1.1 项目背景和意义
随着互联网和多媒体技术的发展,每天都有成千上万的视频被制作和发布,因为很容易抄袭视频并分发给很多人看到,所以非法抄袭和保持知识产权已经成为越来越严重的社会问题。因此,内容管理和版权保护需要高效的抄袭检测技术。
1.2 项目框架简介
国内外目前有两种办法用于视频抄袭检测:数字水印和基于内容的视频抄袭检测( )。
数字水印
更多利用在发布视频之前,被检测对象需要加过数字水印
该方向并未深究。
基于内容的视频抄袭检测
主要结构如下:
关键帧提取
图像特征提取
建立索引
相似度比较,并进行查询。

具体论文,可能会在上述结构进行进一步的改进。
国内外研究现状(目前收集到)
1、Naphade等人提出了一种快速地利用DCT直方和多项式逼近的方法进行匹配。
2、Blat等人提出来对于静态图像搜索的定序检测。
3、Mohan等人提出了对于视频序列的定序检测。
4、Kim和Vasudev提出了定序和时间签名检测,比如原始的定序检测有更好的效果。
5、Chiu等人提出一种概率框架,可以使用关键帧和候选段处理视频中的时空变化。
6、Hye-Jeong Cho等人提出了基于定序测度和斯皮尔曼等级相关方法以及
检验分布检验是否抄袭。
7、Zheng Cao等人提出了基于图片签名的视频检索方法。
8、Feifei Lee等人提出了基于OH和HOG的视频检索方法。
关键帧提取方法:
1、利用
计算两帧的相关系数,基于分块的平均亮度的定序测度检测。
先基于分块,进行定序测度排序,得到 。
越接近
,表示两帧相关性越强。
2、离散余弦变化
未学。
3、帧间差分
对应像素点强度绝对值。
选择差分强度最高的。
使用差分强度的顺序
我们对所有帧按照平均帧间差分强度进行排序,选择平均帧间差分强度最高的若干张图片作为视频的关键帧。
使用差分强度阈值
我们选择平均帧间差分强度高于预设阈值的帧作为视频的关键帧。
使用局部最大值
我们选择具有平均帧间差分强度局部最大值的帧作为视频的关键帧。
这种方法的提取结果在丰富度上表现更好一些,提取结果均匀分散在视频中。
需要注意的是,使用这种方法时,对平均帧间差分强度时间序列进行平滑是很有效的技巧。它可以有效的移除噪声来避免将相似场景下的若干帧均同时提取为关键帧。
PS:轮廓较粗,一般利用三帧差法。
图片特征提取方法:
1、顺序测度(ordinal measure)
对于一张图像,分块例如
,计算出每一块平均像素强度,并排序,得到一个排名矩阵。
可结合康拓展开利用到直方图,计算出视频特征。
结合图像签名,计算出视频签名
2、
3、
4、
5、
直方图
利用
算子等计算卷积,进而得到每个的梯度和幅值。
或者暴力比较相邻:
梯度类似
将
度方向切分成多个
,并按梯度方向分进去。
分块计算直方图,按顺序组成一维向量。
视频特征提取方法:
1、高斯混合、
(视频签名)[效率低下]
2、 颜色空间下的图片签名 视频签名
类似
根据人眼对颜色的敏感程度。
多个帧进行有序测度。
得到视频签名:
3、
有序测度+康扩展开
4、
已讲,将多个关键帧相加。
5、
结合 和 ,分别计算相似度:
, 表示第几个
加权平均得到 。
索引制造:
1、聚类
进行分类,定义距离即可。
根据此,也可以做二维索引,甚至三维。
2、候选段
基于索引,找出所有相似的段。
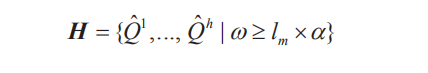
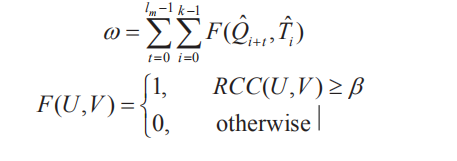
视频相似度检测
1、索引查找
2、基于索引,进行滑动查找。
设定阈值。
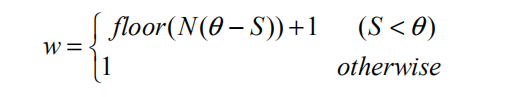
3、t检验
这里基于分块,将块摊开成一维分布。
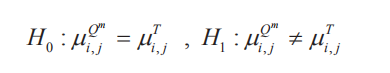
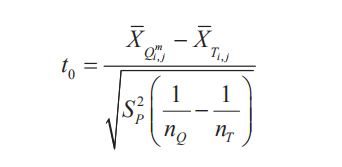
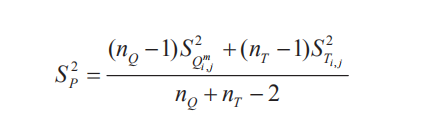
代码实现:
提取关键帧:
import numpy as np
import cv2
cap = cv2.VideoCapture('D:/ai/CV/pyt/test4.avi')
bb = 4 #分块数
rcc_rate = 0.99#RCC相关系数的阈值
rcc_windows = 11 #卷积平滑窗口
#接下来要用的函数
#分块计算像素亮度的定序测度Rank矩阵
def imgblock(mat):
r=mat.shape[0]//bb
w=mat.shape[1]//bb
t=np.zeros(bb*bb)
for R in range(bb):
for W in range(bb):
ll=R*r
lr=(R+1)*r
rl=W*w
rr=(W+1)*w
t[R*bb+W]=np.sum(mat[ll:lr,rl:rr])/(r/bb*w/bb)
res=np.argsort(t)
res+=1
res=res.reshape((bb,bb))
#print(res)
return res
#计算两帧之间的RCC系数
def RCC(mata,matb):
diff=np.sum(np.square(mata-matb))##计算平方差,两帧之间的欧式距离
N=bb*bb
rcc=1-6*diff/(N*(N**2-1))
print(rcc)
return rcc
#卷积光滑
def smooth(npary,windows):
len_npary = npary.shape[0]
res = np.zeros(npary.shape)
for k in range(len_npary):
for i in range(bb):
for j in range(bb):
l = max(0,k-windows//2)
r = min(npary.shape[0],k+windows//2)
res[k,i,j] = np.sum(npary[l:r+1,i,j])/(windows)
return res
# 提取帧的预处理部分
index=0
time=0 #用于指定帧的时长
L=[]
#提取帧
while (cap.isOpened()):
cap.set(cv2.CAP_PROP_POS_MSEC,time)
ret,img = cap.read()#获取图像
#cv2.imshow("00"+str(index),img)
#cv2.waitKey()
if not ret: #如果获取失败,则结束
print("exit")
break
img0 = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#转换成灰度图
tmp = np.array(img0)
L.append(imgblock(tmp))
time+=50 #设置每隔50ms读取帧
index+=1
print(index)#便于观看进度
# if index > 20 :
# break
#转换成numpy矩阵,并且初始化flag矩阵,表示是否是关键帧
L=np.array(L)
flag=np.zeros(L.shape[0])
L=smooth(L,rcc_windows)
pre = 0
for i in range(L.shape[0]-1):
if RCC(L[i],L[i+1]) < rcc_rate:
if i - pre >= 10:
flag[i] = 1
pre = i
index=0
time=0
num=0
while (cap.isOpened()):
cap.set(cv2.CAP_PROP_POS_MSEC,time)
ret,img = cap.read()#获取图像
#cv2.imshow("00"+str(index),img)
#cv2.waitKey()
if not ret: #如果获取失败,则结束
print("exit")
break
if flag[index] == 1:
cv2.imwrite('./RCC_4/{0:05d}.jpg'.format(num),img)#保存关键帧
num+=1
time+=50 #设置每隔50ms读取帧
index+=1
# print(index)#便于观看进度
# if index > 20 :
# break
帧间差分实现提取关键帧:
import numpy as np
import cv2
cap = cv2.VideoCapture('D:/ai/CV/pyt/test4.avi')
video_num = 0#初始视频的帧数量
diff_array = []#差分序列
len_window = 21#平滑窗口大小、奇数
local_max = []#局部最值序列
local_max_windows = 8#局部最值窗口
#接下来要用的函数
def smooth(npary,windows):
#这里实现对一维数组的卷积平滑
npary = np.convolve(npary,np.ones(windows))
mid = windows // 2
Len = npary.shape[0]
return npary[mid:Len-mid]
def get_img(ok):
# 提取帧的预处理部分
index=0
time=0 #用于指定帧的时长
L=[]
cap.set(cv2.CAP_PROP_POS_MSEC,time)
ret,img = cap.read()
pre = np.zeros((np.array(cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)).shape))
iterator = 0 #迭代局部序列
num = 0#计数保存
#提取帧
while (cap.isOpened()):
cap.set(cv2.CAP_PROP_POS_MSEC,time)
ret,img = cap.read()#获取图像
#cv2.imshow("00"+str(index),img)
#cv2.waitKey()
if not ret: #如果获取失败,则结束
print("读取结束")
break
if ok == 1:
img0 = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#转换成灰度图
tmp = np.array(img0)
L.append(np.sum(tmp-pre) / (tmp.size) )
pre = tmp
else :
if iterator < local_max.shape[0] and index == local_max[iterator]:
cv2.imwrite('./diff_4/{0:05d}.jpg'.format(num),img)#保存关键帧
num+=1
iterator += 1
print(index)
time += 50 #设置每隔50ms读取帧
index += 1
#print(index)#便于观看进度
L=np.array(L)
if ok:
return index,L
def get_local_max(npary,windows):
Len = npary.shape[0]
L = []
for i in range(Len):
l = max(0,i-windows)
r = min(Len-1,i+windows)
if npary[i] == np.max(npary[l:r+1]):
L.append(i)
L = np.array(L)
return L
##获取一遍视频帧,并得到差分序列,对其进行均值平滑
video_num,diff_array = get_img(1)
print(diff_array)
diff_array = smooth(diff_array,len_window)
print(diff_array)
#得到局部最值序列
local_max = get_local_max(diff_array,local_max_windows)
##提取关键帧
get_img(0)
