一、前言
依然是博主毕设的手语检测,好多图片要处理哦!
今天要处理视频,接触了一下,本来是毕设partner另一小姐姐主要研究的。
记录下我在视频处理方面的简单分析~
机器视觉中不可分离的一部分——视频识别,当然了,视频识别需要处理数据帧,用opencv是极好的;视频提取图像,在视频上绘制关键特征,分割图像,保存图像都是别叫重要的模块。
我们大多数时候都是对全视频帧数处理,会因为视频过大处理每一帧数据非常耗时;但在特定场合下,我们没有必要处理无效的视频帧数,That’s too bad;所以我们需要提取关键帧,即有效识别帧数。
一段视频:(手语:学校)

视频截取每一帧保存为图片:

手语识别的需求:
(图片截取于:《基于神经网络的中小词汇量中国手语识别研究》_李晓旭)


事实上,我们真正只需要识别关键帧,!

二、视频中保存每帧图片
可选部分~

主要是:cv2.imwrite()函数
import cv2
import os
# 从.avi 类型的视频中提取图像
def splitFrames(sourceFileName):
# 在这里把后缀接上
video_path = os.path.join('video/', sourceFileName + '.avi')
outPutDirName = 'video/img_' + sourceFileName + '/'
if not os.path.exists(outPutDirName):
#如果文件目录不存在则创建目录
os.makedirs(outPutDirName)
cap = cv2. VideoCapture(video_path) # 打开视频文件
num = 1
while True:
# success 表示是否成功,data是当前帧的图像数据;.read读取一帧图像,移动到下一帧
success, data = cap.read()
if not success:
break
# im = Image.fromarray(data, mode='RGB') # 重建图像
# im.save('C:/Users/Taozi/Desktop/2019.04.30/' +str(num)+".jpg") # 保存当前帧的静态图像
cv2.imwrite( outPutDirName +str(num)+".jpg", data)
num = num + 1
# if num % 20 == 0:
# cv2.imwrite('./Video_dataset/figures/' + str(num) + ".jpg", data)
print(num)
cap.release()
# 从.mp4 数据类型的视频中提取图像
def splitFrames_mp4(sourceFileName):
# 在这里把后缀接上
video_path = os.path.join('video/', sourceFileName + '.mp4')
times = 0
# 提取视频的频率,每25帧提取一个
# frameFrequency = 25
# 输出图片到当前目录vedio文件夹下
outPutDirName = 'video/video_' + sourceFileName + '/'
# 如果文件目录不存在则创建目录
if not os.path.exists(outPutDirName):
os.makedirs(outPutDirName)
camera = cv2.VideoCapture(video_path)
while True:
times+=1
res, image = camera.read()
if not res:
# print('not res , not image')
break
# if times%frameFrequency==0:
# cv2.imwrite(outPutDirName + str(times)+'.jpg', image)
# print(outPutDirName + str(times)+'.jpg')
cv2.imwrite(outPutDirName + str(times) + '.jpg', image)
print(times,end='\t')
print('\n图片提取结束')
camera.release()
if __name__ == '__main__':
im_file = 'video/'
# for im_name in im_names:
for im_name in os.listdir(im_file):
suffix_file = os.path.splitext(im_name)[-1]
if suffix_file == '.mp4':
print('~~~~~~~~~~ 从.mp4 视频提取图像 ~~~~~~~~~~~~~~~')
sourceFileName = os.path.splitext(im_name)[0]
splitFrames_mp4(sourceFileName)
elif suffix_file == '.avi' :
print('~~~~~~~~~~ 从.avi 视频提取图像 ~~~~~~~~~~~~~~~')
sourceFileName = os.path.splitext(im_name)[0]
splitFrames(sourceFileName)
三、帧间差法
1.两间查分法
步骤:
- 首先,我们加载视频并计算每帧之间的帧间差异
- 然后,选择以下三种提取有效帧的方法中的一种来提取关键帧
-
使用差值顺序
前几帧具有最大的帧间平均差被认为是关键帧。 -
使用差分阈值
平均帧间差大于平均帧间差的帧被认为是关键帧。 -
使用本地最大平均帧间差为局部最大值的帧为被认为是关键帧。
需要注意的是,平滑平均差值之前,计算局部最大值可以有效地消除噪声,重复提取相似场景的帧。
(1)处理一段视频
作者运用的是上述第三种方法——提取的是帧差最大值:

# -*- coding: utf-8 -*-
"""
Created on Tue Dec 4 16:48:57 2018
keyframes extract tool
this key frame extract algorithm is based on interframe difference.
The principle is very simple
First, we load the video and compute the interframe difference between each frames
Then, we can choose one of these three methods to extract keyframes, which are
all based on the difference method:
1. use the difference order
The first few frames with the largest average interframe difference
are considered to be key frames.
2. use the difference threshold
The frames which the average interframe difference are large than the
threshold are considered to be key frames.
3. use local maximum
The frames which the average interframe difference are local maximum are
considered to be key frames.
It should be noted that smoothing the average difference value before
calculating the local maximum can effectively remove noise to avoid
repeated extraction of frames of similar scenes.
After a few experiment, the third method has a better key frame extraction effect.
The original code comes from the link below, I optimized the code to reduce
unnecessary memory consumption.
https://blog.csdn.net/qq_21997625/article/details/81285096
@author: zyb_as
"""
import cv2
import operator # 内置操作符函数接口(后面排序用到)
import numpy as np
import matplotlib.pyplot as plt
import os
import sys
from scipy.signal import argrelextrema # 极值点
def smooth(x, window_len=13, window='hanning'):
"""使用具有所需大小的窗口使数据平滑。
This method is based on the convolution of a scaled window with the signal.
The signal is prepared by introducing reflected copies of the signal
(with the window size) in both ends so that transient parts are minimized
in the begining and end part of the output signal.
该方法是基于一个标度窗口与信号的卷积。
通过在两端引入信号的反射副本(具有窗口大小)来准备信号,
使得在输出信号的开始和结束部分中将瞬态部分最小化。
input:
x: the input signal输入信号
window_len: the dimension of the smoothing window平滑窗口的尺寸
window: the type of window from 'flat', 'hanning', 'hamming', 'bartlett', 'blackman'
flat window will produce a moving average smoothing.
平坦的窗口将产生移动平均平滑
output:
the smoothed signal平滑信号
example:
import numpy as np
t = np.linspace(-2,2,0.1)
x = np.sin(t)+np.random.randn(len(t))*0.1
y = smooth(x)
see also:
numpy.hanning, numpy.hamming, numpy.bartlett, numpy.blackman, numpy.convolve
scipy.signal.lfilter
TODO: 如果使用数组而不是字符串,则window参数可能是窗口本身
"""
print(len(x), window_len)
# if x.ndim != 1:
# raise ValueError, "smooth only accepts 1 dimension arrays."
#提高ValueError,“平滑仅接受一维数组。”
# if x.size < window_len:
# raise ValueError, "Input vector needs to be bigger than window size."
#提高ValueError,“输入向量必须大于窗口大小。”
# if window_len < 3:
# return x
#
# if not window in ['flat', 'hanning', 'hamming', 'bartlett', 'blackman']:
# raise ValueError, "Window is on of 'flat', 'hanning', 'hamming', 'bartlett', 'blackman'"
s = np.r_[2 * x[0] - x[window_len:1:-1],
x, 2 * x[-1] - x[-1:-window_len:-1]]
#print(len(s))
if window == 'flat': # moving average平移
w = np.ones(window_len, 'd')
else:
w = getattr(np, window)(window_len)
y = np.convolve(w / w.sum(), s, mode='same')
return y[window_len - 1:-window_len + 1]
class Frame:
"""class to hold information about each frame
用于保存有关每个帧的信息
"""
def __init__(self, id, diff):
