1、如何找出序列中出现次数最多的元素
from collections import Counter
words = [
‘look’, ‘into’, ‘my’, ‘eyes’, ‘look’, ‘into’, ‘my’, ‘eyes’,
‘the’, ‘eyes’, ‘the’, ‘eyes’, ‘the’, ‘eyes’, ‘not’, ‘around’, ‘the’,
‘eyes’, “don’t”, ‘look’, ‘around’, ‘the’, ‘eyes’, ‘look’, ‘into’,
‘my’, ‘eyes’, “you’re”, ‘under’]
word_counts = Counter(words)
出现频率最高的 3 个单词
top_three = word_counts.most_common(3)
#如何增加手动计数
morewords = [‘why’,‘are’,‘you’,‘not’,‘looking’,‘in’,‘my’,‘eyes’]
for word in morewords:
word_counts[word] += 1
word_counts[‘eyes’]
#或者使用update的方法
word_counts.update(morewords)
#Counter的数学运算
a = Counter(words)
b = Counter(morewords)
a[‘eyes’]
b[‘eyes’]
a+b
c[‘eyes’]



2、通过某个关键字排序一个字典列表
from operator import itemgetter
rows = [
{‘fname’: ‘Brian’, ‘lname’: ‘Jones’, ‘uid’: 1003},
{‘fname’: ‘David’, ‘lname’: ‘Beazley’, ‘uid’: 1002},
{‘fname’: ‘John’, ‘lname’: ‘Cleese’, ‘uid’: 1001},
{‘fname’: ‘Big’, ‘lname’: ‘Jones’, ‘uid’: 1004}
]
rows_by_fname = sorted(rows, key=itemgetter(‘fname’))
rows_by_uid = sorted(rows, key=itemgetter(‘uid’))
print(rows_by_fname)
print(rows_by_uid)
#或者使用itemgetter()也可以
rows_by_lfname = sorted(rows, key=itemgetter(‘lname’,‘fname’))
print(rows_by_lfname)
3、通过某个字段将记录分组,itertools.groupby() 函数应用于数据分组
rows = [
{‘address’: ‘5412 N CLARK’, ‘date’: ‘07/01/2012’},
{‘address’: ‘5148 N CLARK’, ‘date’: ‘07/04/2012’},
{‘address’: ‘5800 E 58TH’, ‘date’: ‘07/02/2012’},
{‘address’: ‘2122 N CLARK’, ‘date’: ‘07/03/2012’},
{‘address’: ‘5645 N RAVENSWOOD’, ‘date’: ‘07/02/2012’},
{‘address’: ‘1060 W ADDISON’, ‘date’: ‘07/02/2012’},
{‘address’: ‘4801 N BROADWAY’, ‘date’: ‘07/01/2012’},
{‘address’: ‘1039 W GRANVILLE’, ‘date’: ‘07/04/2012’},
]
from operator import itemgetter
from itertools import groupby
#先按照date排序
rows.sort(key=itemgetter(‘date’))
#遍历,循环将分组的结果打印出来
for date, items in groupby(rows, key=itemgetter(‘date’)):
print(date)
for i in items:
print(’ ', i)
4、过滤序列数据,如果有一个数据序列,想利用一些规则从中提取需要的值或者缩短序列
#使用列表推导式
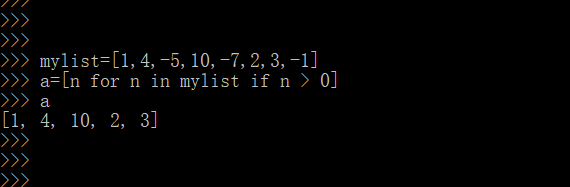
mylist=[1,4,-5,10,-7,2,3,-1]
a=[n for n in mylist if n > 0]
5、从字典中提取子集,如何提出字典中的部分字典
#字典推导式
prices = {‘ACME’: 45.23,‘AAPL’: 612.78,‘IBM’: 205.55,‘HPQ’: 37.20,‘FB’: 10.75}
#筛选value中查过200
p1 = {key: value for key, value in prices.items() if value > 200}
p1
#提取特定的key
tech_names = {‘AAPL’, ‘IBM’, ‘HPQ’, ‘MSFT’}
p2 = {key: value for key, value in prices.items() if key in tech_names}
p2





#p2也可以这样写,更加简洁
p3 = { key:prices[key] for key in prices.keys() & tech_names }
p3
6、转换过程中同时计算
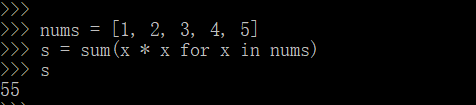
nums = [1, 2, 3, 4, 5]
s = sum(x * x for x in nums)
s
#例子
import os #导入os
files = os.listdir(‘路径’)#读取文件的名称
if any(name.endswith(’.py’) for name in files): #判断是不是有以.py结尾的文件
print(‘There be python!’)#如果是,则打印There be python
else:
print(‘Sorry, no python.’)#如果不是,则打印There be python


s = (‘ACME’, 50, 123.45)#元组
print(’,’.join(str(x) for x in s))#元组不能直接打印,str(x) for x in s是将遍历并转化成字符串,最后通过join连接,打印
portfolio = [
{‘name’:‘GOOG’, ‘shares’: 50},
{‘name’:‘YHOO’, ‘shares’: 75},
{‘name’:‘AOL’, ‘shares’: 20},
{‘name’:‘SCOX’, ‘shares’: 65}
] #带有字典的列表
min_shares = min(s[‘shares’] for s in portfolio)#取出share最小的值
min_shares
min_shares_portfolio = min(portfolio, key=lambda s: s[‘shares’])
min_shares_portfolio
7、合并多个字典
#collections库中的ChainMap函数,如果出现重复的Key,就会返回到第一次出现的key,也就是返回a为不是b中的z
a = {‘x’: 1, ‘z’: 3 }
b = {‘y’: 2, ‘z’: 4 }
from collections import ChainMap
c = ChainMap(a,b)
c
c[‘x’]
c[‘z’]
而对于字典的更新或删除操作总是影响的是列表中第一个字典
c[‘z’]=89
a[‘z’]#a字典中的z的value由3变成了89
c[‘z’]#c字典中的z的value由3变成了89,这是我修改的
b[‘z’]#b字典中的z的value依旧为3



#也可以使用update() 方法合并两个字典
a = {‘x’: 1, ‘z’: 3 }
b = {‘y’: 2, ‘z’: 4 }
merged = dict(b)#复制一个新的b,update会对原本的字典造成影响
merged.update(a)


