系统总体设计
- 监控系统的移动端部署
- 图像关键内容的提取
- 数据传输加密
- 监控端与用户
- 身份认证身份认证
- 实时预警实时预警
- 获取监控关键信息获取监控关键信息
异常行为检测过程通常分为四个阶段:
- 初始化-通过初始化为整个系统处理采集到的图像数据:例如,建立一个合理的图像轮廓匹配系统模型
- 跟踪-从图像背景中分理出目标部分,并分析连续帧目标部分的相应关系
- 姿态-估计连续帧出现的姿态行为(通常,需要建立一个高级人的行为模型)姿态-估计连续帧出现的姿态行为(通常,需要建立一个高级人的行为模型)
- 识别-识别行为识别-识别行为
视频监控中的异常行为检测大致可以分为两种:
基于模型的异常行为检测方法和基于相似度的异常行为检测方法。
基于模型的异常行为检测方法,是基于某种准则,采用人为或半监督定义正常行为模型,而正常模型的定义是根据从视频图像序列中提取出来的运动,外形特征信息。如采用隐马尔可夫模型(Hidden Markov Model,HMM)统计或者图模型的对视频序列图像特征信息进行建模,如果检测的行为不匹配正常行为模型,则被视为异常行为。
基于相似度的异常模型检测方法,由于异常行为难以被发现和定义,所以无需显示定义行为模型就可以检测识别出异常行为。基于相似度量的异常行为检测原理是通过学习视频序列中正常行为模式,然后去推断有可能发生的异常行为。
运动目标的检测方法
常用的有:背景差分法、帧差法和光流法。
背景差分法
背景差分法是最常用的一种运动目标检测方法,其性能依赖于背景建模技术。背景差分法原理是将视频序列中的当前视频帧图像与背景建模获取到的背景图像做比较,来检测运动目标。
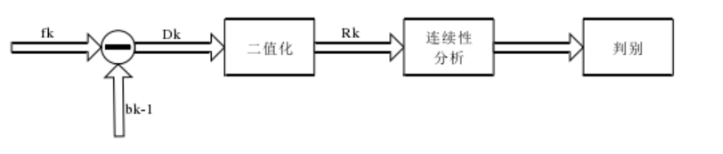
优点: 检测速度快,检测准确,易于实现。
缺点: 变化的检测场景中,背景更新的难度会增加,背景建模的模拟准确度将直接影响运动目标检测效果。
目前 背景建模的方法主要有以下四种:
(1) 中值法
中值法背景建模原理是读取一段连续N帧视频图像.并计算N帧视频阁像对应位罝像素值的中值,图像中每个位罝的像素中值即为背景阁像对应位罝的像素值。主要适用于一段时间内运动目标出现次数比较少的情况。
(2) 均值法
均值法背景建模基本思想是读取一段连续N帧视频阁像.并计算N帧视频阁像对应位罝 像素灰度值的平均值,即为背景图像对应位罝的像素灰度值。均值法的优点是算法速度快, 缺点是容易受到光照强度的变化和一些动态背景的影响。
(3) 混合高斯
浞合高斯背景建模对视频图像样本进行概率密度进行估计,而估计模型则是几个高斯模型的加权和。每一种高斯模型代表一类背景,因此,多个高斯模型混合使用就可以模拟出复杂场泉中的多模态情形.混合高斯模型的优点可以将复杂场景分解为若干个对应的高斯模型, 自适应性比较好,缺点是算法复杂度高,运行速度慢。
(4) 卡尔曼滤波器
卡尔曼滤波器背景建模原理是利用卡尔曼滤波器时域递归低通滤波原理来预测缓慢变化的背景图像,滤除噪声(前景图像)。卡尔按滤波器适用于比较稳定的场景。优点是可以利用前景图像进行背景更新,又可以通过维持背景的稳定性来消除噪声的干扰,缺点是不适用于动态变化的场景。
帧差法
帧差法是背景减闬法中的一种.只是帧差法不耑要建模.因为它的背#建模就是上一桢的图,所以速度非常快.另外帧差法对缓慢变化的光照强度不是很敏感,所以其具有一定的应用价值。目前帧差法主要分为两帧差分法和三帧差分法。
(1) 两帧差分法
两帧差分法的基本原理可以用下面公式表示:
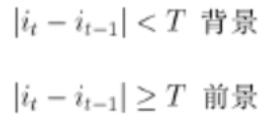
其中分别为t,t-1时刻对应像素点的像素值.T为阈值.当然其不足的地方也不少, 容易出现“空洞”和“双彩”现象。
(2) 三帧差分法
对子两帧差分法的“双影”现象,可以迎过采用三帧差分法来消除该现象.其实现过程如下图所示
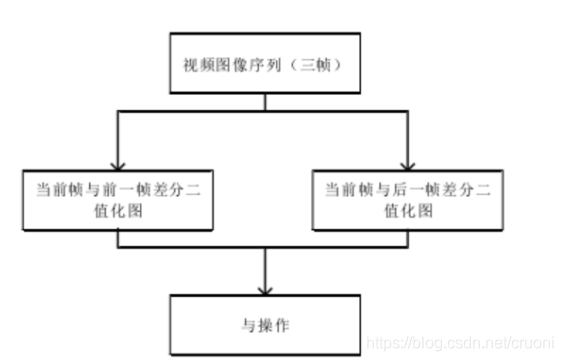
三帧差分法将两次相邻帧的查分二值化图像做与操作,使可以得到真正的那个前景图像。三桢差分法在一定程度上可以解决“双影”现象。但是得到运动内部区域容易出现空洞现象,不利于后续处理。

光流法
光流是一种图像亮点运动信息的特征,即图像灰度模式下的运动表现特征。而一般而言,光流特征信息是由于场景中相机和前景运动目标相对运动产生的。其计算方法可以分为三类:基于区域或者基于特征的匹配方法;基于频域的方法;基于梯度的方法;
光流法检测运动目标原理:
赋予图像中的每个像素点运动矢量,就可以形成一个运动矢量场,通过其对应关系计算公式便可以将图像中的像素点投影到三维物体上,然后通过像素点运动矢量特征进行动态分析。如果图像中不存在运动目标,则速度矢量在整个图像区域是连续变化的。当图像中存在运动物体时,背景和运动目标发生相对运动运动目标所形成的速度矢量一定和背景的速度矢量有所不同,因此可以计算出运动目标的位置信息。
