1、哈希表(散列表)
hash_map基于hash table(哈希表)。哈希表最大的优点,就是把数据的存储和查找消耗的时间大大降低,几乎可以看成是常数时间;而代价仅仅是消耗比较多的内存。然而在当前可利用内存越来越多的情况下,用空间换时间的做法是值得的。另外,编码比较容易也是它的特点之一。它以键和值组成的对为基础。
统计字符在字符串出现的次数,或是否在某字符串中出现等等这类问题可以用哈希表来处理。
当字符是8位时,可以建立一个长度为256的哈希表(形式是数组),数组的下标是字符对应的ASCII码,数组的值可以是出现的次数,或者是否出现的布尔型变量。
2、合并排序(merge sort)
基于分治法,把排序问题拆分成自问题。分治策略的基本思想就是对于一个问题规模为N的问题,将其划分为规模足够小的K个子问题,子问题由于规模足够小可以直接求解,最后将规模足够小的K的问题的解合并得出原问题的解。
比如把序列分成若干几部分,分别排序,然后再将已经排好序的子序列进行合并。
3、高位数乘法karatsuba
ab*cd=10.^(n)*ac+10.^(n/2)*(ad+bc)+bd
其中,ad+bc=(a+b)*(c+d)-ac-bd,这样使得较小位数的乘法由四次降到了三次
4、变量关键字volatile
当要求使用volatile 声明的变量的值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。而且读取的数据立刻被保存。这个关键词在嵌入式系统中经常用到。
它适用于变量随时可能会有变化的情况。
5、二维递增数组的查找问题
数组中的每一行按照从左到右递增的顺序,每一列按照从上到下递增的顺序。
当一直以右上角或左下角为开始查找的位置时,问题得到了简化。
以右上角为例,这个位置的元素是该列最小的以及该行最大的。当要查找的数大于该元素时,删除该行;当要查找的数小于该元素时,删除该列;当要查找的数等于该元素时,已查找到,结束查找。
6、约瑟夫环问题
在一间房间总共有n个人(下标0~n-1),只能有最后一个人活命。
按照如下规则去杀人:
- 所有人围成一圈
- 顺时针报数,每次报到q的人将被杀掉
- 被杀掉的人将从房间内被移走
- 然后从被杀掉的下一个人重新报数,继续报q,再清除,直到剩余一人
传统做法是用链表做,并将链表的尾与首相连。
第二种方法是转换成一个递归问题,即找出规律。
f(n,m)=[f(n-1,m)+m]%n,n>1
重点考虑的一点是要把杀死第q个人之后,剩下人的位置发生了变化。这个变化规律理解清就好了。
0 1 2 3 4 5 ...... n-1 总共n人设第q个人也就是下标为q-1的那位,
杀死:剩下n-1个人,如下:q q+1 q+2 ...... n-2 n-1 0 1 2 ...... q-2 (这里是除去q-1这位兄台的剩余n-1人)
这时,又来重复我们的老套路:将新的被杀的后一个人作为新的0号,
于是新的如下:0 1 2 ...... .......... ........ n-2
新旧顺序号的关系如下:old = (new + q) % n ,new= (old + q) % n
