一、综述
在我们学习的数据结构中,栈作为一个相当常用的数据结构在各方面都有着相当大作用,而栈也因它的特殊的FILO(先进后出)的特性而被我们熟知。那我们今天就来看看栈的具体实现。
关于栈我们可以选择不同的逻辑结构来存放栈的数据——数组和链表。
基于数组的栈的实现,我们在这里就不在赘述,我们在这里主要是面向链表这一逻辑结构完成栈“FILO”功能的实现。
在此之前,我想我们应当明确,要完成栈这一数据结构,我们首先应当了解栈具有什么特性,具有什么样的性质。了解这些之后,我们才能开始真正的完成栈的编码工作:
栈,本质上就是一种运算受限的线性表,因此我们主要考虑的就是他的特性,而对于栈,他的特性就是FILO。
明白了这一点,我们便可以开始编码——
首先我们是基于链表来存放栈的数据,因此我们需要新建结点类,将栈的数据封装进结点类,然后在根据栈的特性进行插入,删除,遍历等操作;
// 结点类
/*
@Author: Mica_Dai
@Date: sep 10th 2017 20:48:13
*/
class Node
{
public:
Node(int x){
data = x;
next = nullptr;
}
~Node(){
delete next;
}
int getData(){
return data;
}
Node* getNext(){
return next;
}
void setNext(Node* node){
next = node;
}
private:
int data;
Node* next;
};然后我们在新建一个stack的类,因为我们已经明确stack的操作主要是有以下的几点:
- 压栈(push)
- 出栈(pop)
- 获取栈顶元素(getTop)
- 遍历(traverse)
因此建立以下的栈stack类:
// stack类
/*
@Author: Mica_Dai
@Date: sep 10th 2017 20:54:23
*/
class stack
{
public:
stack(){
top = nullptr;
}
~stack();
Node* push(int x);
bool pop();
Node* getTop();
void traverse();
private:
Node* top;
};
二、压栈(push)
可能有小伙伴儿要说了,你不是说要关注数据结构的特性吗?怎么不进入主题,反而其他的说那么多?
别急,我这就开始进入正题,对于栈的FILO特性,我们是通过插入操作也即压栈操作实现的。
那么我们的压栈究竟是怎样完成的,才能实现栈的FILO特性呢?
我们先看看压栈的示意图:
压栈也分为两种情况:
+ 其中之一是当栈为空,没有任何结点的时候,我们新建的node直接赋值给top就好;
+ 而对于栈的top部位空的时候,原理图才如下:
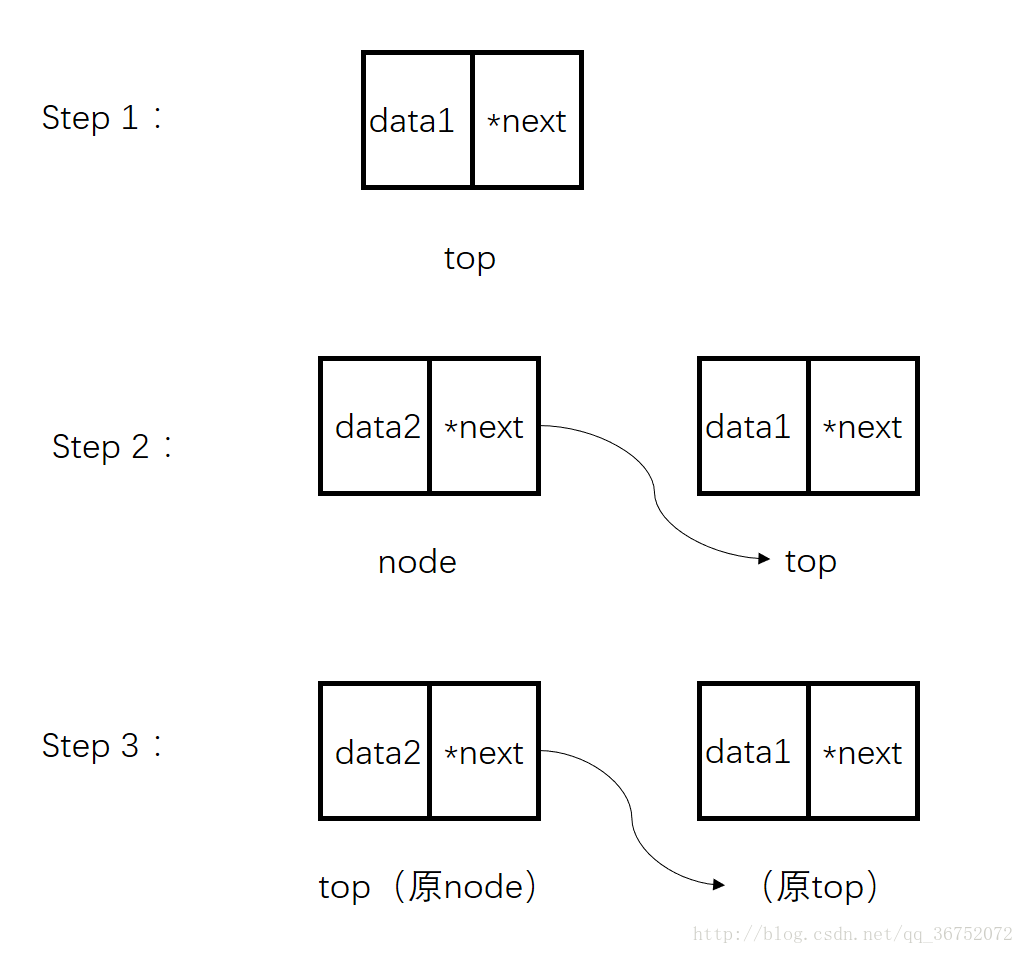
由以上的压栈图,我们不难分析出当我们压栈的时候不就是我们在学链表插入时候的前插法创建链表么!!
而且这样相当明确,当我们想要出栈的时候直接将top所指的结点删除就完成了。同时这就是完成了栈的FILO!
现在我们明白了原理,现在开始完成代码:
// 前插法压栈
Node* stack::push(int x){
Node *node = new Node(x);
cout << (top == nullptr) << endl;
if (top == nullptr){
top = node;
}else{
// Node *temp = top -> getnext;
// top -> next = node;
// node -> getNext() = top;
node -> setNext(top);
top = node;
}
return top;
}
三、出栈(pop)
出栈就是将栈顶元素删除的操作,但是在执行之前需要检查站是否为空;代码如下:
// 出栈函数
bool stack::pop(){
if (top != nullptr)
{
/* code */
top = top -> getNext();
return true;
}else{
return false;
}
}
四、获取栈顶元素(getTop)
这个也是当top不为空的时候,直接将top返回就好;否则返回为空。
Node* stack::getTop(){
if (top != nullptr)
{
/* code */
return top;
}else{
return nullptr;
}
}
五、遍历(traverse)
遍历时就是像前插法创建链表时候的特点,即遍历出来的顺序与插入的顺序完全相反。也正是因为这种情况才使得栈有这种FILO的特性。
也是首先判断top是否为空——
// 遍历函数
void stack::traverse(){
Node *temp = top;
while(temp != nullptr){
cout << temp -> getData() << " ";
temp = temp -> getNext();
// cout << (top == nullptr) << endl;
}
}