self.id = id
self.diff = diff
def __lt__(self, other):
if self.id == other.id:
return self.id < other.id
return self.id < other.id
def __gt__(self, other):
return other.__lt__(self)
def __eq__(self, other):
return self.id == other.id and self.id == other.id
def __ne__(self, other):
return not self.__eq__(other)
def rel_change(a, b):
x = (b - a) / max(a, b)
print(x)
return x
def getEffectiveFrame(videopath,dir):
# 如果文件目录不存在则创建目录
if not os.path.exists(dir):
os.makedirs(dir)
(filepath, tempfilename) = os.path.split(videopath)#分离路径和文件名
(filename, extension) = os.path.splitext(tempfilename)#区分文件的名字和后缀
#Setting fixed threshold criteria设置固定阈值标准
USE_THRESH = False
#fixed threshold value固定阈值
THRESH = 0.6
#Setting fixed threshold criteria设置固定阈值标准
USE_TOP_ORDER = False
#Setting local maxima criteria设置局部最大值标准
USE_LOCAL_MAXIMA = True
#Number of top sorted frames排名最高的帧数
NUM_TOP_FRAMES = 50
#smoothing window size平滑窗口大小
len_window = int(50)
print("target video :" + videopath)
print("frame save directory: " + dir)
# load video and compute diff between frames加载视频并计算帧之间的差异
cap = cv2.VideoCapture(str(videopath))
curr_frame = None
prev_frame = None
frame_diffs = []
frames = []
success, frame = cap.read()
i = 0
while(success):
luv = cv2.cvtColor(frame, cv2.COLOR_BGR2LUV)
curr_frame = luv
if curr_frame is not None and prev_frame is not None:
#logic here
diff = cv2.absdiff(curr_frame, prev_frame)#获取差分图
diff_sum = np.sum(diff)
diff_sum_mean = diff_sum / (diff.shape[0] * diff.shape[1])#平均帧
frame_diffs.append(diff_sum_mean)
frame = Frame(i, diff_sum_mean)
frames.append(frame)
prev_frame = curr_frame
i = i + 1
success, frame = cap.read()
cap.release()
# compute keyframe
keyframe_id_set = set()
if USE_TOP_ORDER:
# sort the list in descending order以降序对列表进行排序
frames.sort(key=operator.attrgetter("diff"), reverse=True)# 排序operator.attrgetter
for keyframe in frames[:NUM_TOP_FRAMES]:
keyframe_id_set.add(keyframe.id)
if USE_THRESH:
print("Using Threshold")#使用阈值
for i in range(1, len(frames)):
if (rel_change(np.float(frames[i - 1].diff), np.float(frames[i].diff)) >= THRESH):
keyframe_id_set.add(frames[i].id)
if USE_LOCAL_MAXIMA:
print("Using Local Maxima")#使用局部极大值
diff_array = np.array(frame_diffs)
sm_diff_array = smooth(diff_array, len_window)#平滑
frame_indexes = np.asarray(argrelextrema(sm_diff_array, np.greater))[0]#找极值
for i in frame_indexes:
keyframe_id_set.add(frames[i - 1].id)# 记录极值帧数
plt.figure(figsize=(40, 20))
plt.locator_params("x", nbins = 100)
# stem 绘制离散函数,polt是连续函数
plt.stem(sm_diff_array,linefmt='-',markerfmt='o',basefmt='--',label='sm_diff_array')
plt.savefig(dir + filename+'_plot.png')
# save all keyframes as image将所有关键帧另存为图像
cap = cv2.VideoCapture(str(videopath))
curr_frame = None
keyframes = []
success, frame = cap.read()
idx = 0
while(success):
if idx in keyframe_id_set:
name = filename+'_' + str(idx) + ".jpg"
cv2.imwrite(dir + name, frame)
keyframe_id_set.remove(idx)
idx = idx + 1
success, frame = cap.read()
cap.release()
if __name__ == "__main__":
print(sys.executable)
#Video path of the source file源文件的视频路径
videopath= 'video/school.mp4'
#Directory to store the processed frames存储已处理帧的目录
dir = 'video/extract_result/'
getEffectiveFrame(videopath,dir)
效果:

(2)批量处理视频

# -*- coding: utf-8 -*-
import cv2
import os
import time
import operator # 内置操作符函数接口(后面排序用到)
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import argrelextrema # 极值点
def smooth(x, window_len=13, window='hanning'):
"""使用具有所需大小的窗口使数据平滑。
"""
print(len(x), window_len)
s = np.r_[2 * x[0] - x[window_len:1:-1],
x, 2 * x[-1] - x[-1:-window_len:-1]]
#print(len(s))
if window == 'flat': # moving average平移
w = np.ones(window_len, 'd')
else:
w = getattr(np, window)(window_len)
y = np.convolve(w / w.sum(), s, mode='same')
return y[window_len - 1:-window_len + 1]
class Frame:
"""用于保存有关每个帧的信息
"""
def __init__(self, id, diff):
self.id = id
self.diff = diff
def __lt__(self, other):
if self.id == other.id:
return self.id < other.id
return self.id < other.id
def __gt__(self, other):
return other.__lt__(self)
def __eq__(self, other):
return self.id == other.id and self.id == other.id
def __ne__(self, other):
return not self.__eq__(other)
def rel_change(a, b):
x = (b - a) / max(a, b)
print(x)
return x
def getEffectiveFrame(videopath,dirfile):
# 如果文件目录不存在则创建目录
if not os.path.exists(dirfile):
os.makedirs(dirfile)
(filepath, tempfilename) = os.path.split(videopath)#分离路径和文件名
(filename, extension) = os.path.splitext(tempfilename)#区分文件的名字和后缀
#Setting fixed threshold criteria设置固定阈值标准
USE_THRESH = False
#fixed threshold value固定阈值
THRESH = 0.6
#Setting fixed threshold criteria设置固定阈值标准
USE_TOP_ORDER = False
#Setting local maxima criteria设置局部最大值标准
USE_LOCAL_MAXIMA = True
#Number of top sorted frames排名最高的帧数
NUM_TOP_FRAMES = 50
#smoothing window size平滑窗口大小
len_window = int(50)
print("target video :" + videopath)
print("frame save directory: " + dirfile)
# load video and compute diff between frames加载视频并计算帧之间的差异
cap = cv2.VideoCapture(str(videopath))
curr_frame = None
prev_frame = None
frame_diffs = []
frames = []
success, frame = cap.read()
i = 0
while(success):
luv = cv2.cvtColor(frame, cv2.COLOR_BGR2LUV)
curr_frame = luv
if curr_frame is not None and prev_frame is not None:
#logic here
diff = cv2.absdiff(curr_frame, prev_frame)#获取差分图
diff_sum = np.sum(diff)
diff_sum_mean = diff_sum / (diff.shape[0] * diff.shape[1])#平均帧
frame_diffs.append(diff_sum_mean)
frame = Frame(i, diff_sum_mean)
frames.append(frame)
prev_frame = curr_frame
i = i + 1
success, frame = cap.read()
cap.release()
# compute keyframe
keyframe_id_set = set()
if USE_TOP_ORDER:
# sort the list in descending order以降序对列表进行排序
frames.sort(key=operator.attrgetter("diff"), reverse=True)# 排序operator.attrgetter
for keyframe in frames[:NUM_TOP_FRAMES]:
keyframe_id_set.add(keyframe.id)
if USE_THRESH:
print("Using Threshold")#使用阈值
for i in range(1, len(frames)):
if (rel_change(np.float(frames[i - 1].diff), np.float(frames[i].diff)) >= THRESH):
keyframe_id_set.add(frames[i].id)
if USE_LOCAL_MAXIMA:
print("Using Local Maxima")#使用局部极大值
diff_array = np.array(frame_diffs)
sm_diff_array = smooth(diff_array, len_window)#平滑
frame_indexes = np.asarray(argrelextrema(sm_diff_array, np.greater))[0]#找极值
for i in frame_indexes:
keyframe_id_set.add(frames[i - 1].id)# 记录极值帧数
plt.figure(figsize=(40, 20))
plt.locator_params("x", nbins = 100)
# stem 绘制离散函数,polt是连续函数
plt.stem(sm_diff_array,linefmt='-',markerfmt='o',basefmt='--',label='sm_diff_array')
plt.savefig(dirfile + filename+'_plot.png')
# save all keyframes as image将所有关键帧另存为图像
cap = cv2.VideoCapture(str(videopath))
curr_frame = None
keyframes = []
success, frame = cap.read()
idx = 0
while(success):
if idx in keyframe_id_set:
name = filename+'_' + str(idx) + ".jpg"
cv2.imwrite(dirfile + name, frame)
keyframe_id_set.remove(idx)
idx = idx + 1
success, frame = cap.read()
cap.release()
if __name__ == "__main__":
print("[INFO]Effective Frame.")
start = time.time()
videos_path= 'dataset/vedio/onehand/'
outfile = 'dataset/vedio/extract_result/'#处理完的帧
video_files = [os.path.join(videos_path, video_file) for video_file in os.listdir(videos_path)]
#
for video_file in video_files:
getEffectiveFrame(video_file,outfile)
print("[INFO]Extract Result time: ", time.time() - start)
(3)扩展
这是采用的第三种方法,在手语识别中适用性一般,存在的缺点:
-
提取出的关键帧数量较少,极准确特征手势表达不强

