声明:
本篇博客目的仅为了读者学习爬虫知识,任何用于非法途径与本人无关,欢迎大家学习,本人对代码拥有最终解释权,如果读者需要使用其中的代码,请在注释中写明作者:杨文豪,来自 这个页面Tks!!。
本篇将我当时遇到的坑全部记录了
文末附完整代码
第一步分析登录需要
参数分析
①首先查看登录post数据的地方
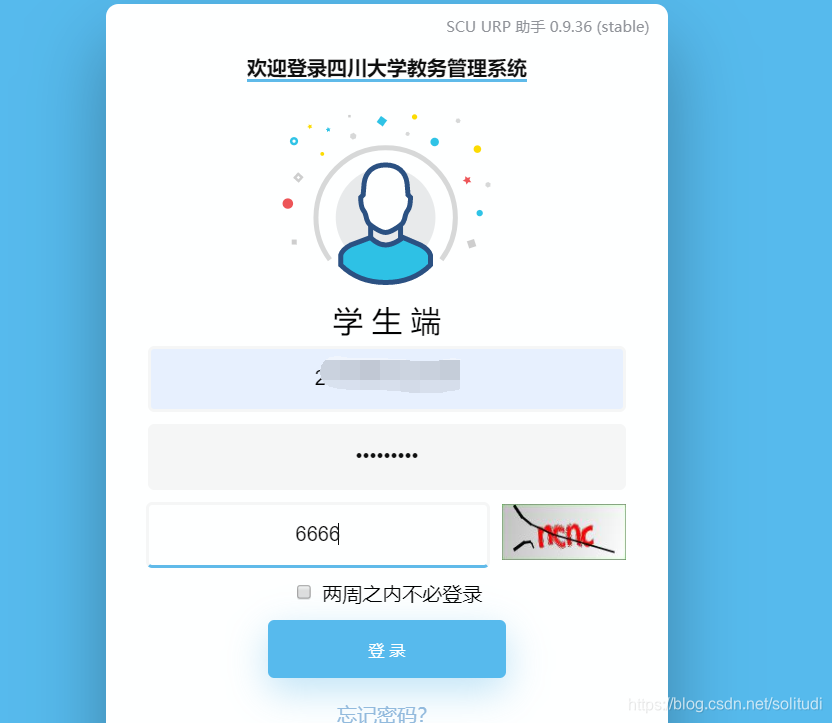
②通过FD抓包我们得到了它是向http://zhjw.scu.edu.cn/j_spring_security_check这个网址post数据,如下图,然后我们看参数里面,j_username是明文,j_password则是加密的内容,猜测在网页响应文件里面应该由我们需要的答案
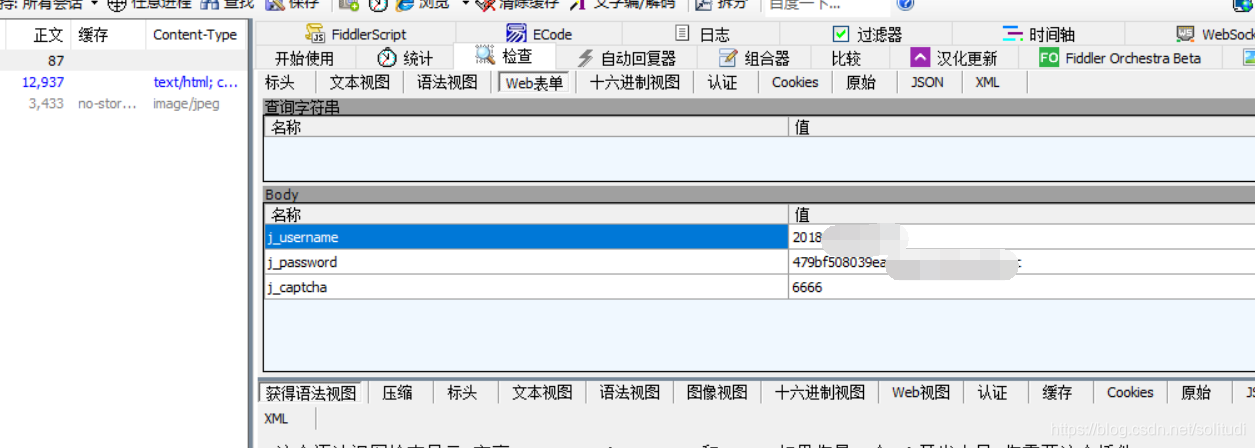
如下图,我们不难发现我们的密码只是简单的执行了md5加密,那就很简单了,那么接下来的任务就只是得到验证码

③关于验证码的问题,其实有两种方式,第一种用selenium去模拟浏览器行为,但是这样太慢了,不是我们想要的,我们想通过requests模块去得到想要的答案
第二步验证码的获取
首先我们要得到验证码的请求地址,审查元素可得/img/captcha.jpg

接下来我们就先开始编写代码,当然说个前提,这里请求验证码的时候必须带上cookie,代表是你的这个账号唯一标准,不然到时候请求到的cookie没用,当时遇到的坑!!!
