一、框架
- 框架(framework)是一个框子——指其约束性,也是一个架子——指其支撑性。是一个基本概念上的结构,用于去解决或者处理复杂的问题。
- 框架是整个或部分系统的可重用设计,表现为一组抽象构件及构件实例间交互的方法;另一种定义认为,框架是可被应用开发者定制的应用骨架。前者是从应用方面而后者是从目的方面给出的定义。
- 框架,其实就是某种应用的半成品,就是一组组件,供你选用完成你自己的系统。简单说就是使用别人搭好的舞台,你来做表演。
二、优势
- 自己从头实现太复杂
- 使用框架能够更专注于业务逻辑,加快开发速度
- 框架的使用能够处理更多细节问题
- 使用人数多,稳定性,扩展性好
三、selenium介绍
- 概念
Selenium是ThoughtWorks公司的一个强大的开源Web功能测试工具系列,采用Javascript来管理整个测试过程,包括读入测试套件、执行测试和记录测试结果。 - 特点
(1)它采用Javascript单元测试工具JSUnit为核心,只要在测试用例中把预期的用户行为与结果都描述出来,我们就得到了一个可以自动化运行的功能测试套件。
(2)Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。 - selenium2.0
selenium 2.0 = selenium RC + webdriver
Selenium2.0主推webdriver - Selenium(webdriver)工作原理
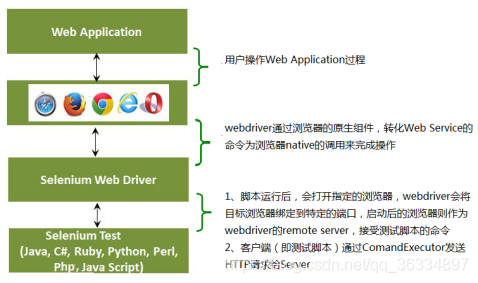
- Selenium组件
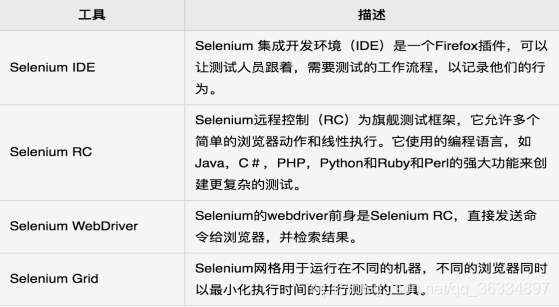
注 - selenium安装命令(无需进入python环境)
①命令行安装命令:pip install selenium==2.53.1 (2.53.1版本最稳定)
②卸载命令:pip uninstall selenium
③命令行中退出python环境 exit()或quit()
④selenium中自带火狐驱动,无需安装(43版本以下)
⑤其他浏览器的驱动路径需要添加到系统变量的环境变量Path变量中
⑥谷歌驱动映射下载表https://www.cnblogs.com/kaibindirver/p/9334352.html
- selenium RC VS WebdriVer

注
RC并非直接调用浏览器,需要通过服务来驱动浏览器的支持
四、selenium IDE
-
概念
Selenium的IDE(集成开发环境)是一个易于使用的Firefox插件,用于开发Selenium测试案例。它提供了一个图形用户界面,用于记录使用Firefox浏览器,用来学习和使用Selenium用户操作,但它只能用于只用Firefox浏览器不支持其它浏览器。(不经常使用) -
介绍
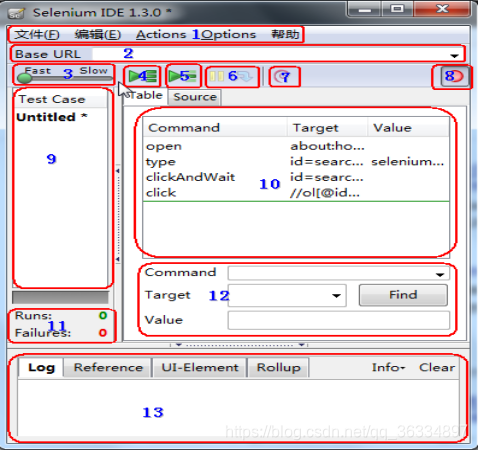
1.文件:创建、打开和保存测试案例和测试案例集。编辑:复制、粘贴、删除、撤销和选择测试案例中的所有命令。Options : 用于设置seleniunm IDE。
2.用来填写要录制的网站地址。
3.速度控制:控制案例的运行速度。
4.运行所有:运行一个测试案例集中的所有案例。
5.运行:运行当前选定的测试案例。
6.暂停/恢复:暂停和恢复测试案例执行。
7.单步:可以运行一个案例中的一行命令。
8.录制:点击之后,开始记录你对浏览器的操作。
9.案例集列表。
10.测试脚本;table标签:用表格形式展现命令及参数。source标签:用原始方式展现,默认是HTML语言格式,也可以用其他语言展示。
11.查看脚本运行通过/失败的个数。
12.当选中前命令对应参数。
13.日志/参考/UI元素/Rollup
五、浏览器操作
-
库的导入
from selenium import webdriver -
创建浏览器对象
扫描二维码关注公众号,回复: 10351178 查看本文章
driver = webdriver.xxx() 使用dir(driver)查看方法 (xxx:表示firefox,chrome,ie等) -
浏览器尺寸相关操作
driver.maximize_window() 最大化 driver.get_window_size() 获取浏览器尺寸 driver.set_window_size() 设置浏览器尺寸 driver.get_window_position() 获取浏览器位置 driver.set_window_position(x,y) 设置浏览器位置
注
显示器以左上角为(0,0),所有的位置操作都是相对于显示器左上角展开的位移操作,单位是像素。
-
浏览器的关闭操作
driver.close() 关闭当前标签/窗口 driver.quit() 关闭所有标签/窗口(关闭整个浏览器)
from selenium import webdriver
driver = webdriver.Firefox() # 创建浏览器对象
driver.maximize_window() # 浏览器窗口最大化
size = driver.get_window_size() #获取最大化窗口的尺寸
position = driver.get_window_position() # 获取窗口坐标
print(size) # 打印尺寸
print(position) # 打印坐标
driver.set_window_size(400,400) # 设置浏览器窗口尺寸
size = driver.get_window_size() #获取更改后窗口的尺寸
position = driver.set_window_position(400,400) # 设置浏览器位置
print(size) # 打印尺寸
print(position) # 打印坐标
六、页面操作
driver.get(url) 请求某个url对应的响应
driver.refresh() 刷新页面操作
driver.back() 回退到之前的页面
driver.forward() 前进到之后的页面
from selenium import webdriver
import time
driver = webdriver.Firefox()
# 访问百度首页
url1 = 'http://www.baidu.com' #域名需要添加http
driver.get(url1)
print('访问:',url1)
#访问新浪首页
url2 = 'https://www.sina.com.cn/'
driver.get(url2)
print('访问:',url2)
# 后退到url1
time.sleep(2)
driver.back()
print('后退到:',url1)
#前进到url2
driver.forward()
time.sleep(2)
print('前进到:',url2)
driver.close()
七、获取断言信息
-
概念
断言是编程术语,表示为一些布尔表达式,程序员相信在程序中的某个特定点该表达式值为真,可以在任何时候启用和禁用断言验证,因此可以在测试时启用断言而在部署时禁用断言。 -
获取断言信息的操作
driver.current_url 获取当前访问页面url driver.title 获取当前浏览器标题 driver.get_screenshot_as_png() 保存图片 driver.get_screenshot_as_file(file) 直接保存 driver.page_source 网页源码
from selenium import webdriver
import time
driver = webdriver.Firefox()
#获取百度首页
url = 'http://baidu.com.cn/'
driver.get(url)
# 获取当前页面url
print(driver.current_url)
# 获取当前页面标题
print(driver.title)
#保存快照操作
#第一种方式-自动保存成jpg文件
driver.get_screenshot_as_file('百度.jpg')
#第二种方式-将图片保存在内存中,所以需要手动写入jpg文件
data = driver.get_screenshot_as_png() #data为二进制型
with open('百度2.jpg','wb') as f:
f.write(data)
# 获取页面源码操作
date2 = driver.page_source # date2为字符串类型
with open('百度.html','wb') as f:
f.write(date2.encode())
注
- str类型转换为bytes类型 str.encode()
- 二进制类型转换为str类型 str.decode()
- Selenium3.0版本中get_screenshot_as_png更好用,可直接传入文件名参数,无需手动写入文件
八、单一元素的定位
-
元素定位方法的分类(调用方式)
-
直接调用型(推荐方式)
driver.find_element_by_xxx(value)
(1). driver.find_element_by_id(value) (2). driver.find_element_by_name(value) (3). driver.find_element_by_class_name(value) (4). driver.find_element_by_tag_name(value) (5). driver.find_element_by_link_text(value) (6). driver.find_element_by_partial_link_text(value) (7). driver.find_element_by_xpath(value) (8). driver.find_element_by_css_selector(value) -
使用By类型(需要导入By)
from selenium.webdriver.common.by import By
driver.find_element(By.xxx,value)(1)driver.find_element(By.ID,value) (2)driver.find_element(By.NAME,value) (3)driver.find_element(By.CLASS_NAME,value) (4)driver.find_element(By.TAG_NAME,value) (5)driver.find_element(By.LINK_TEXT,value) (6)driver.find_element(By.PARTIAL_LINK_TEXT,value) (7)driver.find_element(By.XPATH,value) (8)driver.find_element(By.CSS_SELECTOR,value)
#使用第一种定位方式(推荐使用)
from selenium import webdriver
# 获取浏览器对象
driver = webdriver.Firefox()
# 访问百度首页(相当于地址栏输入百度网址并回车)
url = 'http://baidu.com'
driver.get(url)
# 定位百度首页搜索框并搜索传智播客
el = driver.find_element_by_id('kw') #el是一个对象(类)
el.send_keys('python') # 向百度搜索框传递参数
# 定位百度搜索按钮并点击
el_click = driver.find_element_by_id('su')
el_click.click() # 实现点击按钮操作
driver.close() # 关闭浏览器
注
①获取id属性的属性值(‘su’,’kw’)可通过浏览器自带的审查元素查看,或使用插件firepath、firebug查看,选中元素,单击右键查看元素
②使用firebug或firepath插件有可能出现定位不准确或路径不准确的现象,一般有推荐使用浏览器自带的审查元素进行定位
③通过标签名定位元素,要么该标签唯一,要么该标签位于结果集中的第一位
#使用第二种定位方式
from selenium import webdriver
from selenium.webdriver.common.by import By
# 获取浏览器对象
driver = webdriver.Firefox()
# 访问百度首页
url = 'http://baidu.com'
driver.get(url)
# 定位百度首页搜索框并搜索传智播客
el = driver.find_element(By.ID,'kw') #el是一个对象(类)
el.send_keys('python') # 向百度搜索框传递参数
# 定位百度搜索按钮
el_click = driver.find_element(By.ID,'su')
el_click.click() # 实现点击按钮操作
driver.close() # 关闭浏览器
# 使用name属性方式定位
from selenium import webdriver
import time
# 获取浏览器对象
driver = webdriver.Firefox()
# 访问人人网首页
url = 'http://www.renren.com/'
driver.get(url)
# 定位首页账号输入框并输入账号
el_user = driver.find_element_by_name('email')
el_user.send_keys('17173805860')
# 定位首页密码框并输入密码
el_pwd = driver.find_element_by_name('password')
el_pwd.send_keys('lqaz@WSX3edc')
# 定位登录按钮并点击
el_sub = driver.find_element_by_id('login')
el_sub.click() # 点击按钮
time.sleep(5)
driver.close() # 关闭浏览器
# 使用class属性方式定位
from selenium import webdriver
import time
# 获取浏览器对象
driver = webdriver.Firefox()
# 访问斗鱼网首页
url = 'https://www.douyu.com/directory/all'
driver.get(url)
# 连续定位10次下一页按钮并点击按钮
for i in range(10):
el_next = driver.find_element_by_class_name('dy-Pagination-next')
el_next.click() # 点击下一页按钮
time.sleep(5)
driver.close() # 关闭浏览器
# 使用tag_name(标签名)方式定位
from selenium import webdriver
import time
# 获取浏览器对象
driver = webdriver.Firefox()
# 访问bing浏览器
url = 'https://cn.bing.com/'
driver.get(url)
# 定位搜索框并输入内容
el = driver.find_element_by_tag_name('input')
el.send_keys('selenium')
# 定位搜索按钮
el_2 = driver.find_element_by_id('sb_form_go')
el_2.click() # 点击搜索按钮
time.sleep(5)
driver.close() # 关闭浏览器
