- 比如说有这样的一个
data={'username':'李华','sex':'male','age':16}现在用json包来处理这条Jason数据:
import json
data = {'username':'李华','sex':'male','age':16}
in_json = json.dumps(data)- 1
- 2
- 3
>>>import json
>>>data = {'username':'李华','sex':'male','age':16}
>>>in_json = json.dumps(data)
>>>in_json
'{"sex": "male", "age": 16, "username": "\\u674e\\u534e"}'- 1
- 2
- 3
- 4
- 5
- 可以看一下dumps()/dump()的文档
def dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True,allow_nan=True, cls=None, indent=None, separators=None,default=None, sort_keys=False, **kw):
def dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True,allow_nan=True, cls=None, indent=None, separators=None,default=None, sort_keys=False, **kw):- 1
- 2
其中dumps()里面的参数解释:
Serialize
objto a JSON formattedstr.(字符串表示的json对象)
Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。)
Ifcheck_circularis false, then the circular reference check for container types will be skipped and a circular reference will result in anOverflowError(or worse).
Ifallow_nanis false, then it will be aValueErrorto serialize out of rangefloatvalues (nan,inf,-inf) in strict compliance of the JSON specification, instead of using the JavaScript equivalents (NaN,Infinity,-Infinity).
indent:应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。default(obj)is a function that should return a serializable version of obj or raise TypeError. The default simply raises TypeError.
sort_keys:将数据根据keys的值进行排序。
To use a customJSONEncodersubclass (e.g. one that overrides the.default()method to serialize additional types), specify it with theclskwarg; otherwiseJSONEncoderis used.其中dump()里面的参数解释(只有一个fp参数不一样,其他的都一样):
Serialize
objas a JSON formatted stream tofp(a.write()-supporting file-like object).- 可以用dumps()函数里面的参数进行调整一下,结果就是可以输出中文。
>>>import json
>>>data = {'username':'李华','sex':'male','age':16}
>>>json_dic2 = json.dumps(data,sort_keys=True,indent=4,separators(',',':'),ensure_ascii=False)
>>>print(json_dic2)
{
"username":"李华",
"sex":"male",
"age":16
}===========================================================
一、概念理解
1、json.dumps()和json.loads()是json格式处理函数(可以这么理解,json是字符串)
(1)json.dumps()函数是将一个Python数据类型列表进行json格式的编码(可以这么理解,json.dumps()函数是将字典转化为字符串)
(2)json.loads()函数是将json格式数据转换为字典(可以这么理解,json.loads()函数是将字符串转化为字典)
2、json.dump()和json.load()主要用来读写json文件函数
二、代码测试
1.py

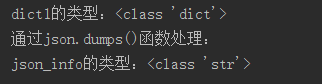
1 import json 2 3 # json.dumps()函数的使用,将字典转化为字符串 4 dict1 = {"age": "12"} 5 json_info = json.dumps(dict1) 6 print("dict1的类型:"+str(type(dict1))) 7 print("通过json.dumps()函数处理:") 8 print("json_info的类型:"+str(type(json_info)))
运行截图:
2.py
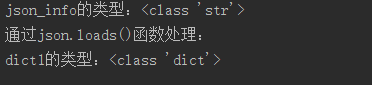
1 import json 2 3 # json.loads函数的使用,将字符串转化为字典 4 json_info = '{"age": "12"}' 5 dict1 = json.loads(json_info) 6 print("json_info的类型:"+str(type(json_info))) 7 print("通过json.dumps()函数处理:") 8 print("dict1的类型:"+str(type(dict1)))
运行截图:
3.py
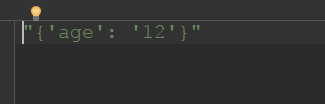
1 import json 2 3 # json.dump()函数的使用,将json信息写进文件 4 json_info = "{'age': '12'}" 5 file = open('1.json','w',encoding='utf-8') 6 json.dump(json_info,file)
运行截图(1.json文件):
4.py
1 import json 2 3 # json.load()函数的使用,将读取json信息 4 file = open('1.json','r',encoding='utf-8') 5 info = json.load(file) 6 print(info)
运行截图:
