文章目录
一、简介线段树
psps : _此处以询问区间和为例。实际上线段树可以处理很多符合结合律的操作。(比如说加法,a[1]+a[2]+a[3]+a[4]=(a[1]+a[2])+(a[3]+a[4]))
线段树之所以称为“树”,是因为其具有树的结构特性。线段树由于本身是专门用来处理区间问题的(包括 RMQ 、 RSQ 问题等。
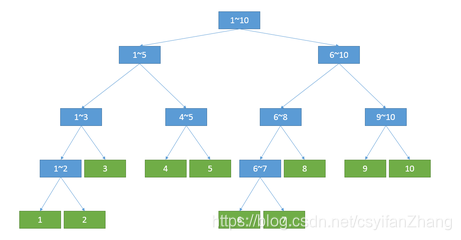
对于每一个子节点而言,都表示整个序列中的一段子区间;对于每个叶子节点而言,都表示序列中的单个元素信息;子节点不断向自己的父亲节点传递信息,而父节点存储的信息则是他的每一个子节点信息的整合。
有没有觉得很熟悉?对,线段树就是分块思想的树化,或者说是对于信息处理的二进制化——用于达到 级别的处理速度, 以 2 为底。(其实以几为底都只不过是个常数,可忽略)。而分块的思想,则是可以用一句话总结为:通过将整个序列分为有穷个小块,对于要查询的一段区间,总是可以整合成 个所分块与 个单个元素的信息的并 。但普通的分块不能高效率地解决很多问题,所以作为 级别的数据结构,线段树应运而生。
其实,虽然线段树的时间效率要高于分块但是实际上分块的总合并次数不会超过 但是线段树在最坏情况下的合并次数显然是要大于这个时间效率的 qwq 。
但是毕竟也只是一个很大的常数而已
However ,虽说如此,分块的应用范围还是要广于线段树的,因为虽然线段树好像很快,但是它只能维护带有结合律的信息,比如区间 、 、 之类的,但是不带有结合律的信息就不能维护(且看下文分解);而分块则灵活得多,可以维护很多别的东西,因为实际上分块的本质就是优雅的暴力qwq。
其实越暴力的算法可以支持的操作就越多、功能性就越强呐!你看 的暴力几乎什么都可以维护
二、逐步分析线段树的构造实现
1、建树与维护
由于二叉树的自身特性,对于每个父亲节点的编号 ,他的两个儿子的编号分别是 和 ,所以我们考虑写两个 的取儿子函数:
int t[MAX*4];
int cnt = 0;
inline int lc(int p) { return p << 1; }
inline int rc(int p) { return p << 1 | 1; }
- 此处的 可以有效防止无需入栈的信息入栈,节省时间和空间。
- 二进制位左移一位代表着数值
,而如果左移完之后再或上
,由于左移完之后最后一位二进制位上一定会是
,所以
等价于
。
用二进制运算不是为了装X,相信我,会快的!
那么根据线段树的服务对象,可以得到线段树的维护:
//向上不断维护区间的操作
void pushUpSum(int p) {
t[p] = t[lc(p)] + t[rc(p)];
//t[p] = min(t[lc(p)], t[rc(p)]); 维护区间最小值操作
//t[p] = max(t[lc(p)], t[rc(p)]); 维护区间最大值操作
}
此处一定要注意, 操作的目的是为了维护父子节点之间的逻辑关系。当我们递归建树时,对于每一个节点我们都需要遍历一遍,并且电脑中的递归实际意义是先向底层递归,然后从底层向上回溯,所以开始递归之后必然是先去整合子节点的信息,再向它们的祖先回溯整合之后的信息。(这其实是正确性的证明啦)
呐,我们在这儿就能看出来,实际上 是在合并两个子节点的信息,所以需要信息满足结合律!
那么对于建树,由于二叉树自身的父子节点之间的可传递关系,所以可以考虑递归建树( 之前好像不小心剧透了 ),并且在建树的同时,我们应该维护父子节点的关系:
void build(ll p, ll l, ll r) {
//如果l==r必然是叶子节点
if (l == r) { t[p] = a[l]; return; }
ll mid = (l + r) >> 1; //将区间一分为2
build(lc(p), l, mid);
build(rc(p), mid + 1, r);
//此处由于我们采用的是二叉树,所以对于整个结构来说,可以用二分来降低复杂度,否则树形结构则没有什么明显的优化
pushUpSum(p);
//此处由于我们是要通过子节点来维护父亲节点,所以pushup的位置应当是在回溯时。
}
2、接下来谈区间修改
为什么不讨论单点修改呢 ?因为其实很显然,单点修改就是区间修改的一个子问题而已,即区间长度为 1时进行的区间修改操作罢了。
那么对于区间操作,我们考虑引入一个名叫“ lazy tag ”(懒标记)的东西——之所以称其“ lazy”,是因为原本区间修改需要通过先改变叶子节点的值,然后不断地向上递归修改祖先节点直至到达根节点,时间复杂度最高可以到达 的级别。但当我们引入了懒标记之后,区间更新的期望复杂度就降到了 的级别且甚至会更低.
(1)首先先来从分块思想上解释如何区间修改:
分块的思想是通过将整个序列分为有穷个小块,对于要查询的一段区间,总是可以整合成 ,个所分块与 个单个元素的信息的并 (小小修改了一下的上面的前言 )
那么我们可以反过来思考这个问题:对于一个要修改的、长度为 的区间来说,总是可以看做由一个长度为 和剩下的元素(或者小区间组成)。那么我们就可以先将其拆分成线段树上节点所示的区间,之后分开处理:
如果单个元素被包含就只改变自己,如果整个区间被包含就修改整个区间
其实好像这个在分块里不是特别简单地实现,但是在线段树里,无论是元素还是区间都是线段树上的一个节点,所以我们不需要区分区间还是元素,加个判断就好。
(2)懒标记的正确打开方式
首先,懒标记的作用是记录每次、每个节点要更新的值,也就是 ,但线段树的优点不在于全记录(全记录依然很慢qwq),而在于传递式记录:
整个区间都被操作,记录在公共祖先节点上;只修改了一部分,那么就记录在这部分的公共祖先上;如果四环以内只修改了自己的话,那就只改变自己。
After that ,如果我们采用上述的优化方式的话,我们就需要在每次区间的查询修改时 pushdown 一次,以免重复或者冲突或者爆炸。
那么对于 而言,其实就是纯粹的 的逆向思维(但不是逆向操作): 因为修改信息存在父节点上,所以要由父节点向下传导 。那么问题来了:怎么传导 pushdown 呢?这里很有意思,开始回溯时执行 pushup ,因为是向上传导信息;那我们如果要让它向下更新,就调整顺序,在向下递归的时候 pushdown
inline void f(ll p, ll l, ll r, ll k) {
tag[p] = tag[p] + k;
t[p] = t[p] + k * (r - l + 1);
//由于是这个区间统一改变,所以ans数组要加元素个数次
}
inline void push_down(ll p, ll l, ll r) {
ll mid = (l + r) >> 1;
f(lc(p), l, mid, tag[p]);
f(rc(p), mid + 1, r, tag[p]);
tag[p] = 0;
//每次更新两个儿子节点。以此不断向下传递,push完之后tag就可以重置了
}
inline void update(ll nl, ll nr, ll l, ll r, ll p, ll k) {
//nl-nr:需要修改的区间
//l,r,p,k:当前节点所存储的区间以及节点的编号 以及tag的值
if (nl <= l && nr >= r) {//需要修改区间包含了当前区间
t[p] += k * (r - l + 1);//只在当前中间节点进行修改,无需修改叶子节点,注意+1
tag[p] += k;//修改当前区间的同时需要修改tag
return;
}
push_down(p, l, r); //因为要下行,这里有tag的话必须往下面传递
//回溯之前(也可以说是下一次递归之前,因为没有递归就没有回溯)
//由于是在回溯之前不断向下传递,所以自然每个节点都可以更新到
ll mid = (l + r) >> 1;
if (nl <= mid) update(nl, nr, l, mid, lc(p), k);
if (nr >= mid + 1)update(nl, nr, mid + 1, r, rc(p), k);
pushUpSum(p);
}
对于复杂度而言,由于完全二叉树的深度不超过 ,那么单点修改显然是 的,区间修改的话,由于我们的这个区间至多分 个子区间,对于每个子区间的查询是 的,所以复杂度自然是 不过带一点常数。
3、那么对于区间查询
区间查询就比较简单了,区间查询的链接。不过要谨记,我们用了lazy tag,每次查询操作都必须向下push down。以免冲突。
ll query(ll nl, ll nr, ll l, ll r, ll p) {
ll res = 0;
if (nl <= l && r <= nr)return t[p];//区间完全包含在被查询区间之内
ll mid = (l + r) >> 1;
push_down(p, l, r);//again,必须先往下push down
if (nl <= mid) res += query(nl, nr, l, mid, lc(p));
if (nr > mid)res += query(nl, nr, mid + 1, r, rc(p));
return res;
}
对一道模板题的完整代码:

#include<iostream>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;
#define MAX 1000005
#define ll long long
ll t[MAX * 4], a[MAX], tag[MAX * 4];
ll cnt = 0;
inline ll lc(ll p) { return p << 1; }
inline ll rc(ll p) { return p << 1 | 1; }
//向上不断维护区间的操作
void pushUpSum(ll p) {
t[p] = t[lc(p)] + t[rc(p)];
//t[p] = min(t[lc(p)], t[rc(p)]); 维护区间最小值操作
//t[p] = max(t[lc(p)], t[rc(p)]); 维护区间最大值操作
}
void build(ll p, ll l, ll r) {
//如果l==r必然是叶子节点
tag[p] = 0;
if (l == r) { t[p] = a[l]; return; }
ll mid = (l + r) >> 1; //将区间一分为2
build(lc(p), l, mid);
build(rc(p), mid + 1, r);
//此处由于我们采用的是二叉树,所以对于整个结构来说,可以用二分来降低复杂度,否则树形结构则没有什么明显的优化
pushUpSum(p);
//此处由于我们是要通过子节点来维护父亲节点,所以pushup的位置应当是在回溯时。
}
inline void f(ll p, ll l, ll r, ll k) {
tag[p] = tag[p] + k;
t[p] = t[p] + k * (r - l + 1);
//由于是这个区间统一改变,所以ans数组要加元素个数次
}
inline void push_down(ll p, ll l, ll r) {
ll mid = (l + r) >> 1;
f(lc(p), l, mid, tag[p]);
f(rc(p), mid + 1, r, tag[p]);
tag[p] = 0;
//每次更新两个儿子节点。以此不断向下传递,push完之后tag就可以重置了
}
inline void update(ll nl, ll nr, ll l, ll r, ll p, ll k) {
//nl-nr:需要修改的区间
//l,r,p,k:当前节点所存储的区间以及节点的编号 以及要加的值
if (nl <= l && r <= nr) {//需要修改区间包含了当前区间
t[p] += k * (r - l + 1);//只在当前中间节点进行修改,无需修改叶子节点
tag[p] += k;//修改当前区间的同时需要修改tag
return;
}
push_down(p, l, r); //因为要下行,这里有tag的话必须往下面一层!一层即可
//回溯之前(也可以说是下一次递归之前,因为没有递归就没有回溯)
//由于是在回溯之前不断向下传递,所以自然每个节点都可以更新到
ll mid = (l + r) >> 1;
if (nl <= mid) update(nl, nr, l, mid, lc(p), k);
if (nr >= mid + 1)update(nl, nr, mid + 1, r, rc(p), k);
pushUpSum(p);//下面的区间update之后回来也别忘了
}
ll query(ll nl, ll nr, ll l, ll r, ll p) {
ll res = 0;
if (nl <= l && r <= nr)return t[p];//区间完全包含在被查询区间之内
ll mid = (l + r) >> 1;
push_down(p, l, r);//again,必须先往下push down
if (nl <= mid) res += query(nl, nr, l, mid, lc(p));
if (nr > mid)res += query(nl, nr, mid + 1, r, rc(p));
return res;
}
int main() {
ll n, m, b, c, d;
cin >> n >> m;
for (ll i = 1; i <= n; i++)cin >> a[i];
build(1, 1, n);//从一开始比较和谐
while (m--) {
ll x; cin >> x;
if (x == 1) {
cin >> b >> c >> d;
update(b, c, 1, n, 1, d);
}
else if (x == 2) {
cin >> b >> c;
d = query(b, c, 1, n, 1);
cout << d << endl;
}
}
}
三、区间查询第k大/小元素:主席树
问题:
给定数组
,对每一个查询
,求出
区间中第
大的数字。
思路分析:
最简单的方法无非对所求的区间
,我们对这个来一次排序,然后求第
个,但是这样的话每次操作都是
,而且操作数目
。对于区间查询的问题,想要高效的解决,最好的方法无非线段树,但是对于第k大的值,如何通过线段树来解决呢?