光流法的基本公式:
光流场是物体的速度矢量场,包括两个分量u,v。设平面上有一点(x,y),其指的是场景中的某一点(x,y,z)在图像平面上的投影,该点在时刻t的灰度值为I(x,y,t)。假设该点在 t+△t时刻运动到位置(x+△x,y+△y),在很短的时间间隔△t内其灰度值保持不变,由此可以得到:

光流法既可以检测运动目标,也可以运动于目标跟踪。单身光流法比较复杂,无法保证检测实时性。
跟学长聊了一下午 搞懂了要实现的到底是个什么东西
后面进入基于openCV的关键帧提取算法的实现
OpenCV进行图像相似度对比的几种办法
直方图方法
方法描述:有两幅图像,分别计算两幅图像的直方图,并将直方图进行归一化,然后按照某种距离度量的标准进行相似度的测量。
方法的思想:基于简单的向量相似度来对图像相似度进行度量。
优点:直方图能够很好的归一化,比如256个bin条,那么即使是不同分辨率的图像都可以直接通过其直方图来计算相似度,计算量适中。比较适合描述难以自动分割的图像。
缺点:直方图反应的是图像灰度值得概率分布,并没有图像的空间位置信息在里面,因此,常常出现误判;从信息论来讲,通过直方图转换,信息丢失量较大,因此单一的通过直方图进行匹配显得有点力不从心。
图像模板匹配
一般而言,源图像与模板图像patch尺寸一样的话,可以直接使用上面介绍的图像相似度测量的方法;如果源图像与模板图像尺寸不一样,通常需要进行滑动匹配窗口,扫面个整幅图像获得最好的匹配patch。
在OpenCV中对应的函数为:matchTemplate():函数功能是在输入图像中滑动窗口寻找各个位置与模板图像patch的相似度。
PSNR峰值信噪比
PSNR(Peak Signal to Noise Ratio),一种全参考的图像质量评价指标。
简介:https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio
PSNR是最普遍和使用最为广泛的一种图像客观评价指标,然而它是基于对应像素点间的误差,即基于误差敏感的图像质量评价。由于并未考虑到人眼的视觉特性(人眼对空间频率较低的对比差异敏感度较高,人眼对亮度对比差异的敏感度较色度高,人眼对一个区域的感知结果会受到其周围邻近区域的影响等),因而经常出现评价结果与人的主观感觉不一致的情况。
SSIM(structural similarity)结构相似性
也是一种全参考的图像质量评价指标,它分别从亮度、对比度、结构三方面度量图像相似性。
SSIM取值范围[0,1],值越大,表示图像失真越小.
在实际应用中,可以利用滑动窗将图像分块,令分块总数为N,考虑到窗口形状对分块的影响,采用高斯加权计算每一窗口的均值、方差以及协方差,然后计算对应块的结构相似度SSIM,最后将平均值作为两图像的结构相似性度量,即平均结构相似性MSSIM:
感知哈希算法
感知哈希算法(perceptual hash algorithm),它的作用是对每张图像生成一个“指纹”(fingerprint)字符串,然后比较不同图像的指纹。结果越接近,就说明图像越相似。
实现步骤:
缩小尺寸:将图像缩小到8*8的尺寸,总共64个像素。这一步的作用是去除图像的细节,只保留结构/明暗等基本信息,摒弃不同尺寸/比例带来的图像差异;
简化色彩:将缩小后的图像,转为64级灰度,即所有像素点总共只有64种颜色;
计算平均值:计算所有64个像素的灰度平均值;
比较像素的灰度:将每个像素的灰度,与平均值进行比较,大于或等于平均值记为1,小于平均值记为0;
计算哈希值:将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图像的指纹。组合的次序并不重要,只要保证所有图像都采用同样次序就行了;
得到指纹以后,就可以对比不同的图像,看看64位中有多少位是不一样的。在理论上,这等同于”汉明距离”(Hamming distance,在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数)。如果不相同的数据位数不超过5,就说明两张图像很相似;如果大于10,就说明这是两张不同的图像。
感知哈希算法的实现
[C#](https://www.cnblogs.com/technology/archive/2012/07/12/2588022.html)
[openCV] (https://blog.csdn.net/fengbingchun/article/details/42153261)
关于后续openCV的学习和算法的实现与改进我会在博客上更新
至于github。整个视频项目是团队努力的成果 并不属于我个人 所以这个项目暂时不会在放到github上面