# 使用link_text(链接文本)方式定位
from selenium import webdriver
import time
# 获取浏览器对象
driver = webdriver.Firefox()
# 访问北京58网首页
url = 'http://bj.58.com/'
driver.get(url)
# 通过链接文字方式定位租房链接并点击
el = driver.find_element_by_link_text('硬件')
el.click() #点击链接,此时会打开一个新窗口
time.sleep(5)
driver.close() # 只关闭第一个窗口
driver.quit() # 关闭所有的窗口
#练习使用partial_link_text(链接部分文字)方式定位
from selenium import webdriver
import time
# 获取浏览器对象
driver = webdriver.Firefox()
# 访问百度首页
url = 'http://www.baidu.com'
driver.get(url)
# 通过链接部分文字方式定位租房链接并点击
el = driver.find_element_by_partial_link_text('hao')
el.click() #点击链接,在当前窗口打开一个新标签页
time.sleep(5)
driver.close() # 关闭窗口
# 练习使用Xpath方式定位
from selenium import webdriver
import time
# 获取浏览器对象
driver = webdriver.Firefox()
# 访问豆瓣电影首页
url = 'https://movie.douban.com/'
driver.get(url)
# 通过Xpath定位全部正在热映链接并点击
el = driver.find_element_by_xpath(".//*[@id='screening']/div[1]/h2/span[1]/a")
el.click() #点击链接,在当前窗口打开一个新标签页
time.sleep(5)
driver.close() # 关闭窗口
# 练习使用CSS方式定位
from selenium import webdriver
import time
# 获取浏览器对象
driver = webdriver.Firefox()
# 访问天猫首页
url = 'https://www.tmall.com/'
driver.get(url)
# 通过css定位天猫国际链接并点击
#第一种 - 使用fitrpath获取css选择器(使用firepath查看元素,复制css路径,定位不准确)
# el = driver.find_element_by_css_selector(".inner-con2.clearfix>a>img")
#第二种 - 使用firebug获取css选择器(使用firebug查看元素,点击右键获取css路经)--出错
# el = driver.find_element_by_css_selector("html.ks-gecko35.ks-gecko.ks-firefox35.ks-firefox body.w1230 div#mallPage.mui-global-biz-mallfp div#content div.main-nav div.inner-con0 div.inner-con1 div.inner-con2.clearfix a img")
#第三种 - 使用浏览器自带的审查元素获取css选择器(右键选择审查元素,点击复制唯一路径)
el = driver.find_element_by_css_selector(".inner-con2 > a:nth-child(2) > img:nth-child(1)")
el.click() #点击链接,在新窗口打开一个新标签页
time.sleep(5)
driver.quit() # 关闭所有用程序打开的窗口
七、定位一组元素
-
第一种
driver.find_elements_by_xxx(value)1. driver.find_elements_by_id(value) 2. driver.find_elements_by_name(value) 3. driver.find_elements_by_class_name(value) 4. driver.find_elements_by_tag_name(value) 5. driver.find_elements_by_link_text(value) 6. driver.find_elements_by_partial_link_text(value) 7. driver.find_elements_by_xpath(value) 8. driver.find_elements_by_css_selector(value) -
第二种
