鄙人学习笔记,这个笔记以例子为主。
开发工具:Spyder
加载文件
numpy提供了函数,用于加载逻辑上可被解释为二维数组的文本文件,文件格式如下所示:
数据项1 <分隔符> 数据项2 <分隔符> ... <分隔符> 数据项n
例如:
AA,AA,AA,AA,AA
BB,BB,BB,BB,BB
...
或:
AA:AA:AA:AA:AA
BB:BB:BB:BB:BB
...
调用numpy.loadtxt()函数可以直接读取该文件并且获取ndarray数组对象:
import numpy as np
# 直接读取该文件并且获取ndarray数组对象
# 返回值:
# unpack=False:返回一个二维数组
# unpack=True: 多个一维数组
np.loadtxt(
'../aapl.csv', # 文件路径
delimiter=',', # 分隔符
usecols=(1, 3), # 读取1、3两列 (下标从0开始)
unpack=True, # 是否按列拆包
skiprows=1, #跳过前1行
comments='$', #如果行的开头为$就会跳过该行
dtype='U10, f8', # 制定返回每一列数组中元素的类型
converters={1:func} # 转换器函数字典
)
举个例子1(读取csv文件)
数据:

由以上csv数据来看,我们有24行数据,且我们应该跳过第一行(行名),进行数据读取。
代码:
import sys
import numpy as np
#sys.path.append("C:\\Users\\goatbishop\\Desktop\\data")
print(sys.path[-1])
data01 = np.loadtxt(
r'C:\Users\goatbishop\Desktop\data\data01.csv',
delimiter = ',',
usecols = tuple(range(3)),
unpack = False,
skiprows=1,
dtype = 'U10, f8, f8')
print(data01.shape)
print(data01)
结果:
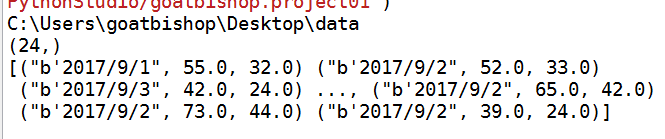
由结果可知,我们有24个观测,每个观测被一个元祖存储在一起,并且这24个元祖被放在一个列表中,组成一个大数据集。
若此时设置unpack = True则python会帮我们把3列数据拆开,则此时我们需要用3个变量去接收:
import sys
import numpy as np
#sys.path.append("C:\\Users\\goatbishop\\Desktop\\data")
print(sys.path[-1])
dates, AQI, PM25 = np.loadtxt(
r'C:\Users\goatbishop\Desktop\data\data01.csv',
delimiter = ',',
usecols = tuple(range(3)),
unpack = True,
skiprows=1,
dtype = 'U10, f8, f8')
print(dates.shape)
print(dates)
结果:

我们要将dates变量转换成时间形式数据,这时我们就要使用converters = {k :func}这个函数字典转换器。
converters = {k :func}的意思为:将第k列的每个观测行的数据,经过func函数进行转化。
在此案例中func函数的设置:
import sys
import numpy as np
import datetime as dt
import matplotlib.pyplot as mp
import matplotlib.dates as md
def time2time(yt):
yt = str(yt, encoding='utf-8')
nt = dt.datetime.strptime(yt, '%Y/%m/%d').date()
t = nt.strftime('%Y-%m-%d')
return t
由以上代码可知,首先对yt按照utf-8编码转换成字符串。再将yt字符串按照[年/月/日]的格式解析为时间形式数据,(strptime函数根据指定的格式把一个时间字符串解析为时间元组)然后再按照[年-月-日]的格式转换成字符串,再返回处理后数据(strftime函数接收时间元组,并返回以可读字符串表示的当地时间)。
python中时间日期格式化符号:
| 符号 | 含义 |
|---|---|
| %y | 两位数的年份表示(00-99) |
| %Y | 四位数的年份表示(000-9999) |
| %m | 月份(01-12) |
| %d | 月内中的一天(0-31) |
| %H | 24小时制小时数(0-23) |
| %I | 12小时制小时数(01-12) |
| %M | 分钟数(00-59) |
| %S | 秒(00-59) |
| %a | 本地简化星期名称 |
| %A | 本地完整星期名称 |
| %b | 本地简化的月份名称 |
| %B | 本地完整的月份名称 |
| %j | 年内的一天(001-366) |
我们再设置converters参数,并打印出来(接上面的代码):
dates, AQI, PM25 = np.loadtxt(
r'C:\Users\goatbishop\Desktop\data\data01.csv',
delimiter = ',',
usecols = tuple(range(3)),
unpack = True,
skiprows=1,
dtype = 'M8[D], f8, f8',
converters = {0:time2time})
print(dates.shape)
print(dates, dates.dtype)
结果:
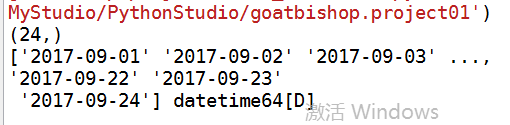
我们再绘制时间序列图(将dates修改为matplotlib.dates内的时间数据类型):
代码(接上面的代码):
dates = dates.astype(md.datetime.datetime)
mp.figure("Figure AQI", facecolor='lightgray' )
mp.title("AQI Sequence Diagrams", fontsize = 16)
mp.xlabel("Date", fontsize = 14)
mp.ylabel("AQI", fontsize = 14)
mp.grid(linestyle = ":")
mp.plot(dates, AQI,
color = 'dodgerblue', linestyle = '--',
label = "AQI")
mp.plot(dates, PM25,
color = 'r', linestyle = ':',
label = "PM25")
mp.legend(loc = 0)
mp.show()
结果:

有上图可以看出,x轴显示出来的刻度,实在不怎么招人喜欢。我们使用x轴刻度定位器,修改一下x轴的时间刻度(接上面的代码):
ax = mp.gca()
ax.xaxis.set_major_locator(
md.WeekdayLocator(byweekday=md.SU))
ax.xaxis.set_major_formatter(
md.DateFormatter('%d %b %Y'))
ax.xaxis.set_minor_locator(md.DayLocator())
mp.show()
图像:

我们也可以调用autofmt_xdate()函数,设置倾斜的标识值,防止显示的刻度标识值过于紧密:
mp.gcf().autofmt_xdate()
图像:

