1. 题目来源
2. 题目说明
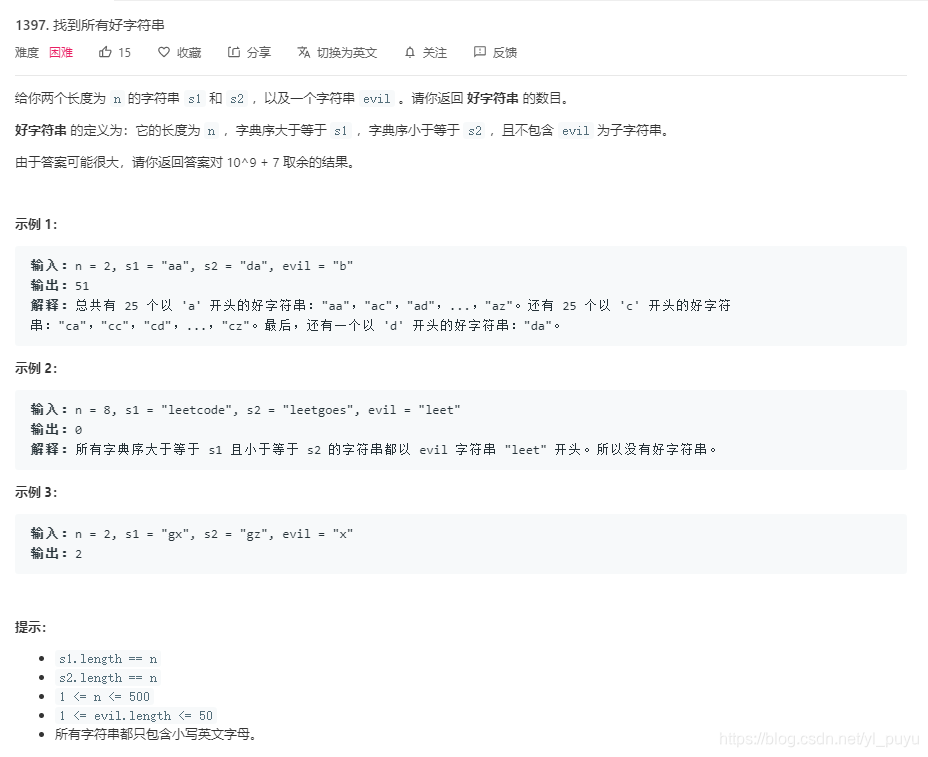
3. 题目解析
方法一:数位dp+kmp+常规解法
8 分的压轴题,真的是相当相当相当少见…而这题也是不负众望,全场就 AK 33 位爷。三题选手从 30 多排到 1000 开外…本周赛真是大佬上分的好机会,也确确实实是一次手速竞赛~
这两个概念我都不算很清楚,尤其前者没专门学习过 dp 的各种分类。但是毕竟有题解、大佬的讲解,加上自己的理解,希望能够分享出来,供学习。
数位 dp 基础题:不要 62。建议看看网上的优质博文了解后做这个模板题。
确实无法用精炼的语言和思想进行总结。就在此就直接将思路及 dp 方程的解释和各个注意点放到了代码里,提供注释版和非注释版。
参见代码如下:
// 执行用时 :68 ms, 在所有 C++ 提交中击败了100.00%的用户
// 内存消耗 :7.7 MB, 在所有 C++ 提交中击败了100.00%的用户
#define LL long long
const int MAXN = 500 + 50;
const int MAXM = 50 + 10;
const LL MOD = 1e9 + 7;
namespace KMP{
vector<int> next;
void build(const string &pattern){
int n = pattern.length();
next.resize(n + 1);
for (int i = 0, j = next[0] = -1; i < n; next[++i] = ++j){
while(~j && pattern[j] != pattern[i]) j = next[j];
}
}
vector<int> match(const string &pattern, const string &text){
vector<int> res;
int n = pattern.length(), m = text.length();
build(pattern);
for (int i = 0, j = 0; i < m; ++i){
while(j > 0 && text[i] != pattern[j]) j = next[j];
if (text[i] == pattern[j]) ++j;
if (j == n) res.push_back(i - n + 1), j = next[j];
}
return res;
}
};
int len, m;
string limStr, evilStr;
LL dp[MAXN][MAXM];
// 理解数位dp就是理解 数位的dfs+记忆化搜索,数位的概念完全就是为了进行dp使其满足dp的性质,之后记忆化搜索
// 匹配evil部分,可以从前往后确认字符串的内容,同时再对evil进行匹配,一旦匹配完成,那么当前字符串不合法
//
// dp[i][j] 表示已经合法确定了[0, i)位,即确认了前i位,且前i位没办法和evil进行匹配
// 但是可能前i位的后缀已经和部分evil进行匹配了向后dfs添加字母时可能会完全与evil进行匹配
// 在确定前i位部分已经匹配了部分evil,下一个字符从evil的第j位进行匹配
// [i, n)位随意填且还能符合题目要求的方案数
//
// 例有dp[i][j] 若第i位填c即i->c,那么就会发生状态转移dp[i+1][k],
// i+1确实很好理解,已经确认i位填的是什么,添加确定字符得到第i+1位所填结果
// j-->k表示为当前所填的c是否能与evil字符串匹配
// 若能匹配,k=j+1,若不能匹配,就类似于kmp算法,模式串在此失配通过不断跳next数组尝试匹配,直到不能匹配为止
// k通过kmp原理计算得出
// 已经确认前i+1位,下一个字符从1位到k位进行匹配
// 即dp[i][j]的方案数就等于加上dp[i+1][k]的方案数,因为dp[i][j]等于枚举第i位填什么,有dp[i][k]种方案
// x即为i,match即为j,flag表示第i位是否等于数位dp中的上边界,若等于上边界的哪一位,
// 那么第i+1位不可随便枚举,考虑i+1位的数值边界问题
LL dfs(int x, int match, bool flag){
// match表示下一位从evil的哪一位开始匹配
// 若match已经大于m了就说明已经匹配出一个evil了,没有合法的方案返回0
if (match >= m) return 0;
// 由于为从前往后确认的,现在确认完毕后还没有匹配到evil,返回1即可
if (x >= len) return 1;
// 记忆化过程
// !flag表示没有贴着上边界进行处理
// 包含着数位dp的技巧,即仅需要记忆化flag等于false的情况,等于true的情况不需要记忆化
// 因为在两次调用dfs的过程中拥有着s1,s2两个不同的上界,而上界不同flag等于true的dp记忆化数值是不同的
// 若记忆化flag的话就需要对每次dfs前清空dp数组
//
// 当前状态计算完毕后就进行返回
if (!flag && dp[x][match] != -1) return dp[x][match];
// lim表示从当前字符到上边界lim字符
char lim = 'z';
// 如果flag已经贴着上边界了,那么lim字符就需要更新为上边界字符,否则超出边界导致情况总数增加
if (flag) lim = limStr[x];
LL ret = 0;
// 已经填好0到i-1,假设当前第i为填char c
// 那么evil字符串就需要与当前char c位进行匹配,如果失配的话就像kmp一样不断跳next即可
// 如果能匹配,就将匹配指针向后加一
for (char c = 'a'; c <= lim; c++){