driver.find_elements(By.xxx,value)1.driver.find_elements(By.ID,value) 2.driver.find_elements(By.NAME,value) 3.driver.find_elements(By.CLASS_NAME,value) 4.driver.find_elements(By.TAG_NAME,value) 5.driver.find_elements(By.LINK_TEXT,value) 6.driver.find_elements(By.PARTIAL_LINK_TEXT,value) 7.driver.find_elements(By.XPATH,value) 8.driver.find_elements(By.CSS_SELECTOR,value)
# 获取一组百度搜索结果元素列表
from selenium import webdriver
import time
# 获取浏览器对象
driver = webdriver.Firefox()
# 访问百度首页
url = 'http://www.baidu.com/'
driver.get(url)
# 定位搜索框元素并在搜索框中输入内容
el = driver.find_element_by_id('kw')
el.send_keys('selenium')
# 定位搜索按钮并点击按钮
el_sub = driver.find_element_by_id('su')
el_sub.click() # 点击按钮
# 定位多个元素并存进列表
el_list = driver.find_elements_by_css_selector('div[id="content_left"]>div>h3>a')
print(el_list) # 打印列表
time.sleep(5)
driver.close() # 关闭窗口
# 获取58房屋出租元素列表
from selenium import webdriver
import time
# 获取浏览器对象
driver = webdriver.Firefox()
# 访问58同城租房网页
url = 'https://bj.58.com/chuzu/?PGTID=0d100000-0000-1efb-e60d-a376bad42316&ClickID=1'
driver.get(url)
# 定位一组元素并存储进列表
el_list = driver.find_elements_by_css_selector("li.house-cell > div:nth-child(2) > h2:nth-child(1) > a:nth-child(1)”)
print(el_list) # 打印列表
time.sleep(5)
driver.close() # 关闭窗口
八、元素的操作(对定位到的元素进行的操作)
-
点击操作
element.click() -
清空/输入操作(只能操作可以输入文本的元素)
element.clear() 清空输入框 element.send_keys(data) 输入数据 -
提交操作
element.submit() 等同click(推荐使用click)
九、获取元素信息
-
获取文本内容(既开闭标签之间的内容)
element.text -
获取属性值(获取element元素的value属性的值)
element.get_attribute(value) -
获取元素尺寸
element.size -
获取元素是否可见
element.is_dispalyed()
# 练习元素操作
from selenium import webdriver
import time
# 获取浏览器对象
driver = webdriver.Firefox()
# 访问百度首页
url = 'http://www.baidu.com/'
driver.get(url)
# 定位搜索框元素并在搜索框中输入内容
el = driver.find_element_by_id('kw')
el.send_keys('selenium')
# 清空操作
time.sleep(5)
el.clear()
# 再次输入内容
el.send_keys('python')
# 提交数据,等同于click操作
el.submit()
time.sleep(5)
driver.close() # 关闭窗口
from selenium import webdriver
import time
# 获取浏览器对象
driver = webdriver.Firefox()
# 访问58同城租房网页
url = 'https://bj.58.com/chuzu/?PGTID=0d100000-0000-1efb-e60d-a376bad42316&ClickID=1'
driver.get(url)
# 定位一组元素并存储进列表
el_list = driver.find_elements_by_css_selector("li.house-cell > div:nth-child(2) > h2:nth-child(1) > a:nth-child(1)")
# 打印列表中每个元素的文本以及href属性值
for el in el_list:
print('标题:',el.text,'链接:',el.get_attribute('href'))
time.sleep(5)
driver.close() # 关闭窗口
