-
gdb调试
GDB(GNU Debugger)是GCC的调试工具。功能如下:1. 启动你的程序,可以按照你的自定义的要求随心所欲的运行程序 2. 可让被调试的程序在你所指定的调试的断点出停住。(断点可以是条件表达式) 3. 当程序被停住的时候,可以检查此时你的程序中所发生的事 4. 动态的改变你程序的运行环境- 生成可调式的gdb文件的时候在gcc编译的时候要加参数 -g
- 启动gdb
1. start 只执行一步
2. n(next)----执行下一步
3. s(step)----可以进入到函数体的内部
4. c (continue)----直接停在断点的位置 - 查看代码
1. l(list)
2. l + 行号
3. l + 文件名 + : + 函数名
4. l+ 文件名 + : + 行号 - 设置断点
- 设置当前文件断点
- break + 行号(break可以简写为b)
- break + 函数名
- 设置指定文件断点
- break + 文件名 + 行号
- break + 文件名 + 函数名
- 设置条件断点
b + 行号 + 条件(if I == 15) - 删除断点
del + 断点对应的编号
- 设置当前文件断点
- 查看设置的断点
info + break(简写:I b) - 开始执行gdb调试(start)
- 执行一步操作
- n(next)----执行下一步
- s(step)----可以进入到函数体的内部
- c(continue)----直接停在断点的位置
- 单步调试
- 进入函数体内部:s
- 从函数的内部跳出:finish(前提是要去掉函数体内的断点)
- 退出当前循环:u
- 查看当前变量的值
p(print) + 变量名 - 查看变量的类型
ptype + 变量名 - 设置变量的值
set var + 变量名 + ‘=’ + 值(避免等待) - 设置追踪变量
- display + 变量名
- info + display(显示追踪变量)
- undislay + 追踪变量的编号
- 退出gdb调试
quit
-
makefile的编写
-
make命令执行的时候,需要一个makefile文件,以告诉make命令需要怎样的去编译和链接程序。
makefile来告诉make命令如何编译和链接这几个文件,规则是:- 如果这个工程没有编译过,那么所有的c文件都要进行编译和链接
- 如果这个工程的某几个C文件被修改,那么我们只编译被修改的C文件,并链接目标程序
- 如果这个工程的头文件被改变了,那么我们只需要编译被引用了这几个头文件的C文件,并链接目标程序
- 只要makefile文件写的好,所有的这一切,只用一个make命令就可以完成,make命令会自动只能的根据当前文件修改的情况来确定那些文件需要重新编译,从而自己编译所需要的文件和链接目标程序
-
makefile的命名
MakeFile 或者 makefile -
makefile的规则(makefile中最核心的内容)
1. Target…:prerequisites… Command … … 2. target也就是一个目标文件,可以是object File,也可以是执行文件,还可以是一个标签(Label) prerequisites就是,要生成那个target所需要的文件或是目标 command就是make需要执行的命令。(任意的Shell命令) 3. 这是一个文件的依赖关系,target这一个或多个的目标文件依赖于prerequisittes中的文件,其生成规则定义在command中。说白一点,prerequisites中如果有一个以上的文件比target文件要新的话,command所定义的命令就会被执行。 4. 在定义好依赖关系以后,后续的那一行定义了如何生成目标文件的操作系统命令,一定要以一个Tab键作为开头。make并不管命令是如何工作的,他只管执行所定义的命令。make会比较targets文件和prerequisites文件的修改日期,如果prerequisites文件的日期要比targets文件的日期要新,或者target不存在的话,那么make就会执行后面的命令 -
一个例子
1) test目录:
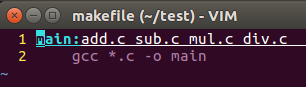
2) makefile文件的内容:
3) 在test目录下输入make命令就会执行command命令,并且产生可执行文件main
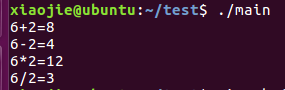
4) 输入命令:./main
-
make的工作方式
在默认的方式下,也就是我们只输入make命令,执行步骤为:- make会在当前目录下找名字叫"Makefile"或"makefile"的文件
- 如果找到,他会找文件中的第一个目标文件(target),并把这个文件作为最终的目标文件
- 如果目标文件不存在,或是目标文件所依赖的.o文件的修改时间要比目标文件新,那么他就会执行后面所定义的命令来生成目标文件
- 如果目标文件所以来的.o文件也存在,那么make会在当前文件中找目标文件为.o文件的依赖性,如果找到则在根据那一个规则生成.o文件(这像是一个堆栈过程)

- C文件和H文件是存在的,于是make会生成.o文件,然后再用.o文件生成make的终极任务,也就是目标文件了
-
makefile中使用变量
- 普通变量
- 当makefile文件变的复杂的时候,为了makefile的易维护,在makefile中我们可以使用变量,makefile的变量也就是一个字符串

- 由makefile维护的一些变量,通常格式都是大写。
- 有些变量有默认值(CC:默认值为cc cc==gcc)
- 有些变量没有默认值
- CPPFLAGS:预处理需要的选项 如:-I
- CFLAGS:编译的时候使用的参数 -wall -g -c
- LDFLAGS:链接库使用的选项 -L -l
- 用户也可以修改这些变量的值(CC = gcc)
- 当makefile文件变的复杂的时候,为了makefile的易维护,在makefile中我们可以使用变量,makefile的变量也就是一个字符串
- 自动变量
- 变量:
a) $@ -->> 规则中的目标
b) $< -->> 规则中的第一个依赖条件
c) $^ -->> 规则中的所有的依赖文件 - 模式规则:
a) 在规则的目标定义中使用 %
b) 在规则的依赖条件中使用 %

- 变量:
- 普通变量
-
make自动的推导
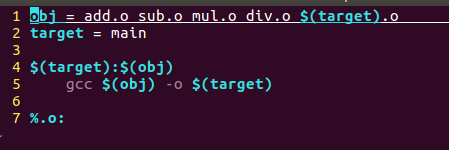
GNU的make很强大,他可以自动推导文件及文件依赖关系后面的命令,只要看到一个.o文件,他就会把.c文件添加到依赖关系中,并且后面的也会推导出来
-
makefile里面的内容:
makefile里面主要包含了五个东西:显示规则、隐晦规则、变量定义、文件指示和注释- 显示规则:显示规则说明了,如何生成一个或多个目标文件。这是由makefile的书写者明显指出,要生成的文件,文件的依赖,生成的命令
- 隐晦规则:由于我们的make有自动推导功能,所以隐晦规则可以让我们比较粗糙的书写makefile,这是由make所支持的
- 变量的定义:在makefile中我们要定义一系列的变量,变量一般都是字符串,当makefile被执行的时候,其中的变量就会被扩展到相应的引用位置上
- 文件指示:三部分:
- 一个makefile中引用另一个makefile(像C语言中的include)
- 根据某些情况指定makefile文件中有效部分(像C语言中预编译#if一样)
- 定义一个多行命令
- 注释:makefile中只有行注释,其注释是“#”字符,如果要使用“#”字符,要进行反斜杠转义,如:“/#”
在makefile中的命令,必须要以tab键开始
-
makefile的两个函数
在makefile中每个函数都有返回值扫描二维码关注公众号,回复: 10381882 查看本文章
- 获取指定目录中.c文件
src = $(wildcard ./.c)
函数名为wildcard
目录为./.c(当前目录下的所有.c文件)
$为取值对返回的值进行获取 - 将.c文件替换成.o文件
obj=$(patsubst ./%.c, ./%.o, $(src))
函数名为patsubst
./%.c为c文件
./%.o为o文件
$(src)里面存储的.c文件
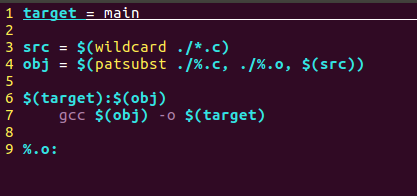
- 获取指定目录中.c文件
-
删除*.o文件和目标文件(清除中间的临时文件)(在终端输入命令:make clean就会执行makefile文件中的rm $(obj) $(target) -f)
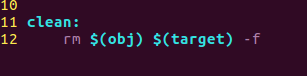
参数-f的作用:是强制执行前面的命令 -
伪目标
- 原因
命令make clean在当前的目录下没有生成一个文件,因此clean为伪目标,如果在当前的文件下创建一个clean文件,在执行make clean命令的时候就会提示“‘clean’ is up to date”,就不会执行"rm $(obj) $(target) -f"这条命令 - 解决办法:
在clean前面声明,clean为伪目标

- 原因
-
-
系统的Io函数
查看文件的格式:file + 文件名称-
C库IO函数工作流程

-
pcb和文件描述符

-
虚拟地址空间

-
cpu为什么要使用虚拟地址空间与物理地址空间映射?解决了什么样的问题?
- 方便编译器和操作系统安排程序的地址分布。
程序可以使用一系列相邻的虚拟地址来访问物理内存中不相邻的大内存缓冲区 - 方便进程之间的隔离
不同的进程使用的虚拟地址彼此隔离,一个进程中的代码无法更改正在由另一个进程使用的物理内存 - 方便操作系统使用内存
程序可以使用一些列的虚拟地址来访问大于可用物理内存的内存缓冲区。当物理内存的供应量变小的时候,内存管理器会将物理内存页(通常大小为4KB)保存到磁盘文件中
- 方便编译器和操作系统安排程序的地址分布。
-
库函数与系统函数的关系