7、c++中class成员变量初始化与在类中的声明顺序有关
long long int 是64 位的
在编程之前,一定要把容易忽略的边界条件和特殊输入想清楚。
8、动态空间 用new指令,该空间使用结束后一定要用delete指令,防止内存泄漏。
9、C++的函数最多只能有一个返回值,而脚本语言matlab(用function),python(用def)的函数的返回值不受限。
10、函数传递的方式有按值传递,指针传递,引用传递三种。按值传递,它只是将参数做了备份,无法修改函数之外的外部变量,所以这个不是很常用;
引用传递在声明时要加&
引用传递的本质:一块堆内存空间可以同时被多个栈内存空间所指向,不同的栈可以修改同一块堆内存的空间。
11、图像压缩编码常用的Z字形扫描(Zigzag Scan)
在图像进行Z变换后,大系数集中在左上角(低频分量),其余的零系数比较多,这样扫描编码会大大节省比特数,提高效率
而且高频分量去掉一部分后,只是损失了部分图像细节。
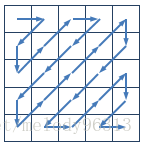
仔细分析可以发现它对应了四种情况:
(1)row=0且col+row=偶数,或者row=n-1且col+row=奇数;col++(水平向右)
(2) col=0且col+row=奇数,或者col=n-1且col+row=偶数; row++(竖直向下)
(3)col+row=奇数,col--,row++,(向左下角移动)
(4)col+row=偶数,col++,row--,(向右下角移动)
12、数组和链表
数组:
优点:内存是连续的,已知首地址后,所有元素都可以访问,因此易于随机访问
缺点:插入,删除元素的复杂度较高,需要平移部分数组。
要事先固定容量,不灵活,许多业务容量都是未知且变化的。普林斯顿的算法课中,老爷爷提出了一种解决方案:
当元素数量等于容量时,把容量扩充成2倍;当元素数量等于容量的一半时,把容量减为原来的一半。
注意:C++不提供对数组越界的检查,所以可能越界,即取到了不属于该数组的值,而且还不容易察觉出这个错误。
在对二维数组全部元素赋值时,第一维长度可以忽略。
链表:
优点:内存不连续,较灵活,方便删除和插入操作
缺点:只能从头部顺序访问
13、三叉链表和二叉树相比,多存储了一个父节点。
当算法中经常需要遍历或者查找节点在遍历过程中的前驱,后继指针,就需要把数据结构定义为这种形式
举例:剑指offer里的一道题(中序遍历)
给定一个二叉树和其中的一个结点,请找出中序遍历顺序的下一个结点并且返回。
注意,树中的结点不仅包含左右子结点,同时包含指向父结点的指针。
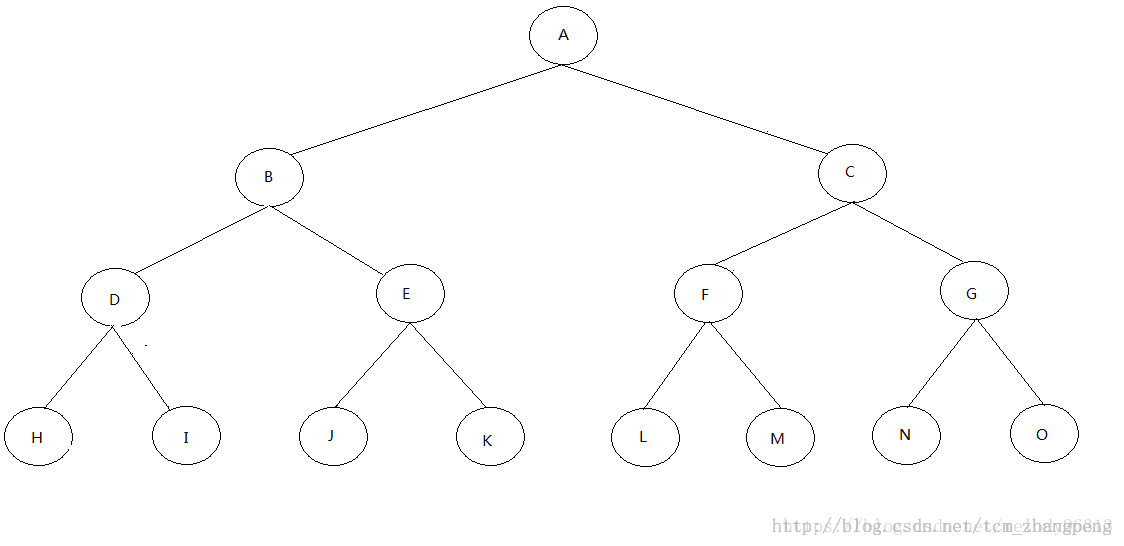
如果当前结点存在右子结点,那下一个结点就是从这个右子结点开始一直递归地找其最大深度地左子节点
如果当前结点不存在右子结点,且当前结点是其父结点的左子结点,那下一个结点就是其父结点;
如果当前结点不存在右子结点,且当前结点不是其父结点的左子结点,那就递归地指向父结点,直到满足结点是其父结点的左子结点,那下一个结点就是此刻的结点。如果直到根节点也不满足是左子节点的条件,则说明该结点是最后一个,那就结束