对于数据访问层 无论是SQL数据库还是NOSQL数据库 Spring Boot默认采用整合Spring Data的方式进行了统一的处理
且Spring Data里添加了大量的自动配置 还引入各种Template和Repository来简化对数据访问层的操作 大大方便了开发者
因而 只需进行简单的设置即可
一、配置及使用JDBC与Template
1、配置使用JDBC
步骤很简单 三部曲:
- 1、引入starter:spring-boot-starter-jdbc
- 2、配置application.yml
- 3、测试
项目若是用SpringBoot的Initializer启动器来创建的话 添加MySQL的Driver和JDBC即可:

若手动创建项目引入依赖 则需引入:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
然后 是配置
yml配置:
spring:
datasource:
username: root
password: 123456
url: jdbc:mysql://数据库ip:3306/数据库名
driver-class-name: com.mysql.cj.jdbc.Driver
然后就可以简单测试了
在测试的时候 若报错:
java.sql.SQLException: The server time zone value ‘�й���ʱ��’ is unrecognized or represents more than one time zone. You must configure either the server or JDBC driver (via the ‘serverTimezone’ configuration property) to use a more specifc time zone value if you want to utilize time zone support.
那么 在配置文件的url后面加上?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC即可
所有的配置信息都在DataSourceProperties这个类中
自动配置的原理是org.springframework.boot.autoconfigure.jdbc包下的DataSourceConfiguration类 用于根据配置来判断使用何种数据源
可在配置文件中用spring.datasource.type来指定数据源的类型
SpringBoot 2.x新版本默认内置支持以下三种数据源:
- org.apache.tomcat.jdbc.pool.DataSource
- HikariDataSource
- org.apache.commons.dbcp2.BasicDataSource
当然 还可自定义 例如c3p0 Druid之类的
spring boot1.5之前版本默认使用的是tomcat连接池
spring boot2.0之后版本默认使用的是HikariCP连接池
在底层 DataSourceAutoConfiguration类给IOC容器添加了一个DataSourceInitializerInvoker类 即数据源初始化类
这个类实际上是个监听器 可通过引用的DataSourceInitializer的initSchema()方法来运行建表语句和插入数据的sql语句
在底层已经对命名初始化了 因而 若是建表语句 只须将文件命名为schema-*.sql这种类型即可
默认的命名是schema或schema-all 因此 将sql文件名称改成这样的 然后放在resources目录下即可被识别 然后启动的时候自动被加载
可在配置文件中通过spring.datasource.schema来指定sql文件的位置及名称
例:
spring:
datasource:
schema: classpath:department.sql
若是插入数据语句 只须将文件命名为data-*.sql即可
注:在Spring2.x新版本中 若是要执行sql文件 还须配置spring.datasource.initialization-mode=always 表示始终执行初始化
否则默认仅初始化嵌入的数据源 而不会初始化所有数据源 从而导致sql文件不会被执行
2、使用JdbcTemplate来操作数据库
SpringBoot JDBC底层已经配置好了JdbcTemplate 因此可直接拿来使用
测试代码(添加了个web的starter):
@Controller
public class DoJdbcController {
@Autowired
JdbcTemplate jdbcTemplate;
@GetMapping("/query")
@ResponseBody
public Map<String,Object> map()
{
List<Map<String, Object>> list = jdbcTemplate.queryForList("select * from department");
return list.get(0);
}
}
效果:
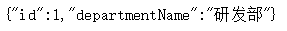
非常方便
二、配置及使用Druid和数据源监控
Druid的阿里的一款数据源 其一大特点就是提供了监控功能 还是挺方便的
1、整合Druid数据源
首先 是添加依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
然后是配置 指定数据源的类型:
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
还有很多配置参数:
spring:
datasource:
# 数据源基本配置
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://数据ip:3306/数据库名
type: com.alibaba.druid.pool.DruidDataSource
# 数据源其他配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
filters: stat,wall,log4j # 配置监控统计拦截的filters 若去掉后则监控界面的sql无法统计 wall用于防火墙
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
然而 仅仅配置之后是不会生效的 因为这些属性并没有在DataSourceProperties之内
也就是说 这些属性并不能绑定到数据库的配置中 自然也就不会起作用
因此 还需自己进行配置:
自己创建一个配置类
@Configuration
public class DruidConfig {
// 不用反射创建的数据源 而是自己创建
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druid()
{
return new DruidDataSource();
}
}
有可能会报Caused by: java.lang.ClassNotFoundException: org.apache.log4j.Priority异常
这是因为SpringBoot的日志jar包和Druid的日志jar包冲突了 有好几种解决方法
其中一种比较好的解决方法是引入日志转换包:
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
<version>1.7.25</version>
</dependency>
完美解决
接下来就可以尽情使用Druid了
2、配置Druid的数据源监控
配置数据源监控也很简单
分为两步 其一是配置Servlet 另一是配置Filter
同样 还是要在自己创建的配置类中进行配置
@Configuration
public class DruidConfig {
// 配置Druid监控
// 1、配置一个管理后台的Servlet 用于处理进入后台的请求
@Bean
public ServletRegistrationBean statViewServlet()
{
ServletRegistrationBean<StatViewServlet> srb = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
// 设置初始化参数 更多参数在ResourceServlet类中
Map<String,String> initParams=new HashMap<>();
// 登录后台的用户名
initParams.put("loginUsername","admin");
// 登录后台的密码
initParams.put("loginPassword","123456");
// 允许访问的ip 默认或为空代表允许所有
initParams.put("allow","");
// 不允许访问的ip
initParams.put("deny","111.111.111.111");
srb.setInitParameters(initParams);
return srb;
}
// 2、配置一个用于监控的Filter
@Bean
public FilterRegistrationBean webStatFilter()
{
FilterRegistrationBean<Filter> frb = new FilterRegistrationBean<>();
// 传入Druid的监控Filter
frb.setFilter(new WebStatFilter());
// 设置初始化参数 更多参数在WebStatFilter类中
Map<String,String> initParams=new HashMap<>();
// 设置哪些路径不进行拦截 /druid不能拦截 因为这是监控的后台入口
initParams.put("exclusions","*.js,*.css,/druid/*");
frb.setInitParameters(initParams);
// 设置拦截的请求
frb.setUrlPatterns(Arrays.asList("/*"));
return frb;
}
}
后台界面:

