Python开发之Pandas的简单使用(一)
前言:主要介绍了Series的创建、索引和切片以及DataFrame的创建和操作,csv数据的读取、排序、取行和取列,以及通过loc和iloc进行索引,以及布尔索引和缺失数据的处理。
1.Pandas介绍
- 什么是Pandas:pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
- 翻译成中文:pandas是BSD许可的开源库,为Python编程语言提供了高性能,易于使用的数据结构和数据分析工具。
- Pandas数据类型分为:(1)Series 一维,带标签数组。(2)DataFrame 二维,Series容器。
2.Series创建
代码:
import pandas as pd
import string
import numpy as np
t1 = pd.Series(np.arange(10), index=list(string.ascii_uppercase[:10]))
print("t1的类型:",type(t1))
print("t1:",t1)
print("*"*100)
t2 = pd.Series(np.arange(10), index=list(string.ascii_lowercase[:10]))
print("t2的类型",type(t2))
print("t2:",t2)
print("*"*100)
t3 = pd.Series(np.arange(10))
print("t3的类型:",type(t3))
print("t3:",t3)
print("*"*100)
a = {string.ascii_uppercase[i]:i for i in range(10)} #字典
print("a的类型:",type(a))
print("a:",a)
t4 = pd.Series(a)
print("t4的类型:",type(t4))
print("t4:",t4)
print("*"*100)
# numpy中的nan为float类型,pandas会自动根据数据类型更改series中的dtype
t5 = pd.Series(a, index=list(string.ascii_uppercase[5:15]))
print("t5的类型",type(t5))
print("t5:",t5)
输出:





3.Series索引和切片
代码:
import pandas as pd
import string
import numpy as np
t1 = pd.Series(np.arange(10), index=list(string.ascii_uppercase[:10]))
print("t1的类型:",type(t1))
print("t1:\n",t1)
print("*"*100)
print("t1的索引:",t1.index)
print("t1的索引转换成list:",t1.index.tolist())
print("t1的values:",t1.values)
print("t1的values转换成list:",t1.values.tolist())
print("*"*100)
print("取第二index对应的value值:",t1[1])
print("*"*100)
print("取""F""对应的value值:",t1["F"])
print("*"*100)
print("从c开始,每隔1个取一次:\n",t1[2:10:2]) #从c开始,每隔1个取一次
print("*"*100)
print("取第三个 第四个 第七个:\n",t1[[2,3,6]]) #取第三个 第四个 第七个
print("*"*100)
print("取第6个之后:\n",t1[t1>4]) #取第六个之后
print("*"*100)
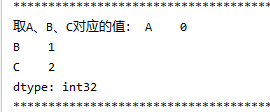
print("取A、B、C对应的值:",t1[["A","B","C"]])
print("*"*100)
输出:


4.DataFrame创建和简单操作
- ataFrame对象既有行索引,又有列索引
- 行索引,表明不同行,横向索引,叫index,0轴,axis = 0
- 列索引,表明不同列,纵向索引,叫columns,1轴,axis = 1
代码:
import pandas as pd
import numpy as np
import string
t = pd.DataFrame(np.arange(12).reshape((3,4)))
print("t:")
print(t)
t1 = pd.DataFrame(np.arange(12).reshape(3,4),
index= list(string.ascii_uppercase[:3]),
columns=list(string.ascii_uppercase[-4:]))
print("t1:")
print(t1)
print("*"*100)
print("t1的行数和列数:",t1.shape)#行数 列数
print("t1的数据类型:",t1.dtypes)#列数据类型
print("t1的数据维度:",t1.ndim)#数据维度
print("t1的行索引:",t1.index)#行索引
print("t1的列索引:",t1.columns)#列索引
print("t1的对象值:",t1.values)#对象值
print("*"*100)
print("t1的头部2行:",t1.head(2))#头部几行
print("t1的末尾2行:",t1.tail(2))#末尾几行
print("*"*100)
print("t1的信息:",t1.info())#信息
print("*"*100)
print("t1的描述:",t1.describe())
输出:



5.读取csv数据、排序、取行取列
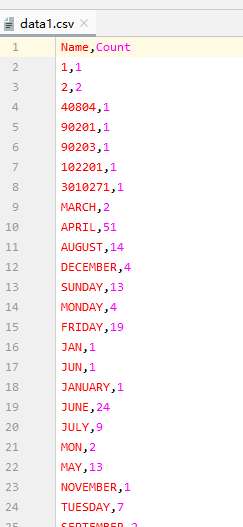
先看一下数据的样式(按照样式,自己新建个文件添写几个数据即可):
代码:
import pandas as pd
t1 = pd.read_csv("./data1.csv")
print("t1的前5行",t1.head(5))
print("*"*100)
print("t1的信息:",t1.info())
print("*"*100)
#dataFrame中排序的方法
t2 = t1.sort_values(by = "Count",ascending=False)
print("根据count排序之后的t2前5行:",t2.head(5))
print("*"*100)
#pandas取行或者列的注意点
# - 方括号写数组,表示取行,对行进行操作
# - 写字符串,表示的取列索引,对列进行操作
print("t1的前20行:",t1[:20])
print("*"*100)
print("取Name列:",t1["Name"])
print("Name列的数据类型:",type(t1["Name"]))
输出:



6.loc:通过标签索引行数据
代码:
import pandas as pd
import numpy as np
import string
t = pd.DataFrame(np.arange(12).reshape(3,4),
index= list(string.ascii_uppercase[:3]),
columns=list(string.ascii_uppercase[-4:]))
print("t:")
print(t)
print("*"*100)
print("取A行W列对应的值:",t.loc["A","W"])
print("*"*100)
print("取A、B行和W、X列对应的值:")
print(t.loc[["A","B"],["W","X"]])
print("*"*100)
print("取A行之后(包括A)和W、X、Z列对应的值:")
print(t.loc["A":,["W","X","Z"]])
print("*"*100)
print("取A行到C行和W、Y列对应的值:")
print(t.loc["A":"C",["W","Y"]])
print("*"*100)
print("取A行和W、X、Z列对应的值:")
print(t.loc["A",["W","X","Z"]])
print(type(t.loc["A",["W","X","Z"]]))
print("*"*100)
输出:


7.iloc:通过位置获取行数据
代码:
import pandas as pd
import numpy as np
import string
t = pd.DataFrame(np.arange(12).reshape(3,4),
index= list(string.ascii_uppercase[:3]),
columns=list(string.ascii_uppercase[-4:]))
print(t)
print("*"*100)
print("取第1行:")
print(t.iloc[:,1])
print("取第1列:")
print(t.iloc[1])
print("取第1到3行(不包括第1行):")
print(t.iloc[1:3])
print("取第1到3行(不包括第1行)和取第1列到第3列(不包括第1列):")
print(t.iloc[1:3,1:3])
t.loc["A","Y"] = 100
print("更改A行Y列对应的值:",t)
输出:


8.布尔索引
代码:
import pandas as pd
t1 = pd.read_csv("data1.csv")
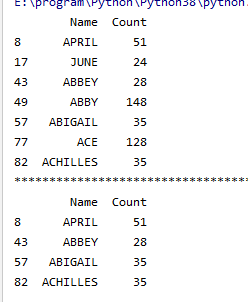
#找到Count值大于20的所有数据
t2 = t1[t1["Count"]>20]
print(t2)
print("*"*100)
# 找到Name字符串大于4的且Count的值大于20的所有值
t3 = t1[(t1["Name"].str.len()>4) & (t1["Count"]>20)]
print(t3)
输出:
9.缺失数据的处理
代码:
import pandas as pd
import numpy as np
df = pd.DataFrame({'A': [np.nan, 2, 3, 5, 6, 7, 8, 4],
'B': [1, 2, 3, np.nan, 6, 7, 8, 4],
'C': [1, 2, 3, 5, 6, 7, 8, 0],
'D': [1, 2, 3, 5, 6, np.nan, 8, 4]})
print(df)
print("*"*100)
print(pd.isnull(df))
print("*"*100)
print(pd.notnull(df))
print("*"*100)
df1 = df.dropna(axis=0, how='any',inplace=False)# 0表示横
print(df1)
print("*"*100)
df2 = df.dropna(axis=1, how='any',inplace=False)# 1表示竖
print(df2)
print("*"*100)
#填充数据
df3 = df.fillna(df.mean())
print(df3)
print("*"*100)
df4 = df.fillna(df.median())
print(df4)
print("*"*100)
df5 = df.fillna(0)
print(df5)
print("*"*100)
输出:




结束!
