Spark MLlib数据挖掘
一、Spark MLlib概述
MLlib是Spark的机器学习(Machine Learning)库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。
MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。
1.Spark MLlib算法库
Spark Mllib能够提供所有类型的机器学习算法:

2.spark的核心概念RDD
RDD(Resilient Distributed Datasets) 即弹性分布式数据集,是一个只读的,可分区的分布式数据集。
注意:虽然RDD的名称是叫数据集,但是它不存储数据。
RDD 默认存储在内存,当内存不足时,溢写到磁盘。
RDD 数据以分区的形式在集群中存储。
RDD 具有血统机制( Lineage ),发生数据丢失时,可快速进行数据恢复。
注意:
RDD是Spark对基础数据的抽象。
RDD的生成:从Hadoop文件系统(或与Hadoop兼容的其它存储系统)输入创建(如HDFS);从父RDD转换得到新的RDD。
RDD的存储:用户可以选择不同的存储级别存储RDD以便重用(11种);RDD默认存储于内存,但当内存不足时,RDD会溢出到磁盘中。
RDD的分区:为减少网络传输代价,和进行分布式计算,需对RDD进行分区。在需要进行分区时会根据每条记录Key进行分区,以此保证两个数据集能高效进行Join操作。
RDD的优点:RDD是只读的,静态的。因此可提供更高的容错能力;可以实现推测式执行。
3.RDD的属性
(1)RDD是在集群节点上的不可变的、只读的、已分区的集合对象
(2)通过并行转换的方式来创建如(map,filter,join 等等)
(3)失败自动重建
(4)可以控制存储级别(内存、磁盘等)来进行重用
(5)必须是可序列化的
4.RDD的特点
(1)具有分区列表(数据块列表)
(2)计算每个分片的函数(根据父RDD计算出此RDD)
(3)具有对父RDD的依赖列表
(4)RDD默认是存储于内存,但当内存不足时,会spill到disk(设置StorageLevel来控制)
(5)每个数据分区的地址(如HDFS),key-value数据类型分区器,分区策略和分区数
5.RDD的血统与依赖
Dependency(依赖)
窄依赖:Narrow Dependencies是指父RDD的每个分区最多被一个子RDD的一个分区所用。
宽依赖:Wide Dependencies是指父RDD的每个分区对应一个子RDD的多个分区。

Lineage(血统):依赖的链条
RDD数据集通过Lineage记住了它是如何从其他RDD中演变过来的。
通常我们会对原始数据进行多个步骤的各种加工,最后生产出新的数据,在这个过程中会产生很多表,这些数据之间的链路关系就可称为大数据血缘。
注意:
大数据血缘测试,就是测试数据流转过程中每个环节的数据质量
6.Dataset
DataSet是一个由特定域的对象组成的强类型集合,可通过功能或关系操作并行转换其中的对象。
DataSet以Catalyst逻辑执行计划表示,并且数据以编码的二进制形式存储,不需要反序列化就可以执行sort、filter、shuffle等操作。
Dataset是“懒惰”的,只在执行action操作时触发计算。当执行action操作时,Spark用查询优化程序来优化逻辑计划,并生成一个高效的并行分布式的物理计划。
Dataset是一个新的数据类型。Dataset与RDD高度类似,性能比较好。
Dataset不需要反序列化就可执行大部分操作。本质上,数据集表示一个逻辑计划,该计划描述了产生数据所需的计算。
Dataset 与 RDD 相似, 然而, 并不是使用 Java 序列化或者 Kryo 编码器来序列化用于处理或者通过网络进行传输的对象。 虽然编码器和标准的序列化都负责将一个对象序列化成字节,编码器是动态生成的代码,并且使用了一种允许 Spark 去执行许多像 filtering, sorting 以及 hashing 这样的操作, 不需要将字节反序列化成对象的格式。
jvm中存储的java对象可以是序列化的,也可以是反序列化的。序列化的对象是将对象格式化成二进制流,可以节省内存。反序列化则与序列化相对,是没有进行二进制格式化,正常存储在jvm中的一般对象。RDD可以将序列化的二进制流存储在jvm中,也可以是反序列化的对象存储在JVM中。至于现实使用中是使用哪种方式,则需要视情况而定。例如如果是需要最终存储到磁盘的,就必须用序列化的对象。如果是中间计算的结果,后期还会继续使用这个结果,一般都是用反序列化的对象。
7.Dataframe
DataFrame是一个以命名列方式组织的分布式数据集,等同于关系型数据库中的一个表。
DataFrame与生俱来就支持读取最流行的格式,包括JSON文件、Parquet文件和Hive表格。DataFrame还支持从多种类型的文件系统中读取,比如本地文件系统、分布式文件系统(HDFS)以及云存储(Amazon S3)。同时,配合JDBC,它还可以读取外部关系型数据库系统。
DataFrame提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。这里主要对比Dataset和DataFrame,因为Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同DataFrame也可以叫Dataset[Row],每一行的类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用getAS方法或者共性中的模式匹配拿出特定字段。而Dataset中,每一行是什么类型是不一定的,在自定义了case class之后可以很自由的获得每一行的信息,结合上图总结出,DataFrame列信息明确,行信息不明确。
由于DataFrame带有schema信息,因此,查询优化器可以进行有针对性的优化,以提高查询效率。
DataFrame在序列化与反序列化时,只需对数据进行序列化,不需要对数据结构进行序列化。

8.RDD、DataFrame与Dataset 的对比
(1)RDD:
优点:类型安全,面向对象。
缺点:序列化和反序列化的性能开销大;GC的性能开销,频繁的创建和销毁对象, 势必会增加GC。
(2)DataFrame:
优点:自带scheme信息,降低序列化反序列化开销。
缺点:不是面向对象的;编译期不安全。
(3)Dataset的特点:
快:大多数场景下,性能优于RDD;Encoders优于Kryo或者Java序列化;避免不必要的格式转化。主要是降低了序列化和反序列化开销,及大量的GC开销。
类型安全:类似于RDD,函数尽可能编译时安全。
和DataFrame,RDD互相转化。
注意:
Dataset具有RDD和DataFrame的优点,又避免它们的缺点。
9.RDD的算子
Transformation
Transformation是通过转换从一个或多个RDD生成新的RDD,该操作是lazy的,当调用action算子,才发起job。
典型算子:map、flatMap、filter、reduceByKey等。
Action
当代码调用该类型算子时,立即启动job。
Action操作是从RDD生成最后的计算结果
典型算子:take、count、saveAsTextFile等。
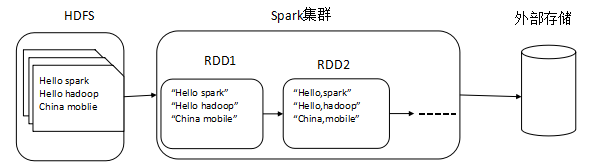
二、RDD的基本操作
1.外部数据源
val distFile1 = sc.textFile("data.txt") //HDFS目录下文件
val distFile2 =sc.textFile("hdfs://192.168.1.100:9000/input/data.txt") //HDFS文件
val distFile3 =sc.textFile(“file:///input/data.txt") //linux本地指定目录下文件
val distFile4 =sc.textFile("/input/data.txt") //HDFS指定目录下文件
注意:textFile可以读取多个文件,或者1个文件夹,也支持压缩文件、包含通配符的路径。
textFile("/input/001.txt, /input/002.txt ") //读取多个文件
textFile("/input") //读取目录
textFile("/input /*.txt") //含通配符的路径
textFile("/input /*.gz") //读取压缩文件
2.map算子(Transformation )
map是对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD;RDD之间的元素是一对一关系;
val rdd1 = sc.parallelize(1 to 9, 3)
val rdd2 = rdd1.map(x => x*2)
rdd2.collect
3.filter(Transformation )
Filter是对RDD元素进行过滤;是经过func函数后返回值为true的原元素组成,返回一个新的数据集;
val rdd3 = rdd2. filter (x => x> 10)
rdd3.collect
res4: Array[Int] = Array(12, 14, 16, 18)
4.flatMap (Transformation )
flatMap类似于map,但是每一个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素),RDD之间的元素是一对多关系;
val rdd4 = rdd3. flatMap (x => x to 20).collect
res5: Array[Int] = Array(12, 13, 14, 15, 16, 17, 18, 19, 20, 14, 15, 16, 17, 18, 19, 20, 16, 17, 18, 19, 20, 18, 19, 20)
5.union(Transformation )
union(otherDataset)是数据合并,由原数据集和otherDataset联合而成,返回一个新的数据集
val rdd8 = rdd1.union(rdd3)
rdd8.collect
res14: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 14, 16, 18)
6.intersection(Transformation )
intersection(otherDataset)是数据交集,包含两个数据集的交集数据,返回一个新的数据集;
val rdd9 = rdd8.intersection(rdd1)
rdd9.collect
res16: Array[Int] = Array(6, 1, 7, 8, 2, 3, 9, 4, 5)
7.distinct (Transformation )
distinct([numTasks]))是数据去重,是对两个数据集去除重复数据,numTasks参数是设置任务并行数量,返回一个数据集;
val rdd10 = rdd8.union(rdd9).distinct
rdd10.collect
res19: Array[Int] = Array(12, 1, 14, 2, 3, 4, 16, 5, 6, 18, 7, 8, 9)
8.groupByKey (Transformation )