int nxt = match;
while(nxt > 0 && evilStr[nxt] != c) nxt = KMP::next[nxt];
if (c == evilStr[nxt]) nxt += 1;
// 确认了第x位,下一步确认第x+1位
// 下一位从 nxt位开始匹配
// flag若之前贴着上界且当前枚举的字符也是贴着上界的,那么下一步flag就等于true,
// 否则后面就可以随便枚举了
//
// 将方案总数相加进行取模运算
ret = (ret + dfs(x + 1, nxt, flag && (c == lim)) ) % MOD;
}
// 记忆化
if (!flag) dp[x][match] = ret;
// 返回方案总数
return ret;
}
class Solution {
public:
int findGoodStrings(int n, string s1, string s2, string evil) {
// 特判若[s1,s2]区间无法构成,那么直接返回0即可
if (s1 > s2) return 0;
len = n; m = evil.length();
evilStr = evil;
KMP::build(evil);
// 数位dp常见技巧,进行区间转化
// 问题转化为字典序小于等于s1的不包含evil子字符串个数
// 及字典序小于等于s2的不包含evil子字符串个数
// 那么方法总数就是差值再判断重复情况s1是否包含evil即可
memset(dp, -1, sizeof(dp));
limStr = s2;
LL ans = dfs(0, 0, true) % MOD;
limStr = s1;
// 取模后加MOD即防止出现负数情况
ans = ans - dfs(0, 0, true) % MOD + MOD;
if (s1.find(evil) == s1.npos) ++ans;
return ans % MOD;
}
};
参见代码如下:
#define LL long long
const int MAXN = 500 + 50;
const int MAXM = 50 + 10;
const LL MOD = 1e9 + 7;
namespace KMP{
vector<int> next;
void build(const string &pattern){
int n = pattern.length();
next.resize(n + 1);
for (int i = 0, j = next[0] = -1; i < n; next[++i] = ++j){
while(~j && pattern[j] != pattern[i]) j = next[j];
}
}
vector<int> match(const string &pattern, const string &text){
vector<int> res;
int n = pattern.length(), m = text.length();
build(pattern);
for (int i = 0, j = 0; i < m; ++i){
while(j > 0 && text[i] != pattern[j]) j = next[j];
if (text[i] == pattern[j]) ++j;
if (j == n) res.push_back(i - n + 1), j = next[j];
}
return res;
}
};
int len, m;
string limStr, evilStr;
LL dp[MAXN][MAXM];
LL dfs(int x, int match, bool flag){
if (match >= m) return 0;
if (x >= len) return 1;
if (!flag && dp[x][match] != -1) return dp[x][match];
char lim = 'z';
if (flag) lim = limStr[x];
LL ret = 0;
for (char c = 'a'; c <= lim; c++){
int nxt = match;
while(nxt > 0 && evilStr[nxt] != c) nxt = KMP::next[nxt];
if (c == evilStr[nxt]) nxt += 1;
ret = (ret + dfs(x + 1, nxt, flag && (c == lim)) ) % MOD;
}
if (!flag) dp[x][match] = ret;
return ret;
}
class Solution {
public:
int findGoodStrings(int n, string s1, string s2, string evil) {
if (s1 > s2) return 0;
len = n; m = evil.length();
evilStr = evil;
KMP::build(evil);
memset(dp, -1, sizeof(dp));
limStr = s2;
LL ans = dfs(0, 0, true) % MOD;
limStr = s1;
ans = ans - dfs(0, 0, true) % MOD + MOD;
if (s1.find(evil) == s1.npos) ++ans;
return ans % MOD;
}
};
4. 本周赛总结
前三道手速题,后一道绝杀…确实是大佬是上分大好机会。不过恰好我前一天晚上喜获一名小外甥,开心之余就没参加本次周赛了,虚拟竞赛参加了下也是只能弄出前 3 道,第四题早有耳闻放弃挣扎了。dp 的总结分类刷题是该提上日程了~
扫描二维码关注公众号,回复:
10435423 查看本文章

