Oracle可以通过OGG for Bigdata将Oracle数据库数据实时增量同步至hadoop平台(kafka,hdfs等)进行消费,笔者搭建这个环境的目的是将Oracle数据库表通过OGG同步到kafka来提供给flink做流计算。具体的实施文档已经在之前的文章中写了,这里只给出连接:
OGG实时同步Oracle数据到Kafka实施文档(供flink流式计算)
这篇文章主要介绍的是:
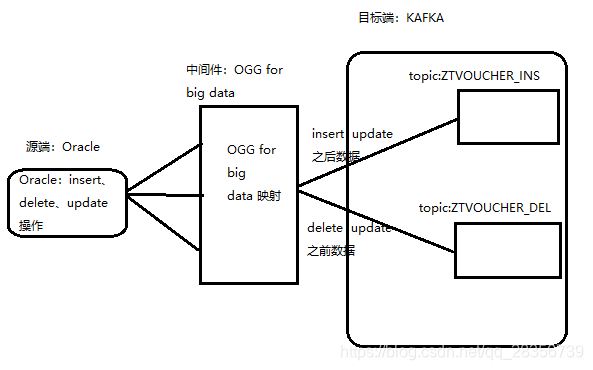
Oracle如何通过OGG for Bigdata将数据变更操作(insert、delete、update)分别投递至各自类型(insert、delete)的topic中,之所以只有insert和delete两个类型的topic,是因为笔者将update操作分解为insert、delete操作,并分别投递至属于insert、delete操作类型的topic中,具体映射关系可以看本人所画下图直观了解:
接下来看具体的配置,现在实验操作的所有环境是基于上面给出的本人写的安装文档对应的环境进行的配置修改:
一、源端配置修改
修改抽取进程E_ZT配置:
extract e_zt
userid ogg,password ogg
setenv(NLS_LANG=AMERICAN_AMERICA.AL32UTF8)
setenv(ORACLE_SID="orcl")
reportcount every 30 minutes,rate
numfiles 5000
discardfile ./dirrpt/e_zt.dsc,append,megabytes 1000
warnlongtrans 2h,checkinterval 30m
exttrail ./dirdat/zt
dboptions allowunusedcolumn
tranlogoptions archivedlogonly
tranlogoptions altarchivelogdest primary /u01/arch
dynamicresolution
fetchoptions nousesnapshot
ddl include mapped
ddloptions addtrandata,report
notcpsourcetimer
NOCOMPRESSDELETES
NOCOMPRESSUPDATES
GETUPDATEBEFORES
----------SCOTT.ZTVOUCHER
table SCOTT.ZTVOUCHER,keycols(MANDT,GJAHR,BUKRS,BELNR,BUZEI,MONAT,BUDAT),tokens(
TKN-OP-TYPE = @GETENV ('GGHEADER', 'OPTYPE')
);
修改配置后执行stop e_zt以及start e_zt命令重启抽取进程
上面同步的表ZTVOUCHER结构如下:
create table ZTVOUCHER
(
mandt VARCHAR2(9),
gjahr VARCHAR2(12),
bukrs VARCHAR2(12),
belnr VARCHAR2(30),
buzei VARCHAR2(9),
monat VARCHAR2(6),
budat VARCHAR2(24),
hkont VARCHAR2(30),
dmbtr NUMBER(13,2),
zz0014 VARCHAR2(9)
)
没有物理主键,逻辑主键MANDT,GJAHR,BUKRS,BELNR,BUZEI,MONAT,BUDAT,加了全列的附加日志(刚刚所说所有操作,上面给出的实时文档有相关类似操作)。至于我为什么要在配置中给表多加TKN-OP-TYPE属性,后面有解释,带着疑问继续往下看。
二、目标端配置修改
1、应用进程rkafka配置文件rkafka.prm修改:
REPLICAT rkafka
-- Trail file for this example is located in "AdapterExamples/trail" directory
-- Command to add REPLICAT
-- add replicat rkafka, exttrail AdapterExamples/trail/tr
TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props
REPORTCOUNT EVERY 1 MINUTES, RATE
allowduptargetmap
GROUPTRANSOPS 10000
IGNOREUPDATEBEFORES
IGNOREDELETES
IGNOREINSERTS
GETUPDATEAFTERS
INSERTUPDATES
MAP SCOTT.ZTVOUCHER, TARGET SCOTT.ZTVOUCHER_INS;
GETUPDATEBEFORES
IGNOREUPDATEAFTERS
IGNOREDELETES
IGNOREINSERTS
INSERTUPDATES
MAP SCOTT.ZTVOUCHER, TARGET SCOTT.ZTVOUCHER_DEL;
NOINSERTUPDATES
GETINSERTS
IGNOREDELETES
IGNOREUPDATES
MAP SCOTT.ZTVOUCHER, TARGET SCOTT.ZTVOUCHER_INS;
IGNOREUPDATES
IGNOREINSERTS
GETDELETES
INSERTDELETES
MAP SCOTT.ZTVOUCHER, TARGET SCOTT.ZTVOUCHER_DEL;
