Normalization和Standardization的区别
写在前面:Normalization和Standardization在很多时候,很多文章中并不区分,甚至会使用scaling来代替上述两个词。在这里我们针对两种方法,做一些细微的区分。
Normalization:
将我们的数据值的范围限定在[0,1]之间,也就是我们将常说的归一化。在机器学习的算法中,我们经常会遇到这种情况:
| x1 | x2 |
|---|---|
| 1985 | 1 |
| 1874 | 3 |
| 1600 | 5 |
某一列数据的值域和另外一列数据值域相差过大,如果我们只用此类的原始数据,在一些机器学习的优化算法,例如梯度下降中,梯度下降的方向如下所示:
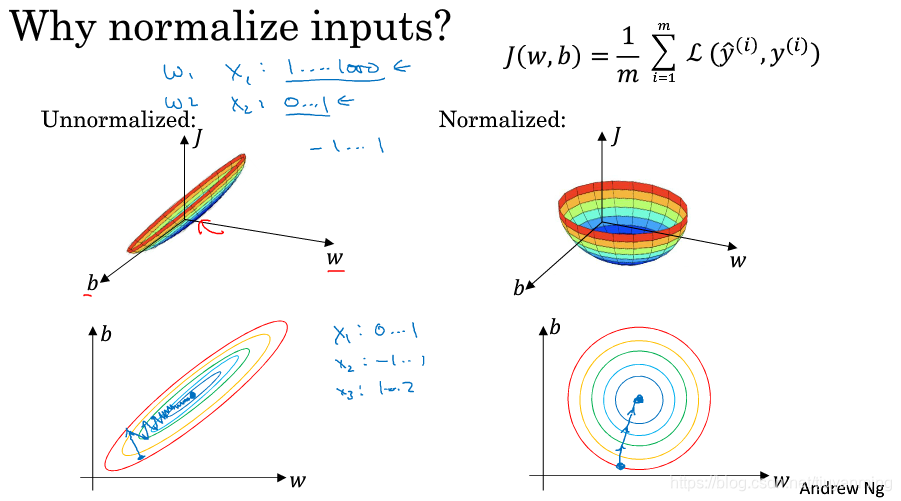
没有归一化的数据其代价函数看起来像是扁平的碗,同时其梯度下降的方向像是再走“之字形”,迭代很慢。
使用归一化之后的数据,代价函数会看起来很对称,同时训练速度更快,模型精度更高。
常用的归一化方法如下:
-
最大最小值归一化(线性):
-
对数归一化(非线性):
Standardization:
将数据进行正态化,使处理后的数据符合标准正态分布,即均值为0,标准差为1。也就是我们常说的标准化。
其中
是指数据的均值,
是指数据的标准差。上述公式又被称为Zero-Mean Normalization 。
总结:
-
标准化用于调整数据为标准正态分布,归一化用于将数据值域调整为[0,1]。
-
归一化受最大值,最小值影响;标准化受均值,标准差影响。
