Scala
一、概述
Scala用一种简洁的高级语言将 面向对象 和 函数式编程 结合在一起。
领域模型设计--------------面向对象开发设计的核心
数据集计算模型----------大数据开发的核心
Scala是一门多范式的编程语言,同时支持面向对象和面向函数编程风格。它以一种优雅的方式解决现实问题。虽然它是强静态类型的编程语言,但是它强大的类型推断能力,使其看起来就像是一个动态编程语言一样。Scala语言最终会被翻译成java字节码文件,可以无缝的和JVM集成,并且可以使用Scala调用java的代码库。除了Scala编程语言自身的特性以外,目前比较流行的Spark计算框架也是使用Scala语言编写。Spark 和 Scala 能够紧密集成,例如 使用Scala语言操作大数据集合的时候,用户可以像是在操作本地数据集那样简单操作Spark上的分布式数据集-RDD(这个概念是Spark 批处理的核心术语),继而简化大数据集的处理难度,简化开发步骤。
资料参考:https://docs.scala-lang.org/tour/tour-of-scala.html
二、安装及配置
https://www.scala-lang.org/download/2.11.12.html
① windows安装:下载msi文件,直接安装。
配置环境变量:
SCALA_HOME=C:\Program Files (x86)\scala
PATH=C:\Program Files (x86)\scala/bin;
安装测试: cmd 窗口,输入 scala,出现提示,即安装完成。
② Linux 安装: 下载rpm文件,解压安装、
rpm -ivh scala-2.11.12.rpm
同时在 .bashrc中,或者/etc/profile中,配置环境变量。
安装测试:键入 scala,出现提示,即安装成功。
☆☆☆ IDEA 集成开发环境
在File>Setting>Plugins点击 install pluginfromdisk选项,搜索scala插件,安装成功后,重启IDEA。
三、数据
①.数据类型
在scala中一切皆对象,但是没有原始数据类型。
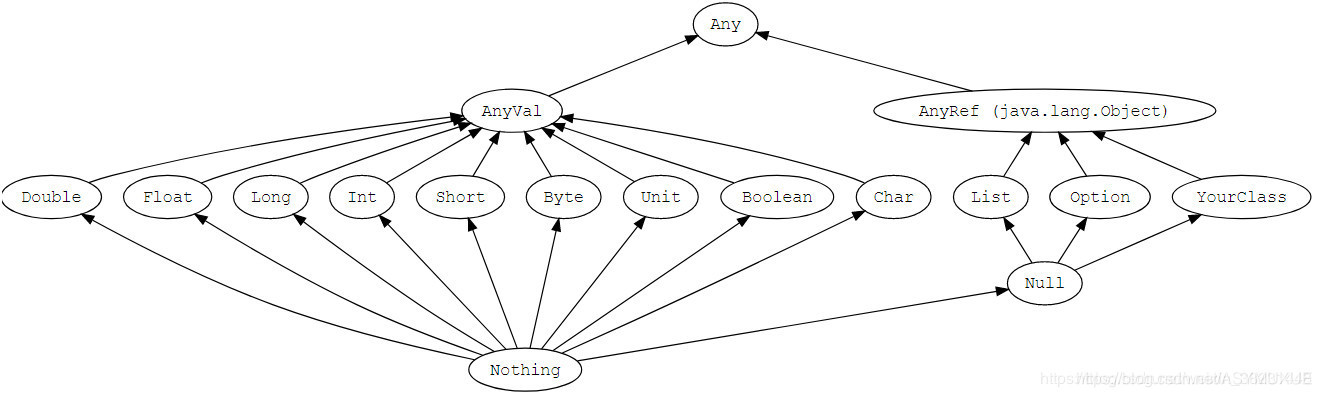
所有的数值变量类型都是 AnyVal的子类,这些变量的值都有字面值。
对于一些对象类型的变量都是 AnyRef的子类。对于 AnyRef类下的变量(除String类型),一般不允许直接赋值字面量,都需要借助 new关键创建。
②.变量声明
var 变量名:数据类型(可省略) = 值:数据类型(可省略)
Scala语言是一种可以做类型自动推断的强类型的编程语言。变量的类型可通过编译器在编译的时候推断出最终类型。因此Scala中声明一个变量主需要告知编译器该变量的值是常量还是变量,例如:例如声明一个变量使用var即可,如果声明的是一个常量使用val关键字。
var i =1 // Int
var j = 1:Byte // Byte
var b = true //Boolean
var name = "zs" //String
var c = 'a' // Char
③.数值转换 ★
1.符合java的数据转换规则,低精度向高精度转换
scala> var a = 1
a: Int = 1
scala> var b= 2:Byte
b: Byte = 2
//将 Byte 类型 赋值给 Int 类型
scala> a=b
a: Int = 2
2.高精度向低精度转换,借助于 asInstanceOf [ 低精度类型 ]
scala> var f1 = 2.0f
f1: Float = 2.0
scala> var d1 = 3.0
d1: Double = 3.0
scala> f1 = d1.asInstanceOf[Float]
f1: Float = 3.0
3.String 转换为任意val类型 ★
使用to类型关键字
scala> var s1 = "234"
s1: String = 234
scala> var d2 = 2.0
d2: Double = 2.0
scala> d2=s1.toDouble
d2: Double = 234.0
④.数组
//定义一个空数组
scala> var a=new Array[Int](5)
a: Array[Int] = Array(0, 0, 0, 0, 0)
//定义一个有数据的数组
scala> var a=Array(1,2,3,4,5)
a: Array[Int] = Array(1, 2, 3, 4, 5)
//获取任一元素
scala> a(1)
res0: Int = 2
scala> a(0)
res1: Int = 1
//改变某一个数值
scala> a(0)= -1
//展示数组
scala> a
res3: Array[Int] = Array(-1, 2, 3, 4, 5)
//数组长度
scala> a.length
res4: Int = 5
//数组尺寸
scala> a.size
res5: Int = 5
☆☆☆数组的遍历(to包含最后,until不包含最后的元素)
//第一种,使用下标遍历
var array1 = (3,4,1,2)
for (i <- 0 to array1.length-1){
println(array1(i))
}
//第二种,使用元素直接遍历
var arg1 = Array(5,3,8,7)
for(i <- arg1) println(s"参数是$i")
//第三种*
var array1 = (3,4,1,2)
array1.foreach(item => println(item))
⑤.元祖 ★
元组是在Scala编程语言中的一种特殊变量,该变量可以组合任意几种类型的变量,构建一个只读的变量类型。访问元组的成员可以使用_元素下标访问。
scala> var yuanzu = (1,"zyl",true,2999.9f)
yuanzu: (Int, String, Boolean, Float) = (1,zyl,true,2999.9)
scala> yuanzu._1
res0: Int = 1
scala> yuanzu._2
res1: String = zyl
scala> yuanzu._3
res2: Boolean = true
scala> yuanzu._4
res3: Float = 2999.9
⑥.Unit 类型
Scala 中用void作为保留关键字,使用 Unit 作为 void 替换,在 scala 中,Unit 表示什么也没有。
scala> var null1 = ()
null1: Unit = ()
scala> null1
四、分支循环
①.if 条件分支 ( java)
if(条件){
...
}else if(条件){
...
}else{
...
}
scala> var age=35
age: Int = 35
scala> if(age<18){
| print(s"归来是少年,你的年龄:${age}")
| }else if(age<30){
| println(s"正是奋斗时青年,你的年龄:${age}")
| }else{
| println(s"趋于安稳的中年,你的年龄:${age}")
| }
趋于安稳的中年,你的年龄:35
在Scala语法中if分支可以作为变量的赋值语句。可以将分支中返回的结果作为返回值,在利用分支做赋值的时候,不可以给return关键字,系统会自动将代码块最后一行的结果作为返回值。
②.while/do-while(java)
while(条件){
...