f. 函数(open、read、write、lseek、close)查man文档(man 2 + 函数名称) errno: 1) 是一个全局变量(任何标准C库函数都能对其进行修改(Linux系统函数更可以)) 2) 错误信息定义的位置: a) 第1-34个错误定义: /usr/include/asm-gengric/errno-base.h b) 地35-133个错误定义: /usr/include/asm-generic/errno.h 3) 是记录系统的最后一次错误代码,代码是一个int型的值 a) 每个errno值对应着以字符串表示的错误类型 b) 当调用“某些”函数出错时,该函数会重新设置errno的值 4) perror a) 头文件:stdio.h b) 函数定义:void perror(const char * s) c) 函数说明: i) 用来将上一个函数发生错误的原因输出到标准设备(stderr) ii) 参数s所指的字符串会先打印出,后面在加上错误原因字符串 iii) 此错误原因依照全局变量errno的值来决定要输出的字符串 1. open 1) 头文件: a) #include<sys/types.h> b) #include<sys/stat.h> c) #include<fcntl.h> 2) 函数定义 a) int open(const char * pathname,int flags); b) int open(const char * pathname,int flags,mode_t mode) 3) 函数说明(用来打开一个存在或者打开一个不存在的文件) 4) 参数说明: a) pathname:打开文件的路径(绝对路径或者是相对路径) b) flags:文件的打开方式 i) the argument flags must include one of the following access modes:O_RDONLY,O_WRONLY,or O_RDRW.This request opening the file read-only,write-only,or read/write, respectively ii) in addition,zero or more file creation flags and file status flags can be bitwise-or'd in flags. The file creation flags are O_CLOEXEC,O_CREAT,O_DIRECTORY,O_EXCL,O_NOCTTY,O_NOFOLLOW,O_TEPFILE, and O_TRUNC. The file status flags are all of the remaining flags listed below. The distinction between these two groups id flags is that the file status flags can be retricved and (in some cases) modified. c) mode:指文件创建后的权限 注意:文件的实际权限 = 创建文件是给定的权限 & 本地掩码取反 查看掩码umask 修改掩码umask + 三位的八进制数 5) 函数返回值: open() return the new file descriptor, or -1 if an error occurred (in which case,errno is set appropriately). 2. read 1) 头文件: a) #include<unistd.h> 2) 函数定义 a) ssize_t read(int fd,void *buf,size_t count) i) size_t是无符号的整数 ii) ssize_t是有符号的整数 3) 函数说明 a) read() attempts to read up to count bytes from file descriptor fd into the buffer starting at buf 4) 参数说明 a) fd:文件描述符 b) buf:缓冲区 c) count:缓冲区的大小 5) 函数返回值 a) on success, the number of bytes read is returned (zero indicates end of file), and the file position is advanced by this number. It is not an error if this number is smaller than number of bytes requested; this may happen for example because fewer bytes are actually available right now (maybe because we were close to end-of-file, or because we are reading from a pipe, or from a terminal), or because read() was interrupted by a signal b) on error, -1 is returned, and errno is set appropriately. In this case, it is left unspecified whether the file position (if any) changes 3. write 1) 头文件: a) #include<unistd.h> 2) 函数定义: a) Ssize_t write(int fd, const void * buf, size_t count) i) Size_t是无符号的整数 ii) Ssize_t是有符号的整数 3) 函数说明: a) write() writes up to count bytes from the buffer pointed buf to the file referred to by the file descriptor fd 4) 参数说明: a) fd:文件描述符 b) buf:缓冲区 c) count:写的位置 5) 函数返回值: a) on success, the number of bytes written is returned (zero indicates nothing was written). It is not an error if this number is smaller than the number of bytes requested; this may happen for example because the disk device was filled. b) on error, -1 is returned,and errno is set appropriately 4. lseek(获取文件大小、移动文件指针、文件拓展) 1) 头文件: a) #include<sys/types.h> b) #include<unistd.h> 2) 函数定义: a) off_t lseek(int fd,off_t offset,int whence) 3) 函数说明:以指定的位置打开文件 4) 参数说明: a) fd:文件描述符 b) offset:文件偏移量 c) whence: i) SEEK_SET(the offset is set to offset bytes) ii) SEEK_CUR(the offset is set to its current location plus bytes) iii) SEEK_END(the offset is set to the size of the file plus offset byte) 5) 函数返回值: a) upon successful completion,lseek() returns the resulting offset location as measured in bytes from the beginning of the file. b) on error, the value (off_t) -1 is returned and errno is set to indicate the error 5. close 1) 头文件: a) #include<unistd.h> 2) 函数定义 a) int close(int fd); 3) 函数说明:关闭一个已经打开的文件 4) 参数说明: a) fd:文件描述符 5) 函数返回值: close() returns zero on success. On error, -1 is returned, and errno is set appropriately 6) 错误类型: a) EBADF: fd isn't a valid open file descriptor b) EINTR: The close() call was interrupted by a signal c) EIO:An I/O error occurred
-
下面的是笔者的微信公众号,欢迎关注,会持续更新c++、python、tensorflow、机器学习、深度学习、计算机视觉等系列文章,公众号中内含300+本pdf电子书籍,肯定有你需要的一本,关注公众号即可领取哦。

如果你对JAVA方面感兴趣,可以关注下面JAVAERS公众号,陪你一起学习,一起成长,一起分享JAVA路上的诗和远方。在公众号里面都是JAVA这个世界的朋友,公众号每天会有技术类文章,面经干货,也有进阶架构的电子书籍,如Spring实战、SpringBoot实战、高性能MySQL、深入理解JVM、RabbitMQ实战、Redis设计与实现等等一些高质量书籍,关注公众号即可领取哦。

