鄙人学习笔记,这个笔记以例子为主。
开发工具:Spyder
文章目录
使用python做数据分析的常用库
- numpy 基础数值算法
- scipy 科学计算
- matplotlib 数据可视化
- pandas 序列高级函数
numpy概述
①Numerical Python,数值的Python,补充了Python语言所欠缺的数值计算能力。
②Numpy是其它数据分析及机器学习库的底层库。
③Numpy完全标准C语言实现,运行效率充分优化。
④Numpy开源免费。
ndarray数组
ndarray数组是用np.ndarray类的对象表示的n维数组。
- 例子

内存中的ndarray对象
- 元数据(metadata)
元数据存储对目标数组的描述信息,如:dim count(维数)、shape(维度)、dtype(数据类型)、size(元素个数)、data(作为一个指针,指向具体数据)等。
- 实际数据
实际数据是完整的数组数据。
将实际数据与元数据分开存放,一方面提高了内存空间的使用效率,另一方面减少对实际数据的访问效率,提高性能。
ndarray数组对象的创建
创建方式1
- 语法
np.array(任何可被解释为numpy数组的逻辑结构)
- 例子

创建方式2
- 语法
np.arange(起始值, 终止值, 步长)
- 例子

创建方式3
- 语法
np.zeros(数组元素个数, dtype = “类型”)
- 例子

创建方式4
- 语法
np.ones(数组元素个数, dtype = “类型”)
- 例子

举个例子
代码:
import numpy as np
a1 = np.array([[1, 2, 3], [4, 5, 6]])
print(a1, a1.shape)
a2 = np.arange(0, 5)
print(a2)
a3 = np.zeros(5, dtype = 'int32')
print(a3)
a4 = np.ones(5, dtype = 'float32')
print(a4)
a5 = np.zeros_like(a1)
print(a5)
备注:np.zeros_like(a1)为构造一个维度类似于a1的全0数组。
结果:

- ndarray数组对象的特点
①ndarray数组是同质数组,即所有元素的数据类型必须相同。
②ndarray数组的下标从0开始,最后一个元素的下标为数组长度减1。
ndarray对象属性的基本操作
数组的维度(np.ndarray.shape)
- 例子

元素的类型(np.ndarray.dtype)
- 例子

备注:【<U11表示11个Unicode字符】
数组元素的个数(np.ndarray.size)
- 例子

备注:size表示底层元素个数,len表示最外层对象个数。
数组元素索引(下标)
- 例子
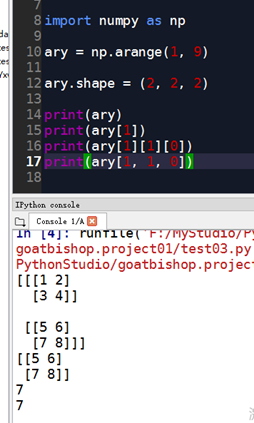
ndarray对象属性操作详解
numpy的内部基本数据类型
| 类型名 | 类型表示符 |
|---|---|
| 布尔型 | bool_ |
| 有符号整数型 | int8(-128~127)/int16/int32/int64 |
| 无符号整数型 | uint8(0~255)/uint16/uint32/uint64 |
| 浮点型 | float16/float32/float64 |
| 复数型 | complex64/complex128 |
| 字串型 | str_,每个字符用32位Unicode编码表示 |
自定义复合数据类型
举个例子1
我们有以下数据:
import numpy as np
data=[
('xb', [90, 80, 85], 15),
('dh', [92, 81, 83], 16),
('xh', [95, 85, 95], 15)
]
直接将data放入np.array()中:

嗯,报错了!说明np.array()不能识别我们的data。
我们可以设置dtype,来识别数据:
import numpy as np
data=[
('xb', [90, 80, 85], 15),
('dh', [92, 81, 83], 16),
('xh', [95, 85, 95], 15)
]
a01= np.array(data, dtype='U2, 3int32, int32')
print(a01)
备注:U代表uniocode字符,2代表两个,若出现第三个字符,则python会无法识别。int32代表整形,3int32表示包含3个整形的列表。
输出结果:
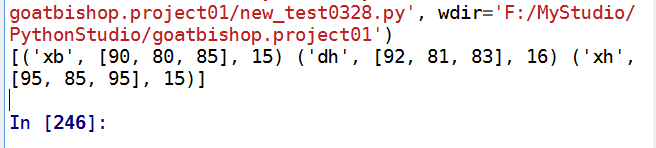
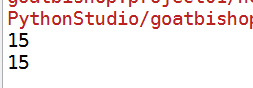
我们试着用2种方法读取数据:
print(a01[2][2])
print(a01[2]['f2'])
#f2表示下标为2的字段
结果:
若data中字段比较多,我们可以使用另一种设置dtype的方式:
import numpy as np
data=[
('xb', [90, 80, 85], 15),
('dh', [92, 81, 83], 16),
('xh', [95, 85, 95], 15)
]
a02= np.array(data, dtype=[('name', 'str', 2),
('scores', 'int32', 3),
('age', 'int32', 1)])
读取数据:
print(a02)
print(a02[2]['age'])
结果:

我们可以使用第三种设置dtype的方式:
import numpy as np
data=[
('xb', [90, 80, 85], 15),
('dh', [92, 81, 83], 16),
('xh', [95, 85, 95], 15)
]
ary = np.array(data, dtype = {
'names':['name', 'scores', 'age'],
'formats':['U2', '3int32', 'int32']})
再读取一下数据:
print(ary)
print(ary[2]['name'])
结果:

举个例子2(日期类型的数组)
数据:
import numpy as np
data = ['2020', '2015-07-01',
'2012-01-01', '1997-09-28']
直接将data放入np.array(),并将数据和数据类型打印出来:

转换数据类型, 并将数据和数据类型打印出来:

除此之外,原始数据还可以写出时、分、秒,但是由于设定转换的数据类型是精确到Day所以,输出的结果,不会显示出时、分、秒:
import numpy as np
data = ['2020', '2015-07-01',
'2012-01-01', '1997-09-28 11:10:01']
d01 = np.array(data)
print(d01, d01.dtype)
#转换成精确到天的datetime64数据类型
d02 = d01.astype('M8[D]')
print(d02, d02.dtype)
结果:

备注:若日期写成除了2020-01-01之外的格式(如:2020/01/01)则python无法转成时间格式。
时间之间做减法:
import numpy as np
data = ['2020', '2020-03-28',
'2012-01-01', '1997-09-28 11:10:01']
d01 = np.array(data)
d02 = d01.astype('M8[D]')
print(d02[1] - d02[0])
结果:

类型字符码
| 内部基本数据类型 | 字符码(简写) |
|---|---|
| np.bool_ | ? |
| np.int8/16/32/64 | i1/i2/i4/i8 |
| np.uint8/16/32/64 | u1/u2/u4/u8 |
| np.float16/32/64 | f2/f4/f8 |
| np.complex64/128 | c8/c16 |
| np.str_ | U<字符数> |
| np.datetime64 | M8[Y] M8[M] M8[D] M8[h] M8[m] M8[s] |
类型字符码格式
- 格式
<字节序前缀><维度><类型><字节数或字符数>
- 例子
| 类型字符码 | 释义 |
|---|---|
| 3i4 | 大端字节序,3个元素的一维数组,每个元素都是整型,每个整型元素占4个字节。 |
| <(2,3)u8 | 小端字节序,6个元素2行3列的二维数组,每个元素都是无符号整型,每个无符号整型元素占8个字节。 |
| U7 | 包含7个字符的Unicode字符串,每个字符占4个字节,采用默认字节序。 |
- 字节序前缀
| 字节序前缀 | 含义 |
|---|---|
< |
小端 |
> |
大端 |
[=] |
硬件字节序 |