(增加除最高帧差点额外的点) -
间帧差别容易受极端帧影响
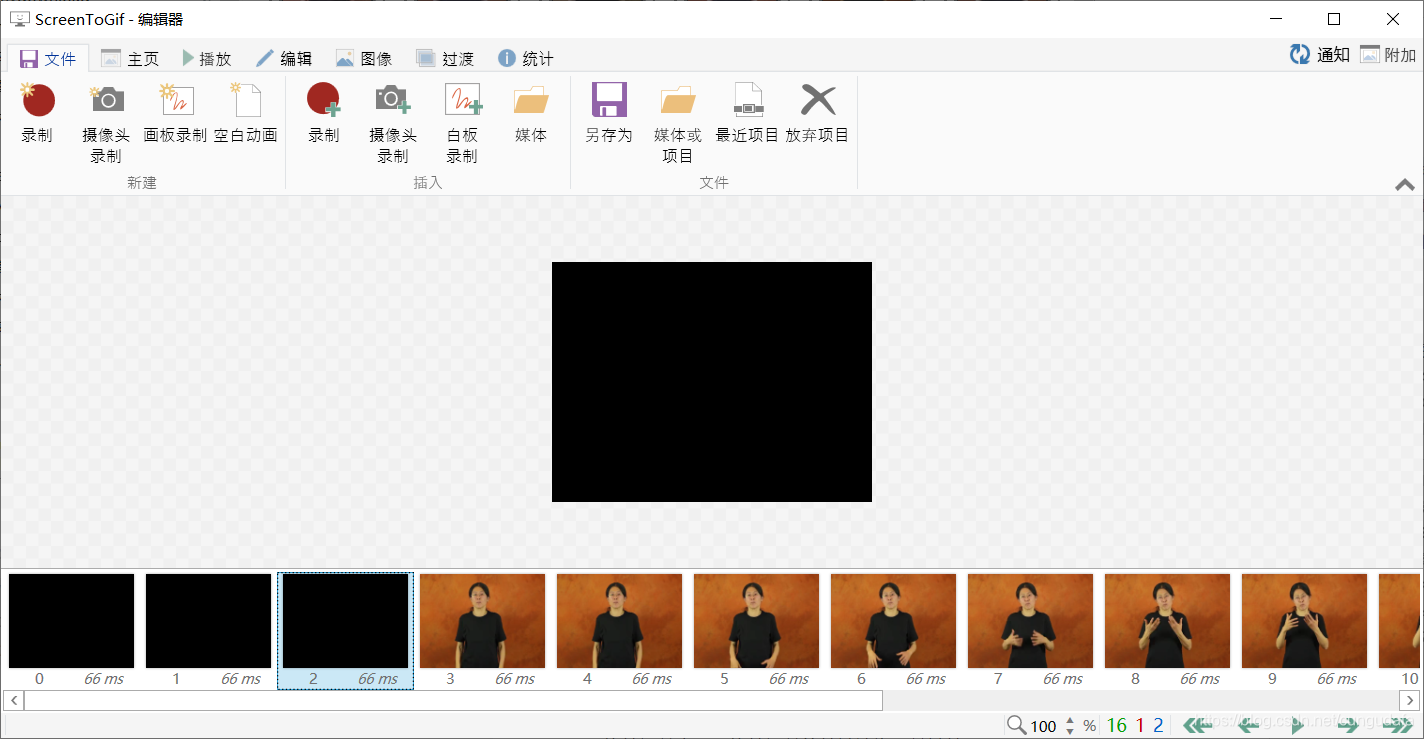
视频处理工具查看每一帧情况:(这段视频中前三帧有黑屏,导致平均帧差过大,提取不到关键帧。)
帧差曲线:(失真)

(对选取的视频要做处理,有极端帧要去除)
是否采用:
-
使用差值顺序
前几帧具有最大的帧间平均差被认为是关键帧。 -
使用差分阈值
平均帧间差大于平均帧间差的帧被认为是关键帧。
有待验证~
2.三间差分法
两间差分法:

三间差分法:

双目摄像机:

有一点难了,我还是等毕设partner的结果吧。