既然如此不如用session保持会话状态
r = session.get('http://202.115.47.141/img/captcha.jpg', headers=headers_for_captcha)
with open('captcha.jpg','wb+') as f:
f.write(r.content)
然后我们去打开验证码图片,发现每次运行都是不一样的,okk,但如果就这样你就以为可以post那就大错特错了, 这里有个坑 ,就是验证码的获取也是很独特,F12带你见真相
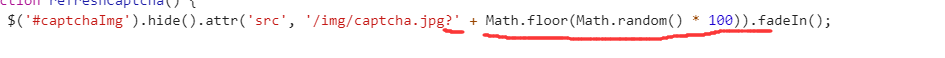
看到没,后面用get请求还搞了个随机数,那么现在就难不倒我们啦
soup = BeautifulSoup(r.text, 'lxml')
captcha_url = soup.find("img", id="captchaImg")['src']
# 链接来自url中算法
url_captcha = 'http://202.115.47.141' + captcha_url + '?' + str(random.randint(1, 100))
第三步:登录
这样就没问题了嘻嘻,接下来只需要组合参数,当然每次手动打开验证码显得特别麻烦,我们就是用PIL吧
data = {
'j_username': username,
'j_password': password,
'j_captcha': captcha
}
r = session.post(url_login, headers=headers_for_captcha, data=data)
return r.request.headers['Cookie']
这样运行一遍程序,成功了对吧,那么就结束啦!
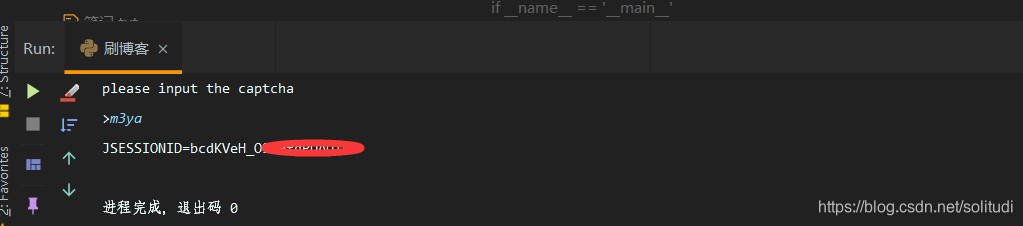
附:完整代码
import requests
import hashlib
import random
from PIL import Image
from bs4 import BeautifulSoup
def captcha_get():
username = '学号'
password = hashlib.md5(b'密码').hexdigest()
url = 'http://202.115.47.141'
url_login = 'http://zhjw.scu.edu.cn/j_spring_security_check'
session = requests.session()
headers_for_captcha = {
'Host': '202.115.47.141',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3754.400 QQBrowser/10.5.4034.400',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Referer': 'http://202.115.47.141/login?errorCode=badCaptcha',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
r = session.get(url, headers=headers_for_captcha)
soup = BeautifulSoup(r.text, 'lxml')
captcha_url = soup.find("img", id="captchaImg")['src']
# 链接来自url中算法
url_captcha = 'http://202.115.47.141' + captcha_url + '?' + str(random.randint(1, 100))
r = session.get(url_captcha, headers=headers_for_captcha)
print(r.url)
with open('captcha.jpg', 'wb+') as f:
f.write(r.content)
try:
im = Image.open('captcha.jpg')
im.show()
im.close()
except:
print(u'请到 根目录找到captcha.jpg 手动输入')
captcha = input("please input the captcha\n>")
data = {
'j_username': username,
'j_password': password,
'j_captcha': captcha
}
r = session.post(url_login, headers=headers_for_captcha, data=data)
return r.request.headers['Cookie']
if __name__ == '__main__':
print(captcha_get())