groupByKey([numTasks])是数据分组操作,在一个由(K,V)对组成的数据集上调用,返回一个(K,Seq[V])对的数据集。
val rdd0 = sc.parallelize(Array((1,1), (1,2) , (1,3) , (2,1) , (2,2) , (2,3)), 3)
val rdd11 = rdd0.groupByKey()
rdd11.collect
res33: Array[(Int, Iterable[Int])] = Array((1,ArrayBuffer(1, 2, 3)), (2,ArrayBuffer(1, 2, 3)))
9.reduceByKey(Transformation )
reduceByKey(func, [numTasks])是数据分组聚合操作,在一个(K,V)对的数据集上使用,返回一个(K,V)对的数据集,key相同的值,都被使用指定的reduce函数聚合到一起。
val rdd12 = rdd0.reduceByKey((x,y) => x + y)
rdd12.collect
res34: Array[(Int, Int)] = Array((1,6), (2,6))
10.combineByKey(Transformation )
combineByKey是对RDD中的数据集按照Key进行聚合操作。聚合操作的逻辑是通过自定义函数提供给combineByKey。
combineByKey[C](createCombiner: (V) ⇒ C, mergeValue: (C, V) ⇒ C, mergeCombiners: (C, C) ⇒ C, numPartitions: Int):RDD[(K, C)]把(K,V) 类型的RDD转换为(K,C)类型的RDD,C和V可以不一样。
val data = Array((1, 1.0), (1, 2.0), (1, 3.0), (2, 4.0), (2, 5.0), (2, 6.0))
val rdd = sc.parallelize(data, 2)
val combine1 = rdd.combineByKey(createCombiner = (v:Double) => (v:Double, 1),
mergeValue = (c:(Double, Int), v:Double) => (c._1 + v, c._2 + 1),
mergeCombiners = (c1:(Double, Int), c2:(Double, Int)) => (c1._1 + c2._1, c1._2 + c2._2),
numPartitions = 2 )
combine1.collect
res0: Array[(Int, (Double, Int))] = Array((2,(15.0,3)), (1,(6.0,3)))
11.sortByKey (Transformation )
sortByKey([ascending],[numTasks])是排序操作,对(K,V)类型的数据按照K进行排序,其中K需要实现Ordered方法。
val rdd14 = rdd0.sortByKey()
rdd14.collect
res36: Array[(Int, Int)] = Array((1,1), (1,2), (1,3), (2,1), (2,2), (2,3))
12.reduce(action)
reduce(func)是对数据集的所有元素执行聚集(func)函数,该函数必须是可交换的。
val rdd1 = sc.parallelize(1 to 9, 3)
val rdd2 = rdd1.reduce(_ + _)
rdd2: Int = 45
13.collect (action)
collect是将数据集中的所有元素以一个array的形式返回。
rdd1.collect()
res8: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
14.count(action)
返回数据集中元素的个数
rdd1.count()
res9: Long = 9
15.saveAsTextFile (action)
把数据集中的元素写到一个文本文件,Spark会对每个元素调用toString方法来把每个元素存成文本文件的一行。
三、Spark MLlib矩阵向量
Breeze :是机器学习和数值技术库 ,它是sparkMlib的核心,包括线性代数、数值技术和优化,是一种通用、功能强大、有效的机器学习方法。
Spark MLlib底层的向量、矩阵运算使用了Breeze库,Breeze库提供了Vector/Matrix的实现以及相应计算的接口(Linalg),而MLlib同时也提供了Vector和Linalg等的实现。
在项目中使用Breeze 库时,需要导入相关包:
import breeze.linalg._
import breeze.numerics._
Breeze功能函数:
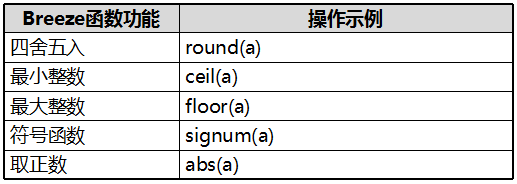
1.矩阵构造函数

2.获取矩阵子集函数

3.矩阵元素访问及操作函数

4.矩阵数值计算函数

5.矩阵求和函数

6.矩阵布尔运算函数
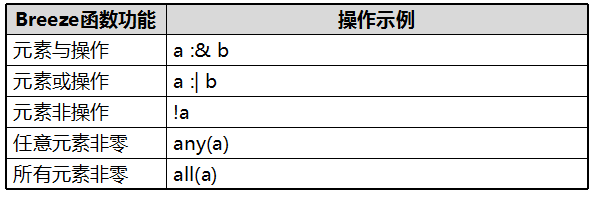
7.矩阵线性代数计算函数

8.矩阵取整函数