}
打印九九乘法表
scala> var i=1
i: Int = 1
scala> while (i <= 9){
| var j=1;
| while (j<=i){
| if(j<i){
| print(s"$i*$j="+(i*j)+"\t")
| }else{
| println(s"$i*$j="+(i*j)+"\t")
| }
| j +=1
| }
| i +=1
| }
1*1=1
2*1=2 2*2=4
3*1=3 3*2=6 3*3=9
4*1=4 4*2=8 4*3=12 4*4=16
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25
6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36
7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49
8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64
9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
③.Break
Scala 语言中默认是没有 break 语句,但是在 Scala 2.8 版本后可以使用另外一种方式来实现 break 语句。当在循环中使用 break 语句,在执行到该语句时,就会中断循环并执行循环体之后的代码块。
//导包
import scala.util.control.Breaks
//break 的使用
val break = new Breaks //①
break.breakable( //②
for (i<-0 to 10){
if(i==5){
break.break() //③
}
println(s"$i\t")
}
)*
③.for循环 ★
//九九乘法表
for(i <- 1 to 9;j <- 1 to i){
print(s"$i*$j="+(i*j)+"\t")
if(i==j){
println()
}
}
//带条件的for循环
for(i<- 1 to 10;if(i%2==0)){
println(s"$i 是一个偶数")
}
//yield 的使用
var arr1 = Array(3,7,6,9)
var arr2 = for(i <- arr1) yield i*i
for(i<-arr2){
print(s"$i\t")
}
五、模式、数值匹配
根据参数值做匹配,如果匹配到对应的值,则返回对应的值,其中_表示默认匹配。
//match...case
var arr = Array(3,4,5,6)
var num = arr(new Random().nextInt(4))
var res = num match {
case 3 => "第一个元素"
case 4 => "第二个元素"
case 5 => "第三个元素"
case default => "最终元素"
}
println(res)
println(arr(3))
//match...case 2
for(i <- 0 to 10){
var struct1 = Array(1,"zyl",true,new Date())
var rand = struct1(new Random().nextInt(4))
var result = rand match {
case x:Int => s"id$x"
case x:String => s"name$x"
case x:Boolean => s"sex$x"
case _ => s"什么都不是"
}
println(s"这是第$i 次计算 $result")
}
六、=> 的使用场景
原文链接:https://blog.csdn.net/someInNeed/article/details/90047624
①.表示函数的返回类型(Function Type)
(x: Int) => Int 或者 Int => Int。左边是参数类型,右边是方法返回值类型。
②.匿名函数
匿名函数定义,=>左边是参数 右边是函数实现体 (x: Int)=>{}
③.case语句
在模式匹配 match 和 try-catch 都用 “=>” 表示输出的结果或返回的值
④.By-Name Parameters(传名参数)
传名参数在函数调用前表达式不会被求值,而是会被包裹成一个匿名函数作为函数参数传递下去,例如参数类型为无参函数的参数就是传名参数。
//函数double
scala> def doubles(x: => Int) = {
println("Now doubling " + x)
x*2
}
doubles: (x: => Int)Int
//调用函数
scala> doubles(3)
Now doubling 3
res2: Int = 6
scala> def f(x: Int): Int = {
println(s"Calling f($x)")
x+1
}
f: (x: Int)Int
//调用函数
scala> doubles(f(3))
Calling f(3)
Now doubling 3
Calling f(3)
res9: Int = 8
对于函数doubles而言,它的参数x就是by-name的。如果调用doubles的时候,直接给个普通的值或者非函数变量。那么doubles的执行结果就跟普通的函数没有区别。但是当把一个返回值为Int类型的函数,例如f(2),传递给doubles的时候。那么f(2)会被先计算出返回值3,返回值3传入doubles参与运算。运算完成以后得8,f(2)会被doubles在执行以后,再调用一遍。
七、函数 ★
函数声明:
def 函数名(参数:类型,参数2:类型,....): 返回值类型 ={ 方法实现 }
①.标准函数
scala> def sum1(x:Int,y:Int):Int={x+y}
sum1: (x: Int, y: Int)Int
scala> sum1(3,4)
res0: Int = 7
//可以省略 `return` 关键字,及 返回值类型
scala> def sum1(x:Int,y:Int)={x*y}
sum1: (x: Int, y: Int)Int
scala> sum1(2,3)
res1: Int = 6
②.可变长参数
在参数类型后使用 * 标识可变长参数
scala> def sum1(x:Int*) = {
| var sum = 0
| for(i <- x){
| sum = sum +i
| }
| sum
| }
sum1: (x: Int*)Int
scala> sum1(1,2,3,4,5)
res3: Int = 15
//本身可变长参数是一种数组,因此可以使用 数组的函数
scala> def sum1(x:Int*)= {
| x.sum
| }
sum1: (x: Int*)Int
scala> sum1(1,2,3,4,5)
res3: Int = 15
③.命名参数
可以在返回值中给出参数的 参数名 信息
scala> def mes(name:String,tip:String) = {
| println(s"${tip}----${name}")
| }
mes: (name: String, tip: String)Unit
scala> mes("zyl","hello")
hello----zyl
scala> mes("hello","zyl")
zyl----hello
scala> mes(tip="hello",name="zyl")
hello----zyl
④.默认值参数
返回值中显示已给定的参数的默认值,也可以自己赋值,改变默认值。
scala> def mes(name:String,tip:String="hi"){
| println(s"${name},${tip}")
| }
mes: (name: String, tip: String)Unit
scala> mes("zyl")
zyl,hi
scala> mes(name="zyl")
zyl,hi
scala> mes("zyl","hello")
zyl,hello
scala> mes(name="zyl",tip="exec")
zyl,exec
⑤.内嵌函数
一个函数内部嵌套另一个函数,内部函数的返回值类型需要给出
scala> def factorial(x:Int) = {
| def mul(y:Int):Int={
| if(y>1){
| y*mul(y-1)
| }
| else{
| 1
| }
| }
| mul(x)
| }
factorial: (x: Int)Int
scala> factorial(5)
res12: Int = 120
⑥.柯里化 ★
在计算机科学中,柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数的函数,并且返回接受余下的参数且返回结果的新函数的技术。
scala> def sum(x:Int)(y:Int)={
| x+y
| }
sum: (x: Int)(y: Int)Int
scala> sum(1)(2)
res13: Int = 3
scala> sum(1)(_)
res14: Int => Int = <function1>
scala> res14(5)
res15: Int = 6
//可以不给任何实参 以函数名 _ 组成
scala> var res = sum _
res: Int => (Int => Int) = <function1>
scala> res(2)
res17: Int => Int = <function1>
scala> res17(5)
res18: Int = 7
⑦.匿名函数 ★
(x:Int,y:Int) => {x+y}箭头左边是参数列表,右边是函数体。使用匿名函数后,我们的代码变得更简洁了。
def 可以声明一个标准函数,也可以定义一个函数式变量
scala> var sum=(x:Int,y:Int) => {x+y}
sum: (Int, Int) => Int = <function2>
scala> sum(1,2)
res19: Int = 3
// def 也可以定义一个函数式变量
scala> def sum1=(x:Int,y:Int) => {
| x*y
| }
sum1: (Int, Int) => Int
scala> sum1(2,3)
res20: Int = 6
//☆
scala> def method(x:Int,y:Int,f:(Int,Int)=>Int):Int = {
| f(x,y)
| }
method: (x: Int, y: Int, f: (Int, Int) => Int)Int
scala> var f=(a:Int,b:Int)=>a*b
f: (Int, Int) => Int = <function2>
scala> method(3,4,f)
res0: Int = 12
☆☆☆☆☆
def sum(x:Int,y:Int):Int = { return x+y }
def sum=(x:Int,y:Int)=>x+y
var sum=(x:Int,y:Int)=>x+y
var sum:(Int,Int)=> Int = (x,y)=> x+y
var sum = ((x,y)=> x+y):(Int,Int)=> Int
//柯里化 的匿名函数
def method(op:(Int,Int)=>Int)(x:Int,y:Int)={
op(x,y)
}
val result01 = method((x,y)=>x+y)(1,2)
println(result01)
八、类与对象
①.单例类
Scala没有静态方法和静态类,通过object去定义静态方法或者静态对象
object HelloUtil {
def sayHello(name:String):Unit={
println(s"hello ~~ $name")
}
//使用
HelloUtil.sayHello("zyl") // hello ~~ zyl
②.一般类
class User01() { //()默认构造,可省略( )
var id:Int=_
var name:String=_ //其中_表示参数赋值为默认值
var sex:Boolean=_
def this(id:Int,name:String,sex:Boolean){
this() //必须要求在构造方法的第一行显式调用this()
this.id=id
this.name=name
this.sex=sex
}
}
//类上声明(默认构造器)
class User02(var id:Int,var name:String,var sex:Boolean) {
def this(id:Int,name:String){
this(id,name,true)
this.id=id //这里及下一行可省略
this.name=name
}
}
③.伴生对象 ★
如果类和object在一个scala文件中,则称为object User 是class User的伴生对象
class User03 {
var id:Int=_
var name:String=_
def this(id:Int,name:String){
this()
this.id=id
this.name=name
}
}
object User03{
// unapply 工厂方法 解码对象 使用unapply方法能够将对象中的一些属性反解出来
def unapply(user: User03): Option[(Int, String)] = {
Some((user.id,user.name))
}
//apply 工厂方法 作用是生产User03实例对象
def apply(coid: Int, names: String):User03 = new User03(coid,names)
}
//----------------------------------------------------------------------------------------------
//测试代码
var u6 = new User03(3,"zyl4")
var u7 = User03
var u8 = User03.apply(4,"win7")
println(s"u8\tid:${u8.id},name:${u8.name}")
var u9 = User03(4,"win7")
println(u8==u9) // false
var User03(cid:Int,names:String) = u8
println(s"解码数据:${cid}\t${names}") //解码数据:4 win7
注意一个伴生对象中只能有一个unapply方法,这不同于apply方法,因为apply方法可以有多个。
④.抽象类
可以是实现的方法,也可以是未实现的方法
abstract class Animal(name:String) {
def eat():Unit={
println(s"animal $name eat")
}
def sleep():Unit
}
⑤.Trait(特性) 接口
方法可以是已实现的方法
trait Fly {
def fly():String
def shout():Unit={
println("it can shout")
}
}
⑥.继承&实现 ★
定义一个bee类,继承Animal类 ,实现 fly
无论是抽象类还是特性,单一继承都使用 extends
class Bee(name:String) extends Animal(name:String) with Fly { //extends Fly
override def sleep(): Unit = {
println(s"$name is a bee,it can sleep")
}
override def fly(): Unit = {
println(s"$name is a bee,it can fly")
}
}
//测试
val hive = new Bee("hive")
hive.eat()
hive.sleep()
hive.fly()
hive.shout()
/*
//animal hive eat
hive is a bee,it can sleep
hive is a bee,it can fly
can shout */
⑦.Trait动态植入
定义一个butterfly 类,继承动物,在使用过程中发现需要实现 fly 的方法
class Butterfly(var name:String) extends Animal(name:String) {
override def sleep(): Unit = {
println(s"$name is a butterfly,she can sleep")
}
}
//测试
var butterfly = new Butterfly("阿蝶") with Fly{
override def fly(): Unit = {
println(s"$name is a butterfly,she can fly")
}
}
butterfly.fly() // 阿蝶 is a butterfly,she can fly
1.在覆盖有实现的方法必须添加overwrite;
2.一个类只能继承一个类with多个trait
⑧.self
等价于this关键字,在this出现混淆的时候使用self给this关键字起别名。注:只可替代 .方法的部分
class User04 {
my => //可任意,自定义 ,必须写在类的第一行
var id:Int=_
var name:String=_
def this(id:Int,name:String){
this()
my.id = id
my.name = name
}
}
⑨.Trait强制混合
使得某个类要实现某个1特性的必须先实现特定的一个2特性
trait Swim { //特性1
can:Fly =>
def swim():Unit
}
trait Fly { //特性2
def fly():Unit
def shout():Unit={
println("it can shout")
}
}
//swan 类
//天鹅 swan
class Swan extends Fly with Swim {
override def fly(): Unit = {
println("swan can fly")
}
override def swim(): Unit = {
println("swan can swim")
}
}
⑩.Case Class ★
1.case class(样例类)常规类适用于对不可变数据进行建模
2.CaseClass创建的对象 == 比较的是对象的内容
3.简单的使用copy来实现两个对象间的值得传递
case class Email(name:String) {
}
//测试
var c1 = new Email("消息1")
var c2 = new Email("消息1")
println(c1) //Email(消息1)
println(c2) //Email(消息1)
println(c1==c2) // true 比较的是内容 ,地址目前无法比较
var c3 = c1.copy("消息2")
println(c3) //Email(消息2)
九、可见性
在 Scala 中,可以在类型的 class 或 trait 关键字之前、字段的 val 或 var 之前,方法定义的 def 关键字之前指定可见性。
①.private
不修饰类,子类不可用,外界仍可以通过伴生类获取对象;修饰类,可被同包下继承,且必须是private,外界无论如何不能获取
1.修饰属性、方法
在修饰属性表示该属性、方法、扩展构造只能被本类|伴生对象可见,其他均(包括子类)不可见。同包不可用。
class Student01 {
private var id:Int=_
var name:String=_
private def this(id:Int,name:String){
this()
this.id=id
this.name=name
}
private def hello():Unit={
println("hello")
}
override def toString = s"Student01($id, $name)"
}
object Student01{
def apply(id:Int,name:String): Student01 = new Student01(id,name)
def main(args: Array[String]): Unit = {
val stu = new Student01()
stu.id = 1;
stu.hello() //hello
println(stu) //Student01(1, null)
}
}
//测试
object Scalas {
def main(args: Array[String]): Unit = {
val stu01 = new Student01()
stu01.name = "zyl"
println(stu01) //Student01(0, zyl)
var stu02 = Student01(1,"zyl2") //伴生对象生成此对象
println(stu02) //Student01(1, zyl2)
}
2.修饰扩展构造
只能被伴生类使用,同包不可用。
3.修饰类
该类只能被同包下的子类继承,不同包类不可见,并且同包继承的类也必须是private修饰。因为这样才不会改变原始父类的可见性。
同时,半生类的apply 方法的返回值不能是 这个对象。 同包可用。同包继承。
private class Student02 {
var id:Int = _
var name:String = _
def this(id:Int,name:String){
this()
this.id = id
this.name = name
}
override def toString = s"Student02($id, $name)"
}
object Student02{
def apply(id: Int, name: String):Unit = new Student02(id,name)
def main(args: Array[String]): Unit = {
val stu = new Student02()
stu.name = "zyl"
stu.id = 1
println(stu) //Student02(1, zyl)
}
}
//测试
var stu03 = Student02.apply(2,"zyl3")
println(stu03) // ()
②.protected
不修饰类,子类可用,外界可用;修饰类,可被同包下继承,外界无法获取构造
1.修饰属性、方法 、构造
在修饰属性表示该属性、方法、扩展构造只能被本类|伴生对象以及子类和子类的伴生对象可见,其他均不可见。同包不可用
class Student03 {
protected var id:Int=_
var name:String=_
protected def this(id:Int,name:String){
this()
this.id=id
this.name=name
}
protected def hello():Unit={
println("hello student03")
}
}
object Student03{
def apply(id: Int, name: String): Student03 = new Student03(id, name)
def main(args: Array[String]): Unit = {
val stu1 = new Student03()
var stu2 = new Student03(2,"zyl2")
stu1.id=1
stu2.hello() //hello student03
}
}
//测试
var stu04 = new Student03()
Student03.apply(5,"zyl4")
2.修饰类
构造尽在本类及伴生类可用,子类必须同包。
protected class Student04 {
var id:Int=_
var name:String=_
def this(id:Int,name:String){
this()
this.id=id
this.name=name
}
def hello():Unit={
println("hello student03")
}
}
object Student04{
def apply(id: Int, name: String): Student04 = new Student04(id, name)
def main(args: Array[String]): Unit = {
new Student04(1,"zyl3")
}
}
//测试
var stu06 = Student04(6,"zyl6")
③.this限定
属性可操作范围仅仅限制在本类,去除伴生对象的可见性,可以添加this限定
protected的this限定,子类仍可使用
class Student01 {
private[this] var id:Int=_
var name:String=_
private def this(id:Int,name:String){
this()
this.id=id
this.name=name
}
private def hello():Unit={
println("hello")
}
override def toString = s"Student01($id, $name)"
}
object Student01{
def apply(id:Int,name:String): Student01 = new Student01(id,name) // apply 的id仍可用
def main(args: Array[String]): Unit = {
val stu = new Student01()
stu.hello()
println(stu)
}
}
④.包限定
表示 某个属性在包及子包下都可用,不再考虑 private 与 protected
class Student03 {
protected[two] var id:Int=_ //two 为当前包名
var name:String=_
protected def this(id:Int,name:String){
this()
this.id=id
this.name=name
}
protected def hello():Unit={
println("hello student03")
}
}
⑤.final 限定 ★
☆ 修饰类: 不可被继承
☆修饰方法: 不可被覆盖
☆修饰属性:修饰常量,不允许允许子类覆盖;
class Student05 {
var id:Int=_
final val name:String="zyl"
}
⑥.sealed 密封 ★
Trait和class可以标记为 sealed,这意味着必须在同一源文件中声明所有子类型这样就确保了所有的子类型都是已知的。
sealed abstract class Animal(name:String) {
def eat():Unit={
println("动物会吃~~~~")
}
}
sealed trait Flyable{
def fly():Unit={
println("这个东西会飞")
}
}
class Bird(name:String) extends Animal(name:String ) with Flyable{
}
//测试
val bi = new Bird("麻雀")
bi.fly() //这个东西会飞
bi.eat() //动物会吃~~~~
⑦.Lazy 加载 ★
Scala 使用 lazy定义变量,使其在使用时再加载。且其只能是不可变的变量。
object Small {
def small():String ={
println("Start...")
"small...1.2.3..."
}
def main(args: Array[String]): Unit = {
lazy val ch = small()
println("haha...")
println(ch)
/*
haha...
Start...
small...1.2.3...
*/
}
}
十、函数对象 ❀❀❀
①.lambda表达式
在Java1.8中提出了一个Functional Interface,如果一个接口里面只能有一个抽象方法。这种类型的接口也称为SAM接口,即Single Abstract Method interfaces。将该接口成为函数式接口。
@FunctionalInterface
public interface GreetingService {
void sayMessage(String message);
}
GreetingService gs=(message) -> System.out.println("hello "+message);
gs.sayMessage("张三");
②.部分应用函数
在Scala中同样对所有的函数都可以理解为是一个接口函数。例如在Scala中可以将任意一个函数转变成对象。
在Scala中左右的函数都可以更改成为Function1~22对象的实例
object TestScalaFunction {
def main(args: Array[String]): Unit = {
println(sum(1,2))
println(sumFun1(1,2))
println(sumFun2(1,2))
println(sumFun3(1,2))
println(new MySumFunction1()(1,2))
println(new MySumFunction2()(1,2))
println(pf1(2))
// println(pf1("abc"))
println(pf2(3))
// println(pf2("abc"))
val array = Array(1, 2, "a", true, 4, 5, 6)
var newarray1=for(item <- array;if(item.isInstanceOf[Int])) yield item.asInstanceOf[Int] * 2
var newarray2=array.collect(pf1)
var newarray3=array.collect({case i:Int=> i*2})
println(newarray1.mkString(" | "))
println(newarray2.mkString(" | "))
println(newarray3.mkString(" | "))
}
// 部分应用函数-----------------------------------
//标准写法
def sum(x:Int,y:Int):Int={
x+y
}
//变体写法
var sumFun1:(Int,Int)=>Int = (x,y) => x+y
//变体写法
var sumFun2:Function2[Int,Int,Int] = (x,y) => x+y
//最根本写法
var sumFun3:Function2[Int,Int,Int] = new Function2[Int,Int,Int] {
override def apply(v1: Int, v2: Int): Int = {
v1+v2
}
}
//偏函数-----------------------------------
//处理 Int类型参数。并且将参 数值*2
var pf1:PartialFunction[Any,Int]=new PartialFunction[Any,Int] {
//是否是用户处理类型
override def isDefinedAt(x: Any): Boolean = {
x.isInstanceOf[Int]
}
override def apply(v1: Any): Int = {
v1.asInstanceOf[Int]*2
}
}
var pf2:PartialFunction[Any,Int]={case x:Int=> x*2}
}
//子类
class MySumFunction1 extends Function2[Int,Int,Int]{
override def apply(v1: Int, v2: Int): Int = {
v1+v2
}
}
class MySumFunction2 extends ((Int,Int)=>Int){
override def apply(v1: Int, v2: Int): Int = {
v1+v2
}
}
③.偏函数
偏函数主要适用于处理指定类型的参数数据,通常用于集合处理中。定义一个函数,而让它只接受和处理其参数定义域范围内的子集,对于这个参数范围外的参数则抛出异常,这样的函数就是偏函数(顾名思异就是这个函数只处理传入来的部分参数)。偏函数是个特质其的类型为PartialFunction[A,B],其中接收一个类型为A的参数,返回一个类型为B的结果。
原文链接:https://blog.csdn.net/weixin_38231448/article/details/89354099
十一、隐式 ★
①.隐式值
分别使用implicit关键字和implicitly关键字声明隐式值和隐式注入等操作。
//隐式文件 MyImplicti
object MyImplicti {
//-------------------------------隐式值
implicit val a:Int = 17
//-------------------------------隐式注入
implicit val s="您好"
//-------------------------------隐式转换
implicit def translation(ch:Int):String={
ch.toString
}
//-------------------------------隐式增强
implicit class cowImplicit(cher:Cow){
def fly(): Unit ={
println("can fly")
}
}
}
//测试
object Test {
def main(args: Array[String]): Unit = {
import MyImplicti._ //引入隐式文件
/* implicit val a:Int=2*/
var num:Int=implicitly[Int]
println(num) //17
}
}
②.隐式注入
要求隐式注入的值一般都会写成柯理化形式并且保证需要隐式注入的值写在最后。
object Test {
def main(args: Array[String]): Unit = {
import MyImplicti._ //引入隐式文件
sayHi1 // 您好
sayHi2("张三") //您好 张三
sayHi2("李四")("早上好") //早上好 李四
}
def sayHi1(implicit msg:String):Unit={
println(msg)
}
def sayHi2(name:String)(implicit msg:String):Unit={
println(msg+" "+name)
}
}
③.隐式转换
该方式是通过隐式转换将参数不满足的类型转为所需类型,Scala在编译代码的时候,先尝试正常编译如果发现编译类型不匹配,会尝试加载当前上下文中是否存在该类型和目标类型的一种隐式转换(这种转换必须唯一),如果存在则编译通过。
def main(args: Array[String]): Unit = {
import MyImplicti._ //引入隐式文件
byby(233)
}
def byby(name:String):Unit={
println(s"$name bybe") // 233 bybe
}
④.隐式增强
给某个类扩展方法,区别与java的封装性,类似与trait动态植入 把 不可能 变为 可能
//定义一个cow类
class Cow {
def eat(): Unit ={
println("cow eat grass")
}
def sleep()={
println("cow sleep")
}
}
//提供隐式增强方法
implicit class cowImplicit(cher:Cow){
def fly(): Unit ={
println("can fly")
}
}
//测试
def main(args: Array[String]): Unit = {
import MyImplicti._//引入隐式文件
val cow = new Cow
cow.fly() //can fly
cow.eat()
cow.sleep()
}
十二、异常处理
scala 的 异常处理:不区分已检查和未检查异常、捕获按照case 进行匹配。(遇到合适的,即选择匹配—> 区别与java的由小到大的匹配度)
package com.baizhi.exceptions
import java.io.IOException
object ScalaExceptions {
def main(args: Array[String]): Unit = {
try {
throw new IOException("我自己抛出的~")
}catch {
case e:ArithmeticException =>{
println("ArithmeticException")
e.printStackTrace()
}
case e: Throwable =>{
println("Throwable")
e.printStackTrace()
}
case e: IOException =>{
println("IOException")
e.printStackTrace()
}
} finally {
System.out.println("最终执行")
}
}
}
十三、泛型
java里泛型使用 < T >等表示,在Scala中,泛型使用 [ T ]表示
①.上边界限定
即所使用的类型只能是 限定类型的本身及子类
//定义 动怒类、狗子类、杜宾类
class Animal (name:String){
def fun()={
println(s"$name 是动物")
}
}
class Dog(name:String) extends Animal(name:String) {
override def fun(): Unit = {
println(s"$name 是狗子")
}
}
class Dubin(name:String) extends Dog(name:String){
}
以下是效果案例:
object AnimalKepper {
def main(args: Array[String]): Unit = {
var a = kepperDog(new Dog("阿柴"))
var b = kepperDog(new Dubin("大黑"))
var c = kepperDog(new Animal("犬科")) //这个是不成立的,因为其是 dog的父类型。
println(a)
println(b)
println(c)
/*Error:(8, 13) inferred type arguments [com.baizhi.six.Animal] do not conform to method kepperDog's type parameter bounds [T <: com.baizhi.six.Dog]
var c = kepperDog(new Animal("犬科")) */
}
//上边界限定
def kepperDog[T <:Dog](t:T):Unit={
println(s"饲养$t")
}
}
②.下边界限定
所使用的类必须是 限定类型的本身及父类
//下边界限定
def kepperDog2[T>:Dog](t:T):Unit={
println(s"下边界限定的饲养$t")
}
def main(args: Array[String]): Unit = {
var a = kepperDog2(new Dog("阿柴"))
var b = kepperDog2(new Dubin("大黑")) //运行成功,这里产生了冲突,BUG!!
var c = kepperDog2(new Animal("犬科"))
}
但是,当边界限定定义在类或Trait上 并不会出现此BUG。
//定义一个界定下边界的泛型类
class Keeper[T>:Dog] {
def keepers(t:T):Unit={
println("喂养!")
}
}
//使用此类
new Keeper[Dog]{
override def keepers(t: Dog): Unit = println(t)
}
new Keeper[Dubin]{
override def keepers(t: Dubin): Unit = println(t)
}
} //ERROR 错误!!
③.视图限定
必须保证上下文中有能够提供一个隐式转换T <% U能够将T隐式转为U类(其本质是隐式转换的应用)
//视图限定
def shout[T <% Dog](t:T)={
println(s"$t 叫~~~")
}
//隐式转换文件
object MyImplicit {
implicit def strToDog(name:String):Dog={
new Dog(name)
}
}
//测试
import MyImplicit._
shout("阿牛") // 阿牛 叫~~~
④.T-A上下文绑定
表示上下文中必须存在这种隐式值A[T]隐式值,否则程序编译出错.这样可以在上下文中还没有隐式值得时候确保方法能编译成功。(本质是隐式值注入)
//定义一个类
class Student[T] {
def show(mes:T)={
mes match {
case x:String => println(s"name $x")
case x:Int => println(s"age $x")
case _ => println("..........")
}
}
}
//定义 Implicit文件
implicit val st1 = new Student[String]
implicit val st2 = new Student[Int]
//定义一个A[T] 绑定的方法
//T - A 上下文绑定
def message[T:Student](t:T)={
val stu = implicitly [Student[T]]
stu.show(t)
}
//测试
import MyImplicit._
message("zyl")
message(233)
⑤.A+ 协变
将子类的泛型引用赋值给父类
class Mes[+T] {
}
//测试
var p1 = new Mes[Person]
var p2 = new Mes[Man]
var p3 = new Mes[Child]
p1 = p2
p1 = p3
p2 = p3
⑥.A- 逆变
将 父类赋值给子类引用
class Mes[-T] {
}
//测试
var p1 = new Mes[Person]
var p2 = new Mes[Man]
var p3 = new Mes[Child]
p2 = p1
p3 = p2
p3 = p1
⑦.A不变
不再能相互赋值
class Mes[T] {
}
十四、数组&集合 ★
①.Array数组
// 创建数组
var a = Array(1,2,3,4,5)
var b =new Array[Int](5)
//获取长度
a.length
a.size
//修改下标为 1 的元素
a(1) = -1
a.update(1,2) //修改下标 1 的元素,改为 2
//遍历数组
for(i<-a) println(i)
②.Range区间
有下标,与数组类似,但是不可更改数据
//创建区间
var r1=new Range(0,10,3) //0 3 6 9
var r2=0.to(10).by(3) //Int 的 方法
var r3=0 until 10 by 3
//取值
r1(2) 6
//遍历、取长度 同数组
③.Vector坐标
同 Range 不可修改元素 ,有下标
//创建坐标
var v1 =Vector(1,2,3) // Vector(1, 2, 3)
var v2 = for(i<-0 to 10 by 3) yield i // Vector(0, 3, 6, 9)
//获取元素
v1(0) //1
v1(2) //6
//遍历、取长度 同数组
④.Iterator游标
不可以根据下标获取,只能遍历一次,以及取长度等操作只能一次
//创建游标
var it = new Iterator(1,2,3)
//遍历、取长度 同数组
//判断是否为空
val flag = it.isEmpty
⑤.List -不可变
//创建集合
var list=List(1,2,5,3,2)
//-------------------------------------------------------------------增
//添加元素 产生新的集合数组,不会修改原始集合
list.::(10)
list.+:(11)
//追加新的集合元素 产生新的集合数组,不会修改原始集合
list.:::(List(7,8,9))
//-------------------------------------------------------------------删
//删除n个元素 产生新的集合数组,不会修改原始集合
list.drop(3) //List(3, 2) ------> 数量
list.dropRight(3) //List(1, 2)
//删除符合条件的元素,匹配一个立即终止
list.dropWhile(item=> item < 5) // List(5, 3, 2) ------> 数值
//去除重复 产生新的集合数组,不会修改原始集合
list.distinct // List(1, 2, 5, 3)
////-------------------------------------------------------------------查
//选择一个子集 从0开始到4不包含4 产生新的集合数组,不会修改原始集合
list.slice(0,4) // ------> 数值区间
//前后翻转集合 产生新的集合数组,不会修改原始集合
list.reverse // List(2, 3, 5, 2, 1)
//获取前n个元素 产生新的集合数组,不会修改原始集合
list.take(3) //List(1, 2, 5) ------> 数量
list.takeRight(3) //List(5, 3, 2)
//一直拿,直到第一个不满足条件终止 产生新的集合数组,不会修改原始集合
list.takeWhile(item => item < 5 ) //List(1, 2) ------> 数值
//获取第一个元素、最后一个元素、除第一个以外的所有元素
list.head
list.last
list.tail
//获取数组大小
list.size
list.length
//获取数组指定位置的元素
list(2) // 5 ------> 下标
⑥.List -可变
要先导入此包import scala.collection.mutable.ListBuffer
insert(index,..)/remove/update
//创建集合
var list=ListBuffer(1,2,5,3,2)
//-------------------------------------------------------------------增
//添加元素 产生新的集合数组,不会修改原始集合
//list.::(10)
list.+:(11) //ListBuffer(1, 2, 5, 3, 2, 11)
//添加元素 产生新的集合数组,修改原始集合
list.+=(-1) // ListBuffer(1, 2, 5, 3, 2, -1)
list.+=:(-2) // ListBuffer(-2,1, 2, 5, 3, 2, -1)
//追加新的集合元素 产生新的集合数组,修改原始集合
//list.:::(List(7,8,9))
list.++=(List(7,8,9)) // ListBuffer(1, 2, 5, 3, 2, 7, 8, 9)
list.++=:(List(7,8,9))// ListBuffer(7, 8, 9, 1, 2, 5, 3, 2, 7, 8, 9)
//从指定位置 插入元素 修改原始集合
list.insert(0,-1,-2) //从0位置插入 -1,-2 ------> 下标
list.insertAll(0,List(0,0))
//-------------------------------------------------------------------删
//删除n个元素 产生新的集合数组,不会修改原始集合
list.drop(3) //List(3, 2) ------> 数量
list.dropRight(3) //List(1, 2)
//删除符合条件的元素,匹配一个立即终止
list.dropWhile(item=> item < 5) // List(5, 3, 2) ---->具体数字
//去除重复 产生新的集合数组,不会修改原始集合
list.distinct // List(1, 2, 5, 3)
//删除某个元素 修改原始集合
list.-=(1) // ListBuffer(2, 5, 3, 2) ---->具体数字
//删除指定位置元素 修改原始集合
var item=list.remove(2) // --> 下标
//-------------------------------------------------------------------改
//修改指定位置
list(2) = 12 // ListBuffer(1, 2, 12, 3, 2) ------> 下标
list.update(2,5) //ListBuffer(1, 2, 5, 3, 2)
//-------------------------------------------------------------------查
//选择一个子集 从0开始到4不包含4 产生新的集合数组,不会修改原始集合
list.slice(0,4) //------> 数值区间
//前后翻转集合 产生新的集合数组,不会修改原始集合
list.reverse // List(2, 3, 5, 2, 1)
//获取前n个元素 产生新的集合数组,不会修改原始集合
list.take(3) //List(1, 2, 5) ------> 数量
list.takeRight(3) //List(5, 3, 2)
//一直拿,直到第一个不满足条件终止 产生新的集合数组,不会修改原始集合
list.takeWhile(item => item < 5 ) //List(1, 2)------> 数值
//获取第一个元素、最后一个元素、除第一个以外的所有元素
list.head
list.last
list.tail
//获取数组大小
list.size
list.length
//获取数组指定位置的元素
list(2) // 5 ------> 下标
⑦.Set -不可变
无下标
//创建集合 去重
var s=Set[Int](1,2,4,5,3)
//-------------------------------------------------------------------增
//添加一个元素 产生新的集合Set,不会修改原始集合
s.+(6) //Set(5, 1, 6, 2, 3, 4) -----> 数值
//添加一个集合 产生新的集合Set,不会修改原始集合
s.++(List(6,6,7)) //Set(5, 1, 6, 2, 7, 3, 4)
//-------------------------------------------------------------------删
//删除元素 产生新的集合Set,不会修改原始集合
s.-(5) // Set(1, 2, 3, 4) -----> 数值
//-------------------------------------------------------------------查
//获取set大小
s.size
//判断元素是否存在
var isExists=s(5) //true -----> 数值
isExists=s(7) //false
//set遍历
for(i <- s) println(i)
}
⑧.Set -可变
先导包import scala.collection.mutable.Set
add /remove
import scala.collection.mutable.Set
object TestSet02 {
def main(args: Array[String]): Unit = {
//创建集合 去重
var s=Set[Int](1,2,4,5,3)
//-------------------------------------------------------------------增
//添加一个元素 产生新的集合Set,不会修改原始集合
s.+(6) //Set(5, 1, 6, 2, 3, 4) -----> 数值
//添加一个集合 产生新的集合Set,不会修改原始集合
s.++(List(6,6,7)) //Set(5, 1, 6, 2, 7, 3, 4)
//添加一个元素 产生新的集合Set,修改原始集合
s.add(6) //Set(5, 1, 6, 2, 3, 4) -----> 数值
//-------------------------------------------------------------------删
//删除元素 产生新的集合Set,不会修改原始集合
s.-(5) // Set(1, 2, 3, 4) -----> 数值
//删除元素 产生新的集合Set,修改原始集合
s.remove(5) //Set(1, 2, 3, 4) -----> 数值
//-------------------------------------------------------------------查
//获取set大小
s.size
//判断元素是否存在
var isExists=s(5) //true -----> 数值
isExists=s(7) //false
}
}
⑨.HashMap -不可变
先导入import scala.collection.immutable.HashMap
var hm= HashMap[String,String](("建设","001"),("招商","002"))
//-------------------------------------------------------------------增
//添加一个元素,并不会修改原始的Map
hm.+(("农业","003"))
hm.+("民生"->"004")
//合并两个map
var hm2=HashMap[String,String]("工商"->"003",("建设","005"))
hm.merged(hm2)((t1,t2)=> t2) //在key出现重复的时候,使用t2覆盖t1的元素
//-------------------------------------------------------------------删
//删除元数据,并不会修改原始的Map
hm.-("建设","招商")//-----> key
//-------------------------------------------------------------------改
//更新一个key,并不会修改原始的Map
hm.updated("建设","003") //----->key
//-------------------------------------------------------------------查
//获取指定key的值
val value: Option[String] = hm.get("建设") //-----> key
val sv1= value.get //该值必须存在
val sv2= value.getOrElse("啥也没有" )
//判断key是否存在
hm.contains("建设") //-----> key
//获取所有keys
val keys = hm.keys
val values = hm.values
//遍历一个Map
for(i<- hm.keys){
println(i+" "+hm.get(i).getOrElse(""))
}
}
⑩.HashMap - 可变
先导入scala.collection.mutable.HashMap
put/rmove/update
var hm= HashMap[String,String](("建设","001"),("招商","002"))
//-------------------------------------------------------------------增
//添加一个元素,并不会修改原始的Map
hm.+(("农业","003"))
hm.+("民生"->"004")
//添加一个元素,修改原始的Map
hm.put("工商","005")
//-------------------------------------------------------------------删
//删除元数据,并不会修改原始的Map
hm.-("建设","招商")
//删除元数据,修改原始的Map
hm.remove("建设")
//-------------------------------------------------------------------改
//更新一个key,并会修改原始的Map
hm.update("建设","003")
//更新一个key,并不会修改原始的Map
hm.updated("建设","003")
//-------------------------------------------------------------------查
//获取指定key的值
val value: Option[String] = hm.get("建设")
val sv1= value.get //该值必须存在
val sv2= value.getOrElse("啥也没有" )
//判断key是否存在
hm.contains("建设")
//获取所有keys
val keys = hm.keys
val values = hm.values
//遍历一个Map
for(i<- hm.keys){
println(i+" "+hm.get(i).getOrElse(""))
}
}
☆Java Scala 集合互转
scala.collection.JavaConverters._关键是此类 发挥作用
package com.baizhi.seven
import java.util
import scala.collection.JavaConverters._
object ListChange {
def main(args: Array[String]): Unit = {
val list = new util.ArrayList[String]()
list.add("八重樱")
list.add("冰八")
list.add("仿灵刀")
var list1 = list.asScala
for(i <- list1){
println(i)
}
/*
八重樱
冰八
仿灵刀
*/
var list2 = list1.asJava
for(j <- 0 to list2.size()-1){
println(list2.get(j)) /*八重樱 冰八 仿灵刀 */
}
}
}
十五、集合变换-算子
①.sort 排序
1.sorted
def sorted[B >: String](implicit ord: scala.math.Ordering[B]): List[String]字符串类型的算子
基本类型有默认的隐式值注入,自定义类型需要自定义的隐式值。
默认升序类型。
//自定义隐式值
var sort = new Ordering[String]{
| override def compare(x: String, y: String): Int = {
| x.compareTo(y) * -1
| }
| }
//使用 ;
scala> array.sorted(sort)
res2: List[String] = List(d, c, b, a)
//------------------------------------------------------------------------------------------------
//对于自定义类型
case class Calculate(id:Int,name:String) { }
//定义自定义类型的隐式值
implicit var sort2 = new Ordering[Calculate]{
override def compare(x: Calculate, y: Calculate): Int = {
x.id.compareTo(y.id) * -1
}
}
//测试
var arr = Array(Calculate(1,"a"),Calculate(2,"b"),Calculate(3,"c"))
arr.sorted //scala> arr.sorted
// res4: Array[Calculate] = Array(Calculate(3,c), Calculate(2,b), Calculate(1,a))
2.sortBy
基于单一属性排序
使用①中的自定义类型对应的算子
def sortBy[B](f: Calculate => B)(implicit ord: scala.math.Ordering[B]): Array[Calculate]
//因为 name是 String 类型,所有排序规则是按照字符升序排列
arr.sortBy(x=>x.name)
res10: Array[Calculate] = Array(Calculate(1,a), Calculate(2,b), Calculate(3,c))
3.sortWith
使用①中的自定义类型对应的算子
def sortWith(lt: (Calculate, Calculate) => Boolean): Array[Calculate]
arr.sortWith((z1,z2)=>{
if(z1.id.equals(z2.id)){
z1.name.compareTo(z2.name) >0
}else{
z1.id.compareTo(z2.id) * -1>0 //升序
}
})
②.flatten
以下是对于List[String]的算子
flatten[B](implicit asTraversable: List[String] => scala.collection.GenTraversableOnce[B]): List[B]
展开集合中的元素,主要用于降维
//对于默认的算子
scala> var list = List(List("1","2"),List("3","4","5"))
list: List[List[String]] = List(List(1, 2), List(3, 4, 5))
scala> list.flatten
res14: List[String] = List(1, 2, 3, 4, 5)
//--------------------------------------------------------------------------------
scala> var list = List("1,2,3","3,45,6")
list: List[String] = List(1,2,3, 3,45,6)
scala> list.flatten(x=>x.split(",")) //使用flatten自定义算法
res18: List[String] = List(1, 2, 3, 3, 45, 6)
③.map
该算子可以操作集合的每一个元素,并对每一个元素做映射(转换)
scala> var list = List(1,2,4,5)
list: List[Int] = List(1, 2, 4, 5)
scala> list.map(_*2)
res0: List[Int] = List(2, 4, 8, 10)
scala> var list = List("good good study","day day up")
list: List[String] = List(good good study, day day up)
scala> list.map(_.split("\\s+"))
res2: List[Array[String]] = List(Array(good, good, study), Array(day, day, up))
④.flatMap
该算子对集合元素先进行转换,然后执行flatten展开降维
scala> var list = List("good good study","day day up")
list: List[String] = List(good good study, day day up)
scala> list.map(_.split("\\s+"))
res2: List[Array[String]] = List(Array(good, good, study), Array(day, day, up))
scala> res2.flatten
res4: List[String] = List(good, good, study, day, day, up)
scala> list.flatMap(_.split("\\s+"))
res3: List[String] = List(good, good, study, day, day, up)
⑤.filter/filterNot
该算子过滤掉不满足条件的元素
scala> var list = List((1,"zyl",200.0),(2,"zcl",300.0))
list: List[(Int, String, Double)] = List((1,zyl,200.0), (2,zcl,300.0))
scala> list.filter(_._3>=250)
res7: List[(Int, String, Double)] = List((2,zcl,300.0))
scala> list.filterNot(_._3>=250.0)
res8: List[(Int, String, Double)] = List((1,zyl,200.0))
⑥.distinct
去除重复数据
//集合整体去重
scala> var list = List(List(1,2,3),List(1,2,3))
list: List[List[Int]] = List(List(1, 2, 3), List(1, 2, 3))
scala> list.distinct
res11: List[List[Int]] = List(List(1, 2, 3))
//元祖去重
scala> list = List((1,"zyl",234),(1,"zyl",234))
list: List[(Int, String, Double)] = List((1,zyl,234.0), (1,zyl,234.0))
scala> list.distinct
res9: List[(Int, String, Double)] = List((1,zyl,234.0))
⑦.groupBy
该算子将List或者Array转换为一个Map
// 获取 部门的总薪资的排名
scala> var list = Array("1,001,zyl,2000.0","2,002,zyl2,4000.0","3,001,zyl3,6000.0")
list: Array[String] = Array(1,001,zyl,2000.0, 2,002,zyl2,4000.0, 3,001,zyl3,6000.0)
scala> list.map(_.split(","))
res18: Array[Array[String]] = Array(Array(1, 001, zyl, 2000.0), Array(2, 002, zyl2, 4000.0), Array(3, 001, zyl3, 6000.0))
scala> list.map(_.split(",")).map(x=>(x(1),x(3).toDouble))
res21: Array[(String, Double)] = Array((001,2000.0), (002,4000.0), (001,6000.0))
scala> list.map(_.split(",")).map(x=>(x(1),x(3).toDouble)).groupBy(y=>y._1)
res22: scala.collection.immutable.Map[String,Array[(String, Double)]] = Map(002 -> Array((002,4000.0)), 001 -> Array((001,2000.0), (001,6000.0)))
scala> list.map(_.split(",")).map(x=>(x(1),x(3).toDouble)).groupBy(y=>y._1).map(z=>(z._1,z._2.map(_._2)))
res34: scala.collection.immutable.Map[String,Array[Double]] = Map(002 -> Array(4000.0), 001 -> Array(2000.0, 6000.0))
scala> list.map(_.split(",")).map(x=>(x(1),x(3).toDouble)).groupBy(y=>y._1).map(z=>(z._1,z._2.map(_._2))).map(h=>(h._1,h._2.sum)).toList
res35: List[(String, Double)] = List((002,4000.0), (001,8000.0))
scala> list.map(_.split(",")).map(x=>(x(1),x(3).toDouble)).groupBy(y=>y._1).map(z=>(z._1,z._2.map(_._2))).map(h=>(h._1,h._2.sum)).toList.sortBy(_._2).reverse
res37: List[(String, Double)] = List((001,8000.0), (002,4000.0))
⑧.max、min
1.max、min
计算最值
//使用⑦中的结果进行计算
scala> list.map(_.split(",")).map(x=>(x(1),x(3).toDouble)).groupBy(y=>y._1).map(z=>(z._1,z._2.map(_._2))).map(h=>(h._1,h._2.sum)).toList.sortBy(_._2).reverse.max
res41: (String, Double) = (002,4000.0) //默认对 第一个元素进行排序 取最值
2.maxBy、minBy
按照特定条件取最大、最小值
//仍然使用⑦中的结果进行计算
scala> list.map(_.split(",")).map(x=>(x(1),x(3).toDouble)).groupBy(y=>y._1).map(z=>(z._1,z._2.map(_._2))).map(h=>(h._1,h._2.sum)).toList.sortBy(_._2).reverse.minBy(s=>s._2)
res43: (String, Double) = (002,4000.0)
⑨.r 、f 、a
1.reduce
基于下方例子的算子:
def reduce[A1 >: Int](op: (A1, A1) => A1): A1
集合不能为空,为空报错
reduce、reduceLeft、reduceRight

scala> var list= List(2,4,5,6,7)
list: List[Int] = List(2, 4, 5, 6, 7)
scala> list.reduce((v1,v2)=>v1+v2)
res49: Int = 24
scala> list.reduceRight((v1,v2)=>v1+v2)
res50: Int = 24
scala> list.reduceLeft((v1,v2)=>v1+v2)
res52: Int = 24
2.fold
fold 、foldLeft 、foldRight
基于下方例子的算子:
def fold[A1 >: Int](z: A1)(op: (A1, A1) => A1): A1
相比于reduced有初始值,集合可以为空

scala> var list= List(2,4,5,6,7)
list: List[Int] = List(2, 4, 5, 6, 7)
scala> list.fold(2)((v1,v2)=>v1+v2)
res54: Int = 26
scala> list.foldRight(2)((v1,v2)=>v1+v2)
res55: Int = 26
scala> list.foldLeft(2)((v1,v2)=>v1+v2)
res56: Int = 26
3.aggregate
基于下方例子的算子:
def aggregate[B](z: => B)(seqop: (B, Int) => B,combop: (B, B) => B): B
相比于fold,aggregate分为多段计算类似MapReduce

scala> var list= List(2,4,5,6,7)
list: List[Int] = List(2, 4, 5, 6, 7)
scala> list.aggregate(0)((x1,x2)=>x1+x2 ,(y1,y2)=>y1+y2)
res59: Int = 24
//par 可以将任意一个集合拆分,并行计算
scala> list.par.aggregate(3)((x1,x2)=>x1+x2 ,(y1,y2)=>y1+y2)
res61: Int = 39
☆☆☆☆☆
//计算各部门员工的平均薪资
//数据样本