2、custom_kafka_producer.properties配置
[root@hadoop dirprm]# cat custom_kafka_producer.properties
bootstrap.servers=192.168.1.66:9092
acks=1
reconnect.backoff.ms=1000
value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
# 100KB per partition
batch.size=102400
linger.ms=10000
3、kafka.props 配置
[root@hadoop dirprm]# cat kafka.props
gg.handlerlist = kafkahandler
gg.handler.kafkahandler.type=kafka
gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties
#The following resolves the topic name using the short table name
#gg.handler.kafkahandler.topicMappingTemplate=ztvoucher
gg.handler.kafkahandler.topicMappingTemplate=${tableName}
#The following selects the message key using the concatenated primary keys
gg.handler.kafkahandler.keyMappingTemplate=${primaryKeys}
gg.handler.kafkahandler.format=json
gg.handler.kafkahandler.SchemaTopicName=scott
gg.handler.kafkahandler.BlockingSend =true
gg.handler.kafkahandler.includeTokens=false
gg.handler.kafkahandler.mode=op
gg.handler.kafkahandler.includeTokens = true
goldengate.userexit.writers=javawriter
javawriter.stats.display=TRUE
javawriter.stats.full=TRUE
gg.log=log4j
gg.log.level=INFO
gg.report.time=30sec
#Sample gg.classpath for Apache Kafka
gg.classpath=dirprm/:/hadoop/kafka/libs/*:/hadoop/ogg12/:/hadoop/ogg12/lib/*
#Sample gg.classpath for HDP
#gg.classpath=/etc/kafka/conf:/usr/hdp/current/kafka-broker/libs/*
javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar
执行 stop rkafka 及 start rkafka 重启应用进程rkafka
三、实验及总结
这里通过实验来解释之前说的为什么抽取进程添加TKN-OP-TYPE及应用进程rkafka为什么那么配置。
0、先来看下当前kafka有哪些topic:
[root@hadoop kafka]# bin/kafka-topics.sh -describe -zookeeper 192.168.1.66:2181
Topic:kylin_streaming_topic PartitionCount:1 ReplicationFactor:1 Configs:
Topic: kylin_streaming_topic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:scott PartitionCount:1 ReplicationFactor:1 Configs:
Topic: scott Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:zttest PartitionCount:1 ReplicationFactor:1 Configs:
Topic: zttest Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:ztvoucher PartitionCount:1 ReplicationFactor:1 Configs:
Topic: ztvoucher Partition: 0 Leader: 0 Replicas: 0 Isr: 0
1、源端insert 一条数据:
insert into ztvoucher (MANDT, GJAHR, BUKRS, BELNR, BUZEI, MONAT, BUDAT, HKONT, DMBTR, ZZ0014)
values ('666', '2222', '3432', '2200001414', '001', '01', '20190101', '9101000000', 410600.00, '101');
commit;
源端切换归档:
SQL> alter system switch logfile;
System altered.
SQL> /
System altered.
2、目的端查看:
先看下进程状态,没问题:
GGSCI (hadoop) 2> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
REPLICAT RUNNING RKAFKA 00:00:00 00:00:05
GGSCI (hadoop) 3> info rkafka
REPLICAT RKAFKA Last Started 2019-05-21 10:42 Status RUNNING
Checkpoint Lag 00:00:00 (updated 00:00:07 ago)
Process ID 34591
Log Read Checkpoint File /hadoop/ogg12/dirdat/zt000000008
2019-05-21 12:45:34.414959 RBA 7230
因为是做的插入操作,所以从应用进程的配置看,我们这时候应该去kafka的ztvoucher_ins 的topic看ogg是否已经把数据以json格式投递到kafka了,但是前面第0步看了,目前kafka中没有名为ztvoucher_ins的topic,但是由于之前配置了如果没有相应topic就会自动创建,创建名称规则为gg.handler.kafkahandler.topicMappingTemplate=${tableName},也就是rkaffka.prm中配置的映射ZTVOUCHER_DEL,ZTVOUCHER_INS这两个topic。
这时再看下当前kafka中topic清单:
[root@hadoop kafka]# pwd
/hadoop/kafka
[root@hadoop kafka]# bin/kafka-topics.sh -describe -zookeeper 192.168.1.66:2181
Topic:ZTVOUCHER_INS PartitionCount:1 ReplicationFactor:1 Configs:
Topic: ZTVOUCHER_INS Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:kylin_streaming_topic PartitionCount:1 ReplicationFactor:1 Configs:
Topic: kylin_streaming_topic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:scott PartitionCount:1 ReplicationFactor:1 Configs:
Topic: scott Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:zttest PartitionCount:1 ReplicationFactor:1 Configs:
Topic: zttest Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:ztvoucher PartitionCount:1 ReplicationFactor:1 Configs:
Topic: ztvoucher Partition: 0 Leader: 0 Replicas: 0 Isr: 0
发现已经自动创建了名为ZTVOUCHER_INS的topic,看下topic的内容:
[root@hadoop kafka]# ./console.sh
input topic:ZTVOUCHER_INS
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper]
.{"table":"SCOTT.ZTVOUCHER_INS","op_type":"I","op_ts":"2019-05-21 13:50:29.000732","current_ts":"2019-05-21T13:50:38.891000","pos":"00000000080000007490","tokens":{"TKN-OP-TYPE":"INSERT"},"a
fter":{"MANDT":"666","GJAHR":"2222","BUKRS":"3432","BELNR":"2200001414","BUZEI":"001","MONAT":"01","BUDAT":"20190101","HKONT":"9101000000","DMBTR":410600.00,"ZZ0014":"101"}}
上面的console.sh 脚本封装命令内容:
#!/bin/bash
read -p "input topic:" name
bin/kafka-console-consumer.sh --zookeeper 192.168.1.66:2181 --topic $name --from-beginning
通过前面查看的topic内容可以看到,json数据主要是由table、op_type、op_ts、tokens、after几部分内容组成,table 即为发生dml操作的表,op_type为做的操作类型(I代表insert,D代表delete,U代表update),op_ts代表事务发生时间,是一个timestamp类型的数据,tokens为我前面抽取进程配置的再次获取当前操作类型的属性,after代表插入的数据。
3、源端update数据
select * from ztvoucher where mandt='666'
MANDT GJAHR BUKRS BELNR BUZEI MONAT BUDAT HKONT DMBTR ZZ0014
666 2222 3432 2200001414 001 01 20190101 9101000000 410600.00 101
update ztvoucher set dmbtr=8762 where mandt='666';
commit;
切换归档:
SQL> alter system switch logfile;
System altered.
SQL> /
System altered.
接下来再看下当前kafka有哪些主题:
[root@hadoop kafka]# ./list.sh
Topic:ZTVOUCHER_DEL PartitionCount:1 ReplicationFactor:1 Configs:
Topic: ZTVOUCHER_DEL Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:ZTVOUCHER_INS PartitionCount:1 ReplicationFactor:1 Configs:
Topic: ZTVOUCHER_INS Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:kylin_streaming_topic PartitionCount:1 ReplicationFactor:1 Configs:
Topic: kylin_streaming_topic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:scott PartitionCount:1 ReplicationFactor:1 Configs:
Topic: scott Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:zttest PartitionCount:1 ReplicationFactor:1 Configs:
Topic: zttest Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:ztvoucher PartitionCount:1 ReplicationFactor:1 Configs:
Topic: ztvoucher Partition: 0 Leader: 0 Replicas: 0 Isr: 0
list.sh里面封装的命令:
#!/bin/bash
bin/kafka-topics.sh -describe -zookeeper 192.168.1.66:2181
从上面list.sh脚本的结果来看,现在多了个topic:ZTVOUCHER_DEL,再去看ZTVOUCHER_INS和DEL两个topic中的消息:
[root@hadoop kafka]# ./console.sh
input topic:ZTVOUCHER_INS
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper]
.{"table":"SCOTT.ZTVOUCHER_INS","op_type":"I","op_ts":"2019-05-21 13:50:29.000732","current_ts":"2019-05-21T13:50:38.891000","pos":"00000000080000007490","tokens":{"TKN-OP-TYPE":"INSERT"},"a
fter":{"MANDT":"666","GJAHR":"2222","BUKRS":"3432","BELNR":"2200001414","BUZEI":"001","MONAT":"01","BUDAT":"20190101","HKONT":"9101000000","DMBTR":410600.00,"ZZ0014":"101"}}{"table":"SCOTT.ZTVOUCHER_INS","op_type":"I","op_ts":"2019-05-21 15:49:22.001876","current_ts":"2019-05-21T15:50:11.841000","pos":"00000000080000008018","tokens":{"TKN-OP-TYPE":"SQL COMPUPD
ATE"},"after":{"MANDT":"666","GJAHR":"2222","BUKRS":"3432","BELNR":"2200001414","BUZEI":"001","MONAT":"01","BUDAT":"20190101","HKONT":"9101000000","DMBTR":8762.00,"ZZ0014":"101"}}
从上面看到,现在topic:ZTVOUCHER_INS中多了一条消息,消息内容为update之后的数据,从哪里看出来的呢,看TKN-OP-TYPE:SQL COMPUPDATE,这个前面说了是记录源端事务操作类型,从这点能说明这个数据是从udpate操作拆分映射过来的,为什么说是update之后而不是之前的呢,一开始就说了,我这里把update之后的数据映射到ZTVOUCHER_INS中,看另一个topic:
[root@hadoop kafka]# ./console.sh
input topic:ZTVOUCHER_DEL
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper]
.{"table":"SCOTT.ZTVOUCHER_DEL","op_type":"I","op_ts":"2019-05-21 15:49:22.001876","current_ts":"2019-05-21T15:49:51.671000","pos":"00000000080000007750","tokens":{"TKN-OP-TYPE":"SQL COMPUPD
ATE"},"after":{"MANDT":"666","GJAHR":"2222","BUKRS":"3432","BELNR":"2200001414","BUZEI":"001","MONAT":"01","BUDAT":"20190101","HKONT":"9101000000","DMBTR":410600.00,"ZZ0014":"101"}}
根据前面的逻辑,这里来看下这个json,从TKN-OP-TYPE":“SQL COMPUPDATE"看出来这是从update拆分出来的,,看上面两个topic关于update的json的"op_type”:“I”,为什么insert和delete的两个topic对应的optype都是I,这个是因为我把update拆分为insert,delete时,全部映射为insert然后投递到kafka,至于为什么,来看下从update json 中拆分出的不转insert 的update before j’son数据:
{"table":"SCOTT.ZTVOUCHER_INS","op_type":"I","op_ts":"2019-05-21 15:49:22.001876","current_ts":"2019-05-21T15:50:11.841000","pos":"00000000080000008018","tokens":{"TKN-OP-TYPE":"SQL COMPUPD
ATE"},"before":{"MANDT":"666","GJAHR":"2222","BUKRS":"3432","BELNR":"2200001414","BUZEI":"001","MONAT":"01","BUDAT":"20190101","HKONT":"9101000000","DMBTR":8762.00,"ZZ0014":"101"},"after":{}}
如果把这个数据直接投递到del的topic中,我们会发现,和正常的insert,delete json相比,update多出了after或则before的字段,虽然内容为空,但是update的json和insert,delete的格式就不一致了,在kylin构建流cube或flink构建流表时需要编写额外代码去处理,所以我这里通过转换拆分后的update before或after操作为insert分别投递到各自topic能有效在投递的过程中处理并规范化json数据。而且在后续开发中,配置的这类j’son格式数据不仅能够通过op_ts字段做增量时间分割字段,而且两个tpoic中的json格式都一致,均为after存储关键数据,还能能够通过tokens和optype从topic中识别出哪些数据是update拆分的数据。
最后再来看下delete数据的json,与上面描述一致:
源端删除数据:
delete from ztvoucher where mandt='666';
commit;
切换归档:
alter system switch logfile;
看下ZTVOUCHER_DEL topic内容:
[root@hadoop kafka]# ./console.sh
input topic:ZTVOUCHER_DEL
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper]
.{"table":"SCOTT.ZTVOUCHER_DEL","op_type":"I","op_ts":"2019-05-21 15:49:22.001876","current_ts":"2019-05-21T15:49:51.671000","pos":"00000000080000007750","tokens":{"TKN-OP-TYPE":"SQL COMPUPD
ATE"},"after":{"MANDT":"666","GJAHR":"2222","BUKRS":"3432","BELNR":"2200001414","BUZEI":"001","MONAT":"01","BUDAT":"20190101","HKONT":"9101000000","DMBTR":410600.00,"ZZ0014":"101"}}{"table":"SCOTT.ZTVOUCHER_DEL","op_type":"I","op_ts":"2019-05-21 16:34:19.002395","current_ts":"2019-05-21T16:36:43.769000","pos":"00000000080000008262","tokens":{"TKN-OP-TYPE":"DELETE"},"a
fter":{"MANDT":"666","GJAHR":"2222","BUKRS":"3432","BELNR":"2200001414","BUZEI":"001","MONAT":"01","BUDAT":"20190101","HKONT":"9101000000","DMBTR":8762.00,"ZZ0014":"101"}}
看最后一条j’son就是删除对应的json,op_type还是I,因为做了转insert操作,因为delete的数据不转insert的话,拆分的update before投递到DEL topic的json中,是做了转换的,after中才有数据,而delete不转insert的话,是before有数,结构就不一致了,所以为了保持两个topic的j’son格式一致,delete也做了insert转换。
