下面是改进后的梯度下降:
# 版本2-优化模型使得b,w的learning rate不一样(adagrad方法)
import matplotlib.pyplot as plt
import numpy as np
x_data = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.] # 进化前CP数据(10组)
y_data = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.] # 进化后CP数据(10组)
# y_data=b+w*x_data(假设模型)
x = np.arange(-200, -100, 1) # bias(b),从-200~-100,以步长1为间隔返回数组(100)
y = np.arange(-5, 5, 0.1) # weight(w),同上(100)
Z = np.zeros((len(x), len(y))) # 形状为len(x)*len(y)零数组(100*100),存放loss值的矩阵(x,y组成的数据对共100*100个)
X, Y = np.meshgrid(x, y) # 生成坐标矩阵
# 计算loss functon(遍历x,y,计算出每组数据的loss):当b=x[i],w=y[j]时,loss(f(w,b))=Σ(y_data[n]-b-w*x_data[n])**2
for i in range(len(x)):
for j in range(len(y)):
# 利用x,y中所有元素
b = x[i]
w = y[j]
Z[j][i] = 0 # 初始化loss值,用于累加
for n in range(len(x_data)):
Z[j][i] = Z[j][i] + (y_data[n] - b - w * x_data[n]) ** 2 # 计算数据对b=x[i],w=y[j]时总的loss值(利用十组样本数据)
Z[j][i] = Z[j][i] / len(x_data) # 求b=x[i],w=y[j]时的平均loss值
# y_data=b+w*x_data
b = -120 # 初始化w,b(随机的初始化,保证w,b在范围内即可)
w = -4
lr = 1 # 改进四
iteration = 100000 # 迭代数
# 存储b,w的历史值用于画图
b_history = [b]
w_history = [w]
lr_b = 0
lr_w = 0 # 改进一,分别给予参数b,w不同的learning rate
# iterations
for i in range(iteration):
b_grad = 0.0 # b_grad,w_grad用于累加,所以初始化为0(≠b,w)
w_grad = 0.0
for n in range(len(x_data)):
b_grad = b_grad - 2.0 * (y_data[n] - b - w * x_data[n]) * 1.0 # loss函数对b求偏导
w_grad = w_grad - 2.0 * (y_data[n] - b - w * x_data[n]) * x_data[n] # loss函数对w求偏导
lr_b = lr_b + b_grad ** 2 # 改进二
lr_w = lr_w + w_grad ** 2
# update parameters
b = b - lr / np.sqrt(lr_b) * b_grad # 改进三
w = w - lr / np.sqrt(lr_w) * w_grad
# store parameters for plotting
b_history.append(b) # 将更新后的b,w值加入列表,绘制等高线
w_history.append(w)
# plot the figure
plt.contourf(x, y, Z, 50, alpha=0.5,
cmap=plt.get_cmap('jet')) # 输入x,y,Z(loss值)生成等高线,按照高度分为50层(颜色代表Z大小),并设置属性--透明度0.5,颜色‘jet’一种过度色
plt.plot([-188.4], [2.67], '+', ms=12, markeredgewidth=2, color='orange') # markeredgewidth设置标记的宽度,‘+’表示标记的形状
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100) # 限制x,y坐标范围
plt.ylim(-5, 5)
plt.xlabel(r'$b$', fontsize=16) # 设置坐标标签及其属性
plt.ylabel(r'$w$', fontsize=16)
plt.show()

如有不妥请指正,谢谢!