scala> var list = Array("1,001,zyl,1000.0","2,001,zyl2,7000.0","3,002,zyl3,3000.0","4,003,zyl4,3500.0")
list: Array[String] = Array(1,001,zyl,1000.0, 2,001,zyl2,7000.0, 3,002,zyl3,3000.0, 4,003,zyl4,3500.0)
//① 拆分每个元素
scala> list.map(_.split(","))
res62: Array[Array[String]] = Array(Array(1, 001, zyl, 1000.0), Array(2, 001, zyl2, 7000.0), Array(3, 002, zyl3, 3000.0), Array(4, 003, zyl4, 3500.0))
//②.提取部门信息和薪资信息
scala> list.map(_.split(",")).map(x=>(x(1),x(3).toDouble))
res64: Array[(String, Double)] = Array((001,1000.0), (001,7000.0), (002,3000.0), (003,3500.0))
//③.分组,获取每个部门的各自信息
scala> list.map(_.split(",")).map(x=>(x(1),x(3).toDouble)).groupBy(_._1)
res76: scala.collection.immutable.Map[String,Array[(String, Double)]] = Map(002 -> Array((002,3000.0)), 001 -> Array((001,1000.0), (001,7000.0)), 003 -> Array((003,3500.0)))
//④整合各个部门的薪资信息
scala> list.map(_.split(",")).map(x=>(x(1),x(3).toDouble)).groupBy(_._1).map(y=>(y._1,y._2.map(_._2)))
res71: scala.collection.immutable.Map[String,Array[Double]] = Map(002 -> Array(3000.0), 001 -> Array(1000.0, 7000.0), 003 -> Array(3500.0))
//⑤运行aggregate进行薪资统计计算
scala> list.map(_.split(",")).map(x=>(x(1),x(3).toDouble)).groupBy(_._1).map(y=>(y._1,y._2.map(z=>z._2))).map(a=>(a._1,a._2.aggregate((0,0.0))((b,c)=>(b._1+1,b._2+c),(d1,d2)=>(d1._1+d2._1,d1._2+d2._2))))
res80: scala.collection.immutable.Map[String,(Int, Double)] = Map(002 -> (1,3000.0), 001 -> (2,8000.0), 003 -> (1,3500.0))
//⑥计算最终结果
scala> list.map(_.split(",")).map(x=>(x(1),x(3).toDouble)).groupBy(_._1).map(y=>(y._1,y._2.map(z=>z._2))).map(a=>(a._1,a._2.aggregate((0,0.0))((b,c)=>(b._1+1,b._2+c),(d1,d2)=>(d1._1+d2._1,d1._2+d2._2)))).map(s=>(s._1,s._2._2/s._2._1)).toList
res81: List[(String, Double)] = List((002,3000.0), (001,4000.0), (003,3500.0))
⑩.额外
1.grouped
对一维数据进行升维
scala> var list2 = List(1,2,4,5,7)
list2: List[Int] = List(1, 2, 4, 5, 7)
scala> list2.grouped(2).toList
res85: List[List[Int]] = List(List(1, 2), List(4, 5), List(7))
2.zip
将两个一维的集合合并一个一维的集合
scala> var list2 = List(1,2,4,5,7)
list2: List[Int] = List(1, 2, 4, 5, 7)
scala> var list3 = List("a","e","f","d")
list3: List[String] = List(a, e, f, d)
scala> list2.zip(list3)
res86: List[(Int, String)] = List((1,a), (2,e), (4,f), (5,d))
scala> list3.zip(list2)
res87: List[(String, Int)] = List((a,1), (e,2), (f,4), (d,5))
3.unzip
将一个元祖分解为多个一维度集合
scala> res87
res88: List[(String, Int)] = List((a,1), (e,2), (f,4), (d,5))
scala> res87.unzip
res89: (List[String], List[Int]) = (List(a, e, f, d),List(1, 2, 4, 5))
4.d | i | u
差集、交集、并集
scala> var list2 = List(1,2,4,5,7)
list2: List[Int] = List(1, 2, 4, 5, 7)
scala> var list4 = List(1,8,9,3,6)
list4: List[Int] = List(1, 8, 9, 3, 6)
scala> list2.diff(list4)
res90: List[Int] = List(2, 4, 5, 7)
scala> list4.diff(list2)
res91: List[Int] = List(8, 9, 3, 6)
scala> list2.intersect(list4)
res92: List[Int] = List(1)
scala> list4.intersect(list2)
res93: List[Int] = List(1)
scala> list4.union(list2)
res94: List[Int] = List(1, 8, 9, 3, 6, 1, 2, 4, 5, 7)
scala> list2.union(list4)
res95: List[Int] = List(1, 2, 4, 5, 7, 1, 8, 9, 3, 6)
5.sliding
滑动产生新的元素数据
基于Int类型的算子:
def sliding(size: Int,step: Int): Iterator[List[Int]] def sliding(size: Int): Iterator[List[Int]]
scala> res95
res96: List[Int] = List(1, 2, 4, 5, 7, 1, 8, 9, 3, 6)
scala> res95.sliding(3,3).toList
res98: List[List[Int]] = List(List(1, 2, 4), List(5, 7, 1), List(8, 9, 3), List(6))
6.slice
截取数组子集
基于Int类型的算子:
override def slice(from: Int,until: Int): List[Int]
scala> var l = List(1,2,4,5,6)
l: List[Int] = List(1, 2, 4, 5, 6)
scala> l.slice(1,3) //下标
res105: List[Int] = List(2, 4)
7.字符统计案例 ☆
//原数据
scala> var arrs=Array("this is a demo","good good study","day day up")
arrs: Array[String] = Array(this is a demo, good good study, day day up)
//①降维拆分
scala> arrs.flatMap(_.split("\\s+"))
res110: Array[String] = Array(this, is, a, demo, good, good, study, day, day, up)
//②分组
scala> arrs.flatMap(_.split("\\s+")).groupBy(x=>x)
res111: scala.collection.immutable.Map[String,Array[String]] = Map(this -> Array(this), demo -> Array(demo), is -> Array(is), good -> Array(good, good), up -> Array(up), a -> Array(a), day -> Array(day, day), study -> Array(study))
//③统计数量
scala> arrs.flatMap(_.split("\\s+")).groupBy(x=>x).map(y=>(y._1,y._2.size))
res112: scala.collection.immutable.Map[String,Int] = Map(this -> 1, demo -> 1, is -> 1, good -> 2, up -> 1, a -> 1, day -> 2, study -> 1)
//④最终处理
scala> arrs.flatMap(_.split("\\s+")).groupBy(x=>x).map(y=>(y._1,y._2.size)).toList.sortBy(_._2).reverse
res115: List[(String, Int)] = List((day,2), (good,2), (study,1), (a,1), (up,1), (is,1), (demo,1), (this,1))
あ:统计本地文件的字符出现次数
object WordCount {
def main(args: Array[String]): Unit = {
//从本地加载数据
var source=Source.fromFile("E:\\文档\\大数据\\feiq\\Recv Files\\07-Scala\\代码\\t_word.txt")
var array=ListBuffer[String]()
val reader = source.bufferedReader()
var line = reader.readLine()
while(line!=null){
array += line
line = reader.readLine()
}
array.flatMap(_.split(" "))
.map((_,1))
.groupBy(_._1)
.map(x=> (x._1,x._2.size))
.toList .sortBy(_._2)
.reverse
.foreach(println)
reader.close()